例3:计算器—double类型加法
下面我们对上个例子的代码进行进一步的修改,使得代码具有简单的四则运算的功能。
第一步修改,我们将打印出每一行的值,使得计算器更具交互性。一开始,我们只是把数字加起来,然后再关注其他运算,比如减法、乘法和除法。
1.Options和class声明块
描述文件calculator0.jj的第一部分如下所示:
/* calculator0.jj An interactive calculator. */
options {
STATIC = false ;
}
PARSER_BEGIN(Calculator)
import java.io.PrintStream ;
class Calculator {
public static void main( String[] args )
throws ParseException, TokenMgrError, NumberFormatException {
Calculator parser = new Calculator( System.in ) ;
parser.Start( System.out ) ;
}
double previousValue = 0.0 ;
}
PARSER_END(Calculator)Calculator类中的previousValue属性,用于存储上一行的计算结果的,我们将在另一个版本中使用到该值,到时可以使用美元符号来表示它。import导入语句声明说明了在PARSER_BEGIN和PARSER_END之间可能有import导入声明;这些代码都会被原样复制到生成的语法解析类和token管理类中去。同样还可以有包package的声明,package的声明将会被复制到最后生成的所有java类中去。
2.词法描述文件
词法分析器的描述文件在这里将会发生一些变化,首先一行的结束符也被声明为了token,并给这些行结束符命名为EOL,这样一来这个token也可以被传递给语法分析器了。
SKIP : { " " }
TOKEN : { < EOL : "\n" | "\r" | "\r\n" > }
TOKEN : { < PLUS : "+" > }接下来,我们要定义合适的token使得允许输入中的数值有小数点。为此我们修改NUMBER这个token的定义,使得它可以识别decimal类型的数值。当数值中有小数点,它可以有如下的4中类型,我们分别用竖线分隔开来了,这4中类型分别是:整型,没有小数点、小数点在中间、小数点在末尾和小数点在开头。满足此需求的描述串如下:
TOKEN { < NUMBER : (["0"-"9"])+
| (["0"-"9"])+ "." (["0"-"9"])+
| (["0"-"9"])+ "."
| "." (["0"-"9"])+ >
}有时候,同样的规则表达式可能会出现多次。为了更好的可读性,最好是给这些重复出现的表达式起一个名字。对于那些只在词法描述文件中使用到,但又不是token的规则表达式,我们创建了一个特殊的标识来表示它:#。因此,对于上面的词法描述,可以替换成如下:
TOKEN : { < NUMBER :
| "."
| "."
| "." >
}
TOKEN : { < #DIGITS : (["0"-"9"])+ > } 可以看到,我们把([”0”-”9”])+这串规则表达式提取了出来,并将其命名为了DIGITS。但是要注意到,DIGITS这个并不是token,这意味着在后面生成的Token类中,将不会有DIGITS对应的属性,而在语法分析器中也无法使用DIGITS。
3.语法描述文件
语法分析器的输入由零行或多行组成。每行包含一个表达式。通过使用BNF符号表达式,语法分析器可以写成如下:
Start -->(Expression EOL) * EOF由此我们可以得出BNF生产式如下:
void Start() :
{}
{
(
Expression()
)*
} 我们在上面的BNF生产式中填充上java代码,使得它具备接收入参、记录并打印每一行的计算结果:
void Start(PrintStream printStream) throws NumberFormatException :
{}
{
(
previousValue = Expression()
{ printStream.println( previousValue ) ; }
)*
} 每个表达式由一个或多个数字组成,这些数字目前用加号隔开。用BNF符号表达式如下:
Expression --> Primary(PLUS Primary)* 在这里的Primary,我们暂时用它来表示数值。
上面的BNF符号表达式用JavaCC表示出来如下所示:
double Expression() throws NumberFormatException : {
double i ;
double value ;
}
{
value = Primary()
(
i = Primary()
{ value += i ; }
)*
{ return value ; }
} 这个跟我们前面例子中的Start BNF生产式差不多,我们只是将数值的类型由int修改成了double类型而已。至于Primary(),跟上面例子也非常类似,它用BNF符号表达式来表示:
Primary --> NUMBERPrimary()对应的JavaCC描述文件其实也差不多,只不过在这里它是对double精度的数值进行的转换计算:
double Primary() throws NumberFormatException :
{
Token t ;
}
{
t =
{ return Double.parseDouble( t.image ) ; }
} 下面我们用BNF符号表达式将语法分析器的逻辑表示出来:
Start --> (Expression EOL) * EOF
Expression --> Primary (PLUS Primary)*
Primary --> NUMBER至此,我们就把calculator0.jj描述文件都修改完了,接下来可以跑几个例子进行测试。
4.测试
4.1 calculator0.jj
经过上面的修改,最后得到的.jj描述文件如下:
/* calculator0.jj An interactive calculator. */
options {
STATIC = false ;
}
PARSER_BEGIN(Calculator)
import java.io.PrintStream ;
class Calculator {
public static void main( String[] args )
throws ParseException, TokenMgrError, NumberFormatException {
Calculator parser = new Calculator( System.in ) ;
parser.Start( System.out ) ;
}
double previousValue = 0.0 ;
}
PARSER_END(Calculator)
SKIP : { " " }
TOKEN : { < EOL : "\n" | "\r" | "\r\n" > }
TOKEN : { < PLUS : "+" > }
TOKEN : { < NUMBER :
| "."
| "."
| "." >
}
TOKEN : { < #DIGITS : (["0"-"9"])+ > }
void Start(PrintStream printStream) throws NumberFormatException :
{}
{
(
previousValue = Expression()
{ printStream.println( previousValue ) ; }
)*
}
double Expression() throws NumberFormatException : {
double i ;
double value ;
}
{
value = Primary()
(
i = Primary()
{ value += i ; }
)*
{ return value ; }
}
double Primary() throws NumberFormatException :
{
Token t ;
}
{
t =
{ return Double.parseDouble( t.image ) ; }
} 4.2 运行
我们首先计算1+2,如下所示:
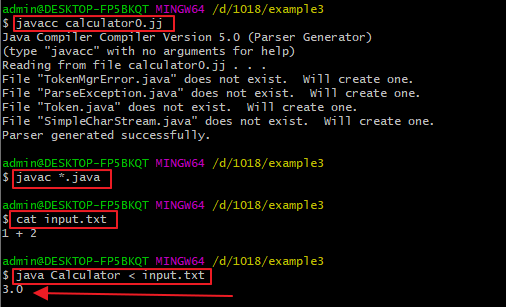
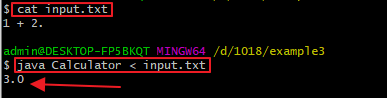
接下来计算1+2.,即小数点在末尾的情形:
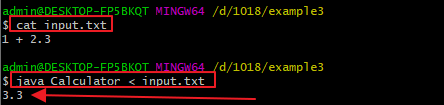
接下来计算1 + 2.3,即小数点在中间的情形:
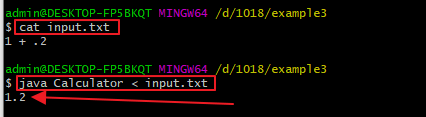
接下来计算1 + .2,即小数点在开头的情形: