一.DRF之Jwt 实现自定义
二.DRF(过滤,排序,分页)组件
三.Django-filter插件的使用和自定义
""" 1、drf-jwt手动签发与校验 :只是做token的产生和提高效率 缓解服务器的压力 检验用户的的合法性(tokenbase64反解析) 2、drf小组件:过滤、筛选、排序、分页 => 针对与群查接口 """
一.drf-jwt手动签发与校验
事前准备工作
1.1url 获取token 用户登录成功就可以获取token
model
from django.db import models # Create your models here. # 重点: 如果我们自定义user表, 再另一个项目中采用原生的User表,完成数据库迁移时,可能会失败 #如何做*(1) 卸载Django 重新装 # (2) 将Djjango中的 contrib 下面的admin 下面的数据库迁移命令记录清空 from django.contrib.auth.models import AbstractUser class User(AbstractUser): #继承AbstractUuser) mobile = models.CharField(max_length=11,unique=True) # 自定义创建表名 class Meta: db_table = 'api_user' verbose_name = '用户表' verbose_name_plural = verbose_name def __str__(self): return self.username
admin
from django.contrib import admin from . import models # Register your models here. admin.site.register(models.User) admin.site.register(models.Car)
View
# 必须登录后才能访问 - 通过了认证权限组件 from rest_framework.permissions import IsAuthenticated # from rest_framework_jwt.authentication import JSONWebTokenAuthentication from utils.reponse import APIResponse from rest_framework.views import APIView # 自定义jwt校验规则 #实现多方式登陆签发token:账号、手机号、邮箱等登陆 # 1) 禁用认证与权限组件 # 2) 拿到前台登录信息,交给序列化类 # 3) 序列化类校验得到登录用户与token存放在序列化对象中 # 4) 取出登录用户与token返回给前台 from . import serializers, models from .authentications import JWTAuthenticate class LoginAPIView(APIView): # 1) 禁用认证与权限组件 authentication_classes = [] permission_classes = [] def post(self, request, *args, **kwargs): # 2) 拿到前台登录信息,交给序列化类,规则:账号用usr传,密码用pwd传 user_ser = serializers.UserModelSerializer(data=request.data) # 3) 序列化类校验得到登录用户与token存放在序列化对象中 user_ser.is_valid(raise_exception=True) # 4) 取出登录用户与token返回给前台 # return APIResponse(token=user_ser.token, results=serializers.UserModelSerializer(user_ser.user).data) def get(self, request, *args, **kwargs): authentication_classes = [JWTAuthenticate] permission_classes = [IsAuthenticated] print(request.user) return APIResponse(1,'ok',results=request.user.username)
第一个测试是我们是直接找的路由 提供用户名和密码 直接生成token
url(r'^login/', views.LoginAPIView.as_view())
第二测验是通过现有的用户名 usr ='admin' paw = "admin123"
通过serializer 检验能过 后 user >>> payload >>> 生成token
View
from . import serializers, models from .authentications import JWTAuthenticate class LoginAPIView(APIView): # 1) 禁用认证与权限组件 authentication_classes = [] # 登录时禁用 不能阻拦 permission_classes = [] def post(self, request, *args, **kwargs): # 2) 拿到前台登录信息,交给序列化类,规则:账号用usr传,密码用pwd传 user_ser = serializers.UserModelSerializer(data=request.data) # 3) 序列化类校验得到登录用户与token存放在序列化对象中 user_ser.is_valid(raise_exception=True) # 4) 取出登录用户与token返回给前台 # return APIResponse(token=user_ser.token, results=serializers.UserModelSerializer(user_ser.user).data)
serializer >>> 检验字段 钩子函数 >>> jwt 生成token
