深度学习(二十)——Ultra Deep Network, 图像超分辨率算法
http://antkillerfarm.github.io/
Ultra Deep Network
FractalNet
论文:
《FractalNet: Ultra-Deep Neural Networks without Residuals》

Resnet in Resnet
论文:
《Resnet in Resnet: Generalizing Residual Architectures》

Highway
论文:
《Training Very Deep Networks》

Resnet对于残差的跨层传递是无条件的,而Highway则是有条件的。这种条件开关被称为gate,它也是由网络训练得到的。
DenseNet
DenseNet是康奈尔大学博士后黄高(Gao Huang)、清华大学本科生刘壮(Zhuang Liu)、Facebook人工智能研究院研究科学家Laurens van der Maaten 及康奈尔大学计算机系教授Kilian Q. Weinberger于2016年提出的。论文当选CVPR 2017最佳论文。
论文:
《Densely Connected Convolutional Networks》
代码:
https://github.com/liuzhuang13/DenseNet
原始版本是Torch写的,官网上列出了其他框架的实现代码的网址。
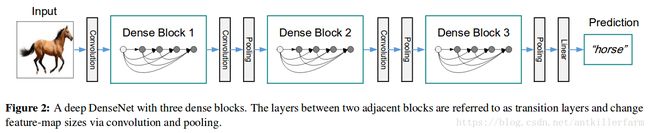
上图是DenseNet的整体网络结构图。从整体层面来看,DenseNet主要由3个dense block组成。

上图就是dense block的结构图。与Resnet的跨层加法不同,这里采用的是Concatenation,也就是将不同层的几个tensor组合成一个大的tensor。
这里的Concatenation是作用在channel上的,即dense block中的所有层的feature map都是等大的,只不过在channel数上,不仅包含本层生成的channel,还包含上层的channel。
这实际上带来了两个问题:
1.feature map的缩小问题。检测网络最后的FC是一定无法接收原始尺寸的feature map的。
2.channel数只增不减显然也是问题。
因此,在两个dense block之间,DenseNet还定义了一个transition layer。该layer包含两个操作:
1.1x1的conv用于降维。
2.avg pool用于缩小feature map。
DenseNet的设计思想
以下是原作者的访谈片段:
DenseNet的想法很大程度上源于我们去年发表在ECCV上的一个叫做随机深度网络(Deep networks with stochastic depth)工作。当时我们提出了一种类似于Dropout的方法来改进ResNet。我们发现在训练过程中的每一步都随机地“扔掉”(drop)一些层,可以显著的提高ResNet的泛化性能。这个方法的成功至少带给我们两点启发:
首先,它说明了神经网络其实并不一定要是一个递进层级结构,也就是说网络中的某一层可以不仅仅依赖于紧邻的上一层的特征,而可以依赖于更前面层学习的特征。想像一下在随机深度网络中,当第l层被扔掉之后,第l+1层就被直接连到了第l-1层;当第2到了第l层都被扔掉之后,第l+1层就直接用到了第1层的特征。因此,随机深度网络其实可以看成一个具有随机密集连接的DenseNet。
其次,我们在训练的过程中随机扔掉很多层也不会破坏算法的收敛,说明了ResNet具有比较明显的冗余性,网络中的每一层都只提取了很少的特征(即所谓的残差)。实际上,我们将训练好的ResNet随机的去掉几层,对网络的预测结果也不会产生太大的影响。既然每一层学习的特征这么少,能不能降低它的计算量来减小冗余呢?
DenseNet 的设计正是基于以上两点观察。我们让网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别“窄”,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。这两点也是DenseNet与其他网络最主要的不同。需要强调的是,第一点是第二点的前提,没有密集连接,我们是不可能把网络设计得太窄的,否则训练会出现欠拟合(under-fitting)现象,即使 ResNet 也是如此。
DenseNet的优点
省参数。在 ImageNet 分类数据集上达到同样的准确率,DenseNet 所需的参数量不到 ResNet 的一半。对于工业界而言,小模型可以显著地节省带宽,降低存储开销。
省计算。达到与 ResNet 相当的精度,DenseNet 所需的计算量也只有 ResNet 的一半左右。
**抗过拟合。**DenseNet 具有非常好的抗过拟合性能,尤其适合于训练数据相对匮乏的应用。这一点从论文中 DenseNet 在不做数据增强(data augmentation)的 CIFAR 数据集上的表现就能看出来。
由于DenseNet不容易过拟合,在数据集不是很大的时候表现尤其突出。在一些图像分割和物体检测的任务上,基于DenseNet的模型往往可以省略在ImageNet上的预训练,直接从随机初始化的模型开始训练,最终达到相同甚至更好的效果。由于在很多应用中实际数据跟预训练的ImageNet自然图像存在明显的差别,这种不需要预训练的方法在医学图像,卫星图像等任务上都具有非常广阔的应用前景。
DenseNet的优化问题
当前的深度学习框架对DenseNet的密集连接没有很好的支持,我们只能借助于反复的拼接(Concatenation)操作,将之前层的输出与当前层的输出拼接在一起,然后传给下一层。对于大多数框架(如Torch和TensorFlow),每次拼接操作都会开辟新的内存来保存拼接后的特征。这样就导致一个L层的网络,要消耗相当于L(L+1)/2层网络的内存(第l层的输出在内存里被存了(L-l+1)份)。
解决这个问题的思路其实并不难,我们只需要预先分配一块缓存,供网络中所有的拼接层(Concatenation Layer)共享使用,这样DenseNet对内存的消耗便从平方级别降到了线性级别。
参考
https://www.leiphone.com/news/201708/0MNOwwfvWiAu43WO.html
CVPR 2017最佳论文作者解读:DenseNet 的“what”、“why”和“how”
https://zhuanlan.zhihu.com/p/28124810
为什么ResNet和DenseNet可以这么深?一文详解残差块为何有助于解决梯度弥散问题
https://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2651988934&idx=2&sn=0e5ffa195ef67a1371f3b5b223519121
ResNets、HighwayNets、DenseNets:用TensorFlow实现超深度神经网络
Dual Path Networks
DPN是冯佳时和颜水成团队的Yunpeng Chen的作品。
冯佳时,中国科学技术大学自动化系学士,新加坡国立大学电子与计算机工程系博士。现任新加坡国立大学电子与计算机工程系助理教授。
论文:
《Dual Path Networks》
代码:
https://github.com/cypw/DPNs
这篇论文首先从拓扑关系的角度分析了ResNet、DenseNet和HORNN(Higher Order RNN)之间的联系。

