在CentOS6.9搭建Spark2.4.0集群
一、环境
操作系统:CentOS6.9
软件版本:Spark2.4.0
集群架构:
master:10.200.4.117(oracle02)
worker1:10.200.4.116(oracle03)
worker2:10.100.125.156(db01)
集群已安装Hadoop2.6.5,现在需要安装Spark2.4.0。
二、搭建Spark集群
先在master(117服务器)安装配置好Spark后,再将安装目录拷贝到worker(116和156服务器)。
以下操作在master(117服务器)进行。
1、安装Spark
在浏览器输入下列网址来下载Spark:
https://spark.apache.org/downloads.html
选择2.4.0版本,对应Hadoop2.6版本,拷贝tgz文件下载链接地址后,使用wget下载。
在root用户使用wget命令下载安装文件:
wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.6.tgz

解压文件到安装目录:
tar -zxvf spark-2.4.0-bin-hadoop2.6.tgz -C /u01/app
更改Spark安装目录的所有者和组:(之前Hadoop安装在hadoop用户,归属hadoop组)
chown -R hadoop:hadoop /u01/app/spark-2.4.0-bin-hadoop2.6
2、配置环境变量
2.1 配置/etc/profile文件
在profile文件增加Spark环境变量:
vi /etc/profile
增加以下内容:
export SPARK_HOME=/u01/app/spark-2.4.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
使环境变量生效:
source /etc/profile
2.2 配置spark-env.sh文件
vi $SPARK_HOME/conf/spark-env.sh
增加以下内容:
#设置master的IP或服务器名称
export SPARK_MASTER_IP=10.200.4.117
#设置每个Worker使用的CPU核心
export SPARK_WORKER_CORES=8
#设置每个work使用的内存
export SPARK_WORKER_MEMORY=8g
#设置实例数
export SPARK_WORKER_INSTANCES=1
2.3 配置slaves文件
cd $SPARK_HOME/conf
cp slaves.template slaves
vi slaves
将最后一行的localhost修改成:
10.200.4.117
10.200.4.116
10.100.125.156
3、从master(117服务器)复制Spark安装目录到worker(116和156服务器)
以root用户登录worker(116和156服务器),分别创建Spark安装目录:
mkdir /u01/app/spark-2.4.0-bin-hadoop2.6
chown hadoop:hadoop /u01/app/spark-2.4.0-bin-hadoop2.6
以hadoop用户登录master(117服务器),复制Spark安装目录到worker(116和156服务器):
scp -r $SPARK_HOME [email protected]:/u01/app
scp -r $SPARK_HOME [email protected]:/u01/app
4、在worker(116和156服务器)配置/etc/profile文件
以root用户登录worker(116和156服务器),分别在profile文件增加Spark环境变量:
vi /etc/profile
增加以下内容:
export SPARK_HOME=/u01/app/spark-2.4.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
使环境变量生效:
source /etc/profile
5、启动和停止Spark
此操作只在master(117服务器)执行:
start-master.sh:启动master
start-slaves.sh:启动slaves
start-all.sh:同时启动master和slaves
stop-master.sh:停止master
stop-slaves.sh:停止slaves
stop-all.sh:同时停止master和slaves
因为Hadoop里面也有start-all.sh和stop-all.sh两个文件,为便于区分,在这里重新命名一下:
mv $SPARK_HOME/sbin/start-all.sh $SPARK_HOME/sbin/start-spark-all.sh
mv $SPARK_HOME/sbin/stop-all.sh $SPARK_HOME/sbin/stop-spark-all.sh
启动Spark:
start-spark-all.sh
启动后,查看master的jps,多出Master和Worker进程:
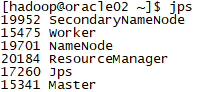
查看worker的jps,多出Worker进程:

6、查看管理界面
打开以下网址,访问Spark的WebUI界面:
http://10.200.4.117:8080/

完毕。