import re from rest_framework import serializers from rest_framework_jwt.serializers import jwt_payload_handler from rest_framework_jwt.serializers import jwt_encode_handler from . import models # 拿到前台token的两个函数: user >>>payload>>>token # 自定义序列化 和反序列化类 class UserModelSerializer(serializers.ModelSerializer): # 自定义反序列化字段:必须设置只参与发你序列化的(write_only)字段 序列化不会与model映射 只写写自己返回的字段 usr = serializers.CharField(write_only=True) pwd = serializers.CharField(write_only=True) # 只写字段放在下面也可 class Meta: model = models.User fields = ['usr', 'pwd','email','mobile','username'] extra_kwargs = { 'username': { 'read_only': True }, 'mobile': {'read_only': True }, 'email': { 'read_only': True } } # 局部钩子和全局钩子 看情况进行 使用 多的就用全局 def validate(self, attrs): usr = attrs.get('usr') pwd = attrs.get('pwd') # 多种方式进行登录 请求的有手机 邮箱 用户名等登录方式 if re.match(r'.+@.+', usr): user_query = models.User.objects.filter(email=usr) elif re.match(r'^1[3-9][0-9]{9}$', usr): user_query = models.User.objects.filter(mobile=usr) else: user_query = models.User.objects.filter(username=usr) # 获取对 user_obj = user_query.first() # print(user_obj, 333) # 签发token :得到用户的登录,签发token并存储在实列化对象中 # 判断是否有用户和密码是否正确 if user_obj and user_obj.check_password(pwd): # 将产生的token 放到我们实列化对象中 # (1) user_obj >>> payload >>>token payload = jwt_payload_handler(user_obj) # JWT_PAYLOAD_HANDLER token = jwt_encode_handler(payload) # 将当前的用户和签发的token 保存到实列化的 对象中 self.user = user_obj self.token = token print(self.token) return attrs # 异常 raise serializers.ValidationError({'data':'数据有误'}) # 汽车的群查序列化基本的数据和字段的操作 # 很简单的直接的序列化 class CarModelSerializer(serializers.ModelSerializer): # 自定义返回字段 class Meta: model = models.Car fields = ['name', 'price', 'brand']
2.1. 检验token token的自定义(改源码)
View的代码是检验用户是否可以进行其他操作 (订单类的服务:查看,提交)
进行检验和判断用户是否登录 进行 返回信息
authenticate 文件下
# 导包 import jwt from rest_framework_jwt.authentication import BaseJSONWebTokenAuthentication from rest_framework.exceptions import AuthenticationFailed from rest_framework_jwt.authentication import jwt_decode_handler # 自定义检测检验规则: auth token jwt class JWTAuthenticate(BaseJSONWebTokenAuthentication): def authenticate(self, request): # 发送的token 反爬虫的思路 jwt_token = request.META.get('HTTP_AUTHORIZATION') print(jwt_token,1) print(request.META,2) # 自定义检验 auth token jwt token = self.parse_jwt_token(jwt_token) if token is None: return None # 反解 通过 token >>>payload >>> user 确认登录 try: payload = jwt_decode_handler(token) except jwt.ExpiredSignature: raise AuthenticationFailed('TOKEN已过期') except: raise AuthenticationFailed('非法用户') user = self.authenticate_credentials(payload) return (user, token) # 自定义校验规则:auth token jwt.auth为自定义前言,jwt为后盐 def parse_jwt_token(self, jwt_token): token = jwt_token.split() if len(token) != 3 or token[0].lower() != 'auth' or token[2].lower() != 'jwt': return None return token[1]
补充:
from django.contrib import admin from . import models # 自定义User表,admin后台管理,采用密文密码 from django.contrib.auth.admin import UserAdmin class MyUserAdmin(UserAdmin): add_fieldsets = ( (None, { 'classes': ('wide',), 'fields': ('username', 'password1', 'password2', 'mobile', 'email'), }), ) admin.site.register(models.User, MyUserAdmin)
二.DRF(过滤,排序,分页)组件
2.1搜索过滤组件
model
# drf 群查接口model表 class Car(models.Model): name = models.CharField(max_length=16, verbose_name='车名') price = models.DecimalField(max_digits=8, decimal_places=2,verbose_name='价格') brand = models.CharField(max_length=16,verbose_name='品牌') class Meta: verbose_name = '汽车表' verbose_name_plural = verbose_name def __str__(self): return self.name
源码分析的流程
seializer
