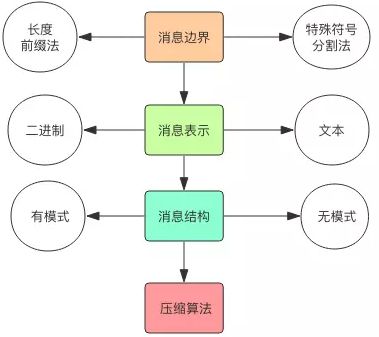
基本功:消息协议
消息是信息交换的主体,简单的讲,就是两个进程约定一个协议格式。消息表示指的是序列化后的消息字节流在直观上的表现形式,它看起来是对人类友好还是对计算机友好。文本形式对人类友好,二进制形式对计算机友好。每个消息都有其内部字段结构,结构构成了消息内部的逻辑规则,程序要按照结构规则来决定字段序列化的顺序。接下来将带你了解 RPC 的消息协议背后有哪些需要考虑的基本点。
目录
1. 消息边界
1.1 特殊分割符法
1.2 长度前缀法
2. 消息表示
2.1 文本消息
2.2 二进制消息
2.3 序列化协议考虑的因素
2.4 混合模式-HTTP 协议
3. 消息的结构
4. 消息压缩
消息协议的基本原理
1. 消息边界
RPC 需要在一条 TCP 链接上进行多次消息传递。基于 TCP 链接之上的单条消息如果过大,就会被网络协议栈拆分为多个数据包进行传送。如果消息过小,网络协议栈可能会将多个消息组合成一个数据包进行发送。
问题:对于接收端来说它看到的只是一串串的字节数组,如果没有明确的消息边界规则,接收端是无从知道这一串字节数组究竟是包含多条消息还是只是某条消息的一部分?
比较常用的两种分割方式是特殊分割符法和长度前缀法。
1.1 特殊分割符法
消息发送端在每条消息的末尾追加一个特殊的分割符,并且保证消息中间的数据不能包含特殊分割符。比如最为常见的分割符是\r\n。当接收端遍历字节数组时发现了\r\n,就立即可以断定\r\n 之前的字节数组是一条完整的消息。HTTP 和 Redis 协议就大量使用了\r\n 分割符。此种消息一般要求消息体的内容是文本消息。
优点
消息的可读性比较强,可以直接看到消息的文本内容。
缺点
不适合传递二进制消息,因为二进制的字节数组里面很容易就冒出连续的两个字节内容正好就是\r\n 分割符的 ascii 值。如果需要传递的话,一般是对二进制进行 base64 编码转变成普通文本消息再进行传送。
1.2 长度前缀法
消息发送端在每条消息的开头增加一个 4 字节长度的整数值,标记消息体的长度。这样消息接受者首先读取到长度信息,然后再读取相应长度的字节数组就可以将一个完整的消息分离出来。此种消息比较常用于二进制消息。
基于长度前缀法的优点和缺点同特殊分割符法正好是相反的。长度前缀法因为适用于二进制协议,所以可读性很差。但是对传递的内容本身没有特殊限制,文本和内容皆可以传输,不需要进行特殊处理。HTTP 协议的 Content-Length 头信息用来标记消息体的长度,这个也可以看成是长度前缀法的一种应用。
2. 消息表示
二进制消息和文本消息的表示方式就是我们熟悉的序列化反序列化。
使用“对象”来进行数据的操纵:
class User{
std::String user_name;
uint64_t user_id;
uint32_t user_age;
};User u = new User(“shenjian”);
u.setUid(123);
u.setAge(35);
但当需要对数据进行存储或者传输时,“对象”就不这么好用了,往往需要把数据转化成连续空间的“二进制字节流”,一些典型的场景是:
- 数据库索引的磁盘存储:数据库的索引在内存里是b+树,但这个格式是不能够直接存储到磁盘上的,所以需要把b+树转化为连续空间的二进制字节流,才能存储到磁盘上
- 缓存的KV存储:redis/memcache是KV类型的缓存,缓存存储的value必须是连续空间的二进制字节流,而不能够是User对象
- 数据的网络传输:socket发送的数据必须是连续空间的二进制字节流,也不能是对象
所谓序列化(Serialization),就是将“对象”形态的数据转化为“连续空间二进制字节流”形态数据的过程。这个过程的逆过程叫做反序列化。
这是一个非常细节的问题,要是让你来把“对象”转化为字节流,你会怎么做?
2.1 文本消息
很容易想到的就是xml(或者json)这类具有自描述特性的标记性语言:规定好转换规则,发送方很容易把User类的一个对象序列化为xml进行信息的交换
2.2 二进制消息
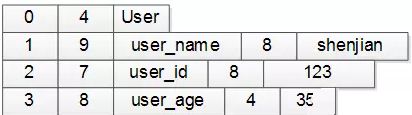
以上面的User对象为例,你可以设计一个二进制消息方式来进行序列化:整个二进制字节流共12+29+27+24=92字节。
-
第一行:序号4个字节(设0表示类名),类名长度4个字节(长度为4),接下来4个字节是类名(”User”),共12字节
-
第二行:序号4个字节(1表示第一个属性),属性长度4个字节(长度为9),接下来9个字节是属性名(”user_name”),属性值长度4个字节(长度为8),属性值8个字节(值为”shenjian”),共29字节
-
第三行:序号4个字节(2表示第二个属性),属性长度4个字节(长度为7),接下来7个字节是属性名(”user_id”),属性值长度4个字节(长度为8),属性值8个字节(值为123),共27字节
-
第四行:序号4个字节(3表示第三个属性),属性长度4个字节(长度为8),接下来8个字节是属性名(”user_name”),属性值长度4个字节(长度为4),属性值4个字节(值为35),共24字节
实际的序列化协议要考虑的细节远比这个多,例如:强类型的语言不仅要还原属性名,属性值,还要还原属性类型;复杂的对象不仅要考虑普通类型,还要考虑对象嵌套类型等。无论如何,序列化的思路都是类似的。
2.3 序列化协议考虑的因素
不管使用成熟协议xml/json,还是自定义二进制协议来序列化对象,序列化协议设计时都需要考虑以下这些因素。
-
解析效率:这个应该是序列化协议应该首要考虑的因素,像xml/json解析起来比较耗时,需要解析doom树,二进制自定义协议解析起来效率就很高
-
压缩率,传输有效性:同样一个对象,xml/json传输起来有大量的xml标签,信息有效性低,二进制自定义协议占用的空间相对来说就小多了
-
扩展性与兼容性:是否能够方便的增加字段,增加字段后旧版客户端是否需要强制升级,都是需要考虑的问题,xml/json和上面的二进制协议都能够方便的扩展
-
可读性与可调试性:这个很好理解,xml/json的可读性就比二进制协议好很多
-
跨语言:上面的两个协议都是跨语言的,有些序列化协议是与开发语言紧密相关的,例如dubbo的序列化协议就只能支持Java的RPC调用
-
通用性:xml/json非常通用,都有很好的第三方解析库,各个语言解析起来都十分方便,上面自定义的二进制协议虽然能够跨语言,但每个语言都要写一个简易的协议客户端
有哪些常见的序列化方式?
-
xml/json:解析效率,压缩率都较差,扩展性、可读性、通用性较好
-
thrift
-
protobuf:Google出品,必属精品,各方面都不错,强烈推荐,属于二进制协议,可读性差了点,但也有类似的to-string协议帮助调试问题
-
Avro
-
CORBA
2.4 混合模式-HTTP 协议
HTTP 协议是一种基于特殊分割符和长度前缀法的混合型协议。比如 HTTP 的消息头采用的是纯文本外加\r\n 分割符,而消息体则是通过消息头中的 Content-Type 的值来决定长度。HTTP 协议虽然被称之为文本传输协议,但是也可以在消息体中传输二进制数据数据的,例如音视频图像,所以 HTTP 协议被称之为「超文本」传输协议。
3. 消息的结构
每条消息都有它包含的语义结构信息,有些消息协议的结构信息是显式的,还有些是隐式的。
显式
比如 json 消息,它的结构就可以直接通过它的内容体现出来,所以它是一种显式结构的消息协议。json 这种直观的消息协议的可读性非常棒,但是它的缺点也很明显,有太多的冗余信息。
隐式
消息的隐式结构一般是指那些结构信息由代码来约定的消息协议,在 RPC 交互的消息数据中只是纯粹的二进制数据,由代码来确定相应位置的二进制是属于哪个字段。
消息的结构在同一条消息通道上是可以复用的,比如在建立链接的开始 RPC 客户端和服务器之间先交流协商一下消息的结构,后续发送消息时只需要发送一系列消息的 value 值,接收端会自动将 value 值和相应位置的 key 关联起来,形成一个完成的结构消息。在 Hadoop 系统中广泛使用的 avro 消息协议就是通过这种方式实现的,在 RPC 链接建立之处就开始交流消息的结构,后续消息的传递就可以节省很多流量。
如果纯粹看消息内容是无法知道节点消息内容中的哪些字节的含义,它的消息结构是通过代码的结构顺序来确定的。这种隐式的消息的优点就在于节省传输流量,它完全不需要传输结构信息。
4. 消息压缩
如果消息的内容太大,就要考虑对消息进行压缩处理,这可以减轻网络带宽压力。但是这同时也会加重 CPU 的负担,因为压缩算法是 CPU 计算密集型操作,会导致操作系统的负载加重。所以,最终是否进行消息压缩,一定要根据业务情况加以权衡。
更多关于压缩之前也讲过。