如上所示,RNN相当于共享权值的串联的ResNet,而DenseNet则相当于并联的RNN。
更进一步的,上述三者都可表述为以下通式:
其中, ht h t 表示t时刻的隐层状态;索引k表示当前时刻; xt x t 表示t时刻的输入; fkt(⋅) f t k ( ⋅ ) 表示特征提取; gk g k 表示对提取特征做输出前的变换。
如果 fkt(⋅) f t k ( ⋅ ) 和 gk(⋅) g k ( ⋅ ) 每个Step都共享,那么就是HORNN,如果只有 fkt(⋅) f t k ( ⋅ ) 共享,那么就是ResNet,两者都不共享,那就是DenseNet。

上图展示的是ResNet和DenseNet的示意图。图中用线填充的柱状体,表示的是主干结点的tensor的大小。
ResNet由于跨层和主干之间是element-wise的加法运算,因此每个主干结点的tensor都是一样大的。
而DenseNet的跨层和主干之间是Concatenation运算,因此主干越往下,tensor越大。
通过上面的分析,我们可以认识到 :
ResNet: 侧重于特征的再利用,但不善于发掘新的特征;
DenseNet: 侧重于新特征的发掘,但又会产生很多冗余;
为了综合二者的优点,作者设计了DPN网络:

参考:
http://blog.csdn.net/scutlihaoyu/article/details/75645551
《Dual Path Networks》笔记
http://www.cnblogs.com/mrxsc/p/7693316.html
Dual Path Networks
http://blog.csdn.net/u014380165/article/details/75676216
DPN(Dual Path Network)算法详解
图像超分辨率算法

如上图所示,一张低分辨率的小图(Low Resolution,LR)如果采用简单的插值算法进行图片放大的话,图像中物体的边缘会比较模糊。如何用算法将这种LR的图片放大成HR的图片,这就是Super Resolution(SR)的目标了。
SR目前主要有两个用途:
1.提升设备的测量精度。这个在天文和医疗图像方面用的比较多,比如Google和NASA利用AI探测太阳系外的行星,还有癌症的早期诊断。
2.Image Signal Processor。上面的两个应用比较高端,SR最主要的用途恐怕还是相机的ISP领域。ISP的基本概念参见《图像处理理论(四)》。
这里主要讨论DL在SR领域的应用。