# 汽车的群查序列化基本的数据和字段的操作 # 很简单的直接的序列化 class CarModelSerializer(serializers.ModelSerializer): # 自定义返回字段 class Meta: model = models.Car fields = ['name', 'price', 'brand']
filter_backends 过滤的组件
""" 源码 def filter_queryset(self, request, queryset, view): search_fields = self.get_search_fields(view, request) search_terms = self.get_search_terms(request)
URL
# 路由分发 from django.conf.urls import url from api import views from rest_framework_jwt.views import ObtainJSONWebToken,obtain_jwt_token # 登录签发token(生成) urlpatterns = [ url(r'^jlogin/', ObtainJSONWebToken.as_view()), url(r'^login/', views.LoginAPIView.as_view()), url(r'^cars/', views.CarsListApiView.as_view()), ]
View
# drf restframework # 群查接口 # model >>>路由 >>> 视图 >>> serializes(序列化和反序列化) from api.serializers import CarModelSerializer # 群查的接口就是 >>>>搜素组件 from rest_framework.generics import ListAPIView, ListCreateAPIView # (1)搜索查询 关键字searchFilter from rest_framework.filters import SearchFilter class CarsListApiView(ListCreateAPIView): # # 获取序列化(查询的对象) get 请求 # def get(self, request, *agrs, **kwargs): queryset = models.Car.objects.all() # 我们继承ListAPIView 里面是五大工具类继承 六大方法 就是我们再也不需要进行写我们的get post patch list update create # print(queryset) serializer_class = serializers.CarModelSerializer # # 我们需要两个参数 # queryset = None 序列化 需要我们 第一个参数:queryset() 数据库的数据对象 # serializer_class = None # 第二个 是我们的将序列化 对象赋值给serializer_class = serializer.CarModelSerializer() # print(serializer_class) # return APIResponse(1,'OK',results=queryset) # (1) search 搜查 # 类似与一个api.settings 也是全局的配置和局部的配置 # 在函数内属于局部的配置 """ 源码 def filter_queryset(self, request, queryset, view): search_fields = self.get_search_fields(view, request) search_terms = self.get_search_terms(request) """ """ for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset """ # 搜索过滤查询依赖的条件 >>>接口cars?search=1/宝马等 # backends 后端 后头 进我们的过滤条件加我到我们的;列表中 filter_backends = [SearchFilter] # search_fields = ['name', 'price']
Postman的配置
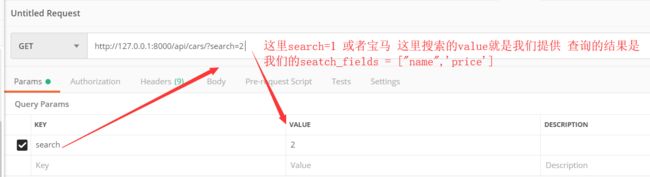
api/cars/后面不加添加其他查询all
如何实现自定义的过滤
2.2排序过滤组件
# drf restframework # 群查接口 # model >>>路由 >>> 视图 >>> serializes(序列化和反序列化) from api.serializers import CarModelSerializer # 群查的接口就是 >>>>搜素组件 from rest_framework.generics import ListAPIView, ListCreateAPIView # (1)搜索查询 关键字searchFilter from rest_framework.filters import SearchFilter # (2) 排序过滤组件 drf 的Ordering from rest_framework.filters import OrderingFilter class CarsListApiView(ListCreateAPIView): # # 获取序列化(查询的对象) get 请求 # def get(self, request, *agrs, **kwargs): queryset = models.Car.objects.all() # 我们继承ListAPIView 里面是五大工具类继承 六大方法 就是我们再也不需要进行写我们的get post patch list update create # print(queryset) serializer_class = serializers.CarModelSerializer # # 我们需要两个参数 # queryset = None 序列化 需要我们 第一个参数:queryset() 数据库的数据对象 # serializer_class = None # 第二个 是我们的将序列化 对象赋值给serializer_class = serializer.CarModelSerializer() # print(serializer_class) # return APIResponse(1,'OK',results=queryset) # (1) search 搜查 # 类似与一个api.settings 也是全局的配置和局部的配置 # 在函数内属于局部的配置 """ 源码 def filter_queryset(self, request, queryset, view): search_fields = self.get_search_fields(view, request) search_terms = self.get_search_terms(request) """ """ for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset """ # 搜索过滤查询依赖的条件 >>>接口cars?search=1/宝马等 # backends 后端 后头 进我们的过滤条件加我到我们的;列表中 # filter_backends = [SearchFilter] # # # search_fields = ['name','price'] # 添加过滤的类 filter_backends = [SearchFilter,OrderingFilter] # 筛选的字段 ordering_fields = ['pk','price']
2.3 分页
1.1我们依然的用的同一个接口
Pagenation 文件代码
# drf 基础的分页组件 from rest_framework.pagination import PageNumberPagination # 自定义分页的规则 class MyPageNumberPagination(PageNumberPagination): # ?page = 页码 page_queryset_param = 'page' # ?page=页面下默认的一页显示的条数 page_size = 3 # 用户可以自定义显示的页面的条数 page_size_query_param = 'page_size' # 一个页面显示的最大的限制的条数
max_page_size = 5
VIew视图代码
# 必须登录后才能访问 - 通过了认证权限组件 from rest_framework.permissions import IsAuthenticated # from rest_framework_jwt.authentication import JSONWebTokenAuthentication from utils.reponse import APIResponse from rest_framework.views import APIView # 自定义jwt校验规则 #实现多方式登陆签发token:账号、手机号、邮箱等登陆 # 1) 禁用认证与权限组件 # 2) 拿到前台登录信息,交给序列化类 # 3) 序列化类校验得到登录用户与token存放在序列化对象中 # 4) 取出登录用户与token返回给前台 from . import serializers, models from .authentications import JWTAuthenticate class LoginAPIView(APIView): # # 1) 禁用认证与权限组件 # authentication_classes = [] # 登录时禁用 不能阻拦 # permission_classes = [] # # def post(self, request, *args, **kwargs): # # 2) 拿到前台登录信息,交给序列化类,规则:账号用usr传,密码用pwd传 # user_ser = serializers.UserModelSerializer(data=request.data) # # 3) 序列化类校验得到登录用户与token存放在序列化对象中 # user_ser.is_valid(raise_exception=True) # # 4) 取出登录用户与token返回给前台 # # # return APIResponse(token=user_ser.token, results=serializers.UserModelSerializer(user_ser.user).data) def get(self, request, *args, **kwargs): authentication_classes = [JWTAuthenticate] permission_classes = [IsAuthenticated] print(request.user,3334) return APIResponse(1,'ok',results=request.user.username) # drf restframework # 群查接口 # model >>>路由 >>> 视图 >>> serializes(序列化和反序列化) from api.serializers import CarModelSerializer # 群查的接口就是 >>>>搜素组件 from rest_framework.generics import ListAPIView, ListCreateAPIView # (1)搜索查询 关键字searchFilter from rest_framework.filters import SearchFilter # (2) 排序过滤组件 drf 的Ordering from rest_framework.filters import OrderingFilter class CarsListApiView(ListCreateAPIView): # # 获取序列化(查询的对象) get 请求 # def get(self, request, *agrs, **kwargs): queryset = models.Car.objects.all() # 我们继承ListAPIView 里面是五大工具类继承 六大方法 就是我们再也不需要进行写我们的get post patch list update create # print(queryset) serializer_class = serializers.CarModelSerializer # # 我们需要两个参数 # queryset = None 序列化 需要我们 第一个参数:queryset() 数据库的数据对象 # serializer_class = None # 第二个 是我们的将序列化 对象赋值给serializer_class = serializer.CarModelSerializer() # print(serializer_class) # return APIResponse(1,'OK',results=queryset) # (1) search 搜查 # 类似与一个api.settings 也是全局的配置和局部的配置 # 在函数内属于局部的配置 """ 源码 def filter_queryset(self, request, queryset, view): search_fields = self.get_search_fields(view, request) search_terms = self.get_search_terms(request) """ """ for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset """ # 搜索过滤查询依赖的条件 >>>接口cars?search=1/宝马等 # backends 后端 后头 进我们的过滤条件加我到我们的;列表中 # filter_backends = [SearchFilter, OrderingFilter] # search_fields = ['name','price'] # 添加过滤的类 # 筛选的字段 # ordering_fields = ['pk','price'] from api.pahenations import MyPageNumberPagination # 分页组件 - 给视图类配置分页类需要自定义 继承drf提供的分页类即可 pagination_class = MyPageNumberPagination
2.4 drf偏移分页组件
View 视图
# 群查的接口就是 >>>>搜素组件 from rest_framework.generics import ListAPIView, ListCreateAPIView # (1)搜索查询 关键字searchFilter from rest_framework.filters import SearchFilter # (2) 排序过滤组件 drf 的Ordering from rest_framework.filters import OrderingFilter class CarsListApiView(ListCreateAPIView): # # 获取序列化(查询的对象) get 请求 # def get(self, request, *agrs, **kwargs): queryset = models.Car.objects.all() # 我们继承ListAPIView 里面是五大工具类继承 六大方法 就是我们再也不需要进行写我们的get post patch list update create # print(queryset) serializer_class = serializers.CarModelSerializer # # 我们需要两个参数
pagenations
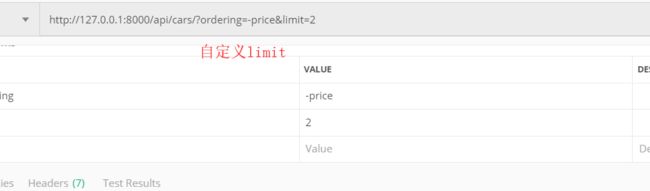
# drf 基础的分页组件 # from rest_framework.pagination import PageNumberPagination # (2)drf偏移分页组件 from rest_framework.pagination import LimitOffsetPagination # 自定义分页的规则 class MyLimitOffsetPagination(LimitOffsetPagination): # # ?page = 页码 # page_queryset_param = 'page' # # ?page=页面下默认的一页显示的条数 # # page_size = 3 # # 用户可以自定义显示的页面的条数 # # page_size_query_param = 'page_size' # # # 一个页面显示的最大的限制的条数 # max_page_size = 5 # (2)drf偏移分页组件 # ?offset=从头偏移 的条数 $ limit=我们要显示的条数 limit_query = 'limit' offset_query_param = 'offset' # 不传offset和limit 默认显示前3条 只设置offset的化就是从偏移位置在往后显示几条 default_limit = 3 # 默认 max_limit = 5 # 最多显示的条数 # ?ordering= -price$limit=2 >>>展示价格前2条
offset
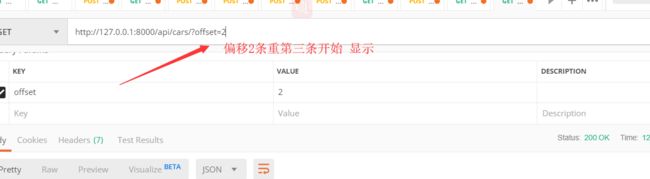
结合ordering 使用
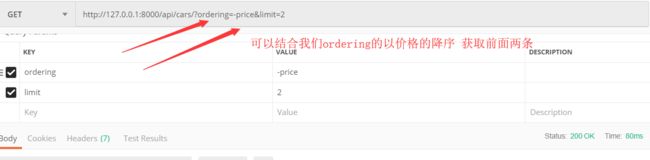
2.5 drf 游标分页组件(了解)
## drf游标分页组件(了解) ##### pahenations.py ```python # 注:必须基于排序规则下进行分页 # 1)如果接口配置了OrderingFilter过滤器,那么url中必须传ordering # 1)如果接口没有配置OrderingFilter过滤器,一定要在分页类中声明ordering按某个字段进行默认排序 from rest_framework.pagination import CursorPagination class MyCursorPagination(CursorPagination): cursor_query_param = 'cursor' page_size = 3 page_size_query_param = 'page_size' max_page_size = 5 ordering = '-pk' ``` ##### views.py ```python from rest_framework.generics import ListAPIView class CarListAPIView(ListAPIView): # 如果queryset没有过滤条件,就必须 .all(),不然分页会出问题 queryset = models.Car.objects.all() serializer_class = serializers.CarModelSerializer # 分页组件 - 给视图类配置分页类即可 - 分页类需要自定义,继承drf提供的分页类即可 pagination_class = pagenations.MyCursorPagination ```
2.6 自定义分页组件
filter 文件中重开一个‘
# 自定义过滤器 接口:?limit=显示条数 class LimitFilter: def filter_queryset(self,request, queryset,view): # 前台固定用 ?limit=...传递过滤参数 limit = request.query_params.get('limit') if limit: limit = int(limit) return queryset[:limit] # 进行切片 return queryset
View中
# 群查的接口就是 >>>>搜素组件 from rest_framework.generics import ListAPIView, ListCreateAPIView # (1)搜索查询 关键字searchFilter from rest_framework.filters import SearchFilter # (2) 排序过滤组件 drf 的Ordering from rest_framework.filters import OrderingFilter class CarsListApiView(ListCreateAPIView): # # 获取序列化(查询的对象) get 请求 # def get(self, request, *agrs, **kwargs): queryset = models.Car.objects.all() # 我们继承ListAPIView 里面是五大工具类继承 六大方法 就是我们再也不需要进行写我们的get post patch list update create # print(queryset) serializer_class = serializers.CarModelSerializer # # 我们需要两个参数 # queryset = None 序列化 需要我们 第一个参数:queryset() 数据库的数据对象 # serializer_class = None # 第二个 是我们的将序列化 对象赋值给serializer_class = serializer.CarModelSerializer() # print(serializer_class) # return APIResponse(1,'OK',results=queryset) # (1) search 搜查 # 类似与一个api.settings 也是全局的配置和局部的配置 # 在函数内属于局部的配置 """ 源码 def filter_queryset(self, request, queryset, view): search_fields = self.get_search_fields(view, request) search_terms = self.get_search_terms(request) """ """ for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset """ # 搜索过滤查询依赖的条件 >>>接口cars?search=1/宝马等 # backends 后端 后头 进我们的过滤条件加我到我们的;列表中 from . filters import LimitFilter filter_backends = [SearchFilter, OrderingFilter, LimitFilter] # search_fields = ['name','price'] # 添加过滤的类 # 筛选的字段 ordering_fields = ['pk','price'] # from api.pahenations import MyLimitOffsetPagination # pagination_class = MyLimitOffsetPagination
三.Django-filter插件的使用和自定义
# 下载 django -filter
# 直接安装
D:\day74_djproj>pip install django-filter
# 怎么样写>>>使用自定义
# View 视图层
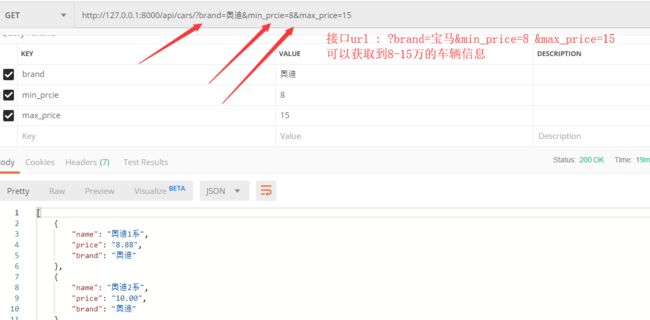
# 群查的接口就是 >>>>搜素组件 from rest_framework.generics import ListAPIView, ListCreateAPIView # (1)搜索查询 关键字searchFilter from rest_framework.filters import SearchFilter # (2) 排序过滤组件 drf 的Ordering from rest_framework.filters import OrderingFilter class CarsListApiView(ListCreateAPIView): # # 获取序列化(查询的对象) get 请求 # def get(self, request, *agrs, **kwargs): queryset = models.Car.objects.all() # 我们继承ListAPIView 里面是五大工具类继承 六大方法 就是我们再也不需要进行写我们的get post patch list update create # print(queryset) serializer_class = serializers.CarModelSerializer # # 我们需要两个参数 # queryset = None 序列化 需要我们 第一个参数:queryset() 数据库的数据对象 # serializer_class = None # 第二个 是我们的将序列化 对象赋值给serializer_class = serializer.CarModelSerializer() # print(serializer_class) # return APIResponse(1,'OK',results=queryset) # (1) search 搜查 # 类似与一个api.settings 也是全局的配置和局部的配置 # 在函数内属于局部的配置 """ 源码 def filter_queryset(self, request, queryset, view): search_fields = self.get_search_fields(view, request) search_terms = self.get_search_terms(request) """ """ for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset """ # 搜索过滤查询依赖的条件 >>>接口cars?search=1/宝马等 # backends 后端 后头 进我们的过滤条件加我到我们的;列表中 # filter_backends = [SearchFilter, OrderingFilter, LimitFilter] # search_fields = ['name','price'] # 添加过滤的类 # 筛选的字段 ordering_fields = ['pk','price'] # from api.pahenations import MyLimitOffsetPagination # pagination_class = MyLimitOffsetPagination # 视图层: from django_filters.rest_framework import DjangoFilterBackend from .filter import CarFilter # 局部配置 过滤类们(全局配置的话就用DEFAULT_FILTER_BACKENDS) filter_backends = [DjangoFilterBackend] # django-filter过滤器插件使用 filter_class = CarFilter # 接口: ? brand=...&min_price...&max_price.... # ru ?brand=宝马&min_price=12&min_price=15
filter文件的代码
# django-filter 插件过滤器类 from django_filters.rest_framework import FilterSet from . import models # 自定义过滤字段 from django_filters import filters class CarFilter(FilterSet): min_price = filters.NumberFilter(field_name='price', lookup_expr='gte') max_price = filters.NumberFilter(field_name='price', lookup_expr='lte') class Meta: model = models.Car fields = ['brand', 'min_price', 'max_price'] # brand是model中存在的字段,一般都是可以用于分组的字段 # min_price、max_price是自定义字段,需要自己自定义过滤条件
如图:
===待改进....