1. 下载MNIST数据
http://yann.lecun.com/exdb/mnist/
为每个图片都是 28*28 像素
2. 加载数据
import struct
import numpy as np
train_image_file="E:/workspace/PycharmProjects/MyHandsonML/train-images.idx3-ubyte"
train_label_file="E:/workspace/PycharmProjects/MyHandsonML/train-labels.idx1-ubyte"
test_image_file="E:/workspace/PycharmProjects/MyHandsonML/t10k-images.idx3-ubyte"
test_label_file="E:/workspace/PycharmProjects/MyHandsonML/t10k-labels.idx1-ubyte"
def decode_idx3_ubyte(file):
"""
解析idx3文件的通用函数
:param idx3_ubyte_file: idx3文件路径
:return: 数据集
"""
# 读取二进制数据
bin_data = open(file, 'rb').read()
# 解析文件头信息,依次为魔数、图片数量、每张图片高、每张图片宽
offset = 0
fmt_header = '>iiii'
magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, bin_data, offset)
print('魔数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))
# 解析数据集
image_size = num_rows * num_cols
offset += struct.calcsize(fmt_header)
fmt_image = '>' + str(image_size) + 'B'
images = np.empty((num_images, num_rows, num_cols))
for i in range(num_images):
if (i + 1) % 10000 == 0:
print('已解析 %d' % (i + 1) + '张')
images[i] = np.array(struct.unpack_from(fmt_image, bin_data, offset)).reshape((num_rows, num_cols))
offset += struct.calcsize(fmt_image)
return images
def decode_idx1_ubyte(file):
"""
解析idx1文件的通用函数
:param idx1_ubyte_file: idx1文件路径
:return: 数据集
"""
# 读取二进制数据
bin_data = open(file, 'rb').read()
# 解析文件头信息,依次为魔数和标签数
offset = 0
fmt_header = '>ii'
magic_number, num_images = struct.unpack_from(fmt_header, bin_data, offset)
print('魔数:%d, 图片数量: %d张' % (magic_number, num_images))
# 解析数据集
offset += struct.calcsize(fmt_header)
fmt_image = '>B'
labels = np.empty(num_images)
for i in range(num_images):
if (i + 1) % 10000 == 0:
print ('已解析 %d' % (i + 1) + '张')
labels[i] = struct.unpack_from(fmt_image, bin_data, offset)[0]
offset += struct.calcsize(fmt_image)
return labels
def load_train_images(file):
"""
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
:param idx_ubyte_file: idx文件路径
:return: n*row*col维np.array对象,n为图片数量
"""
return decode_idx3_ubyte(file)
def load_train_labels(file):
"""
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9.
:param idx_ubyte_file: idx文件路径
:return: n*1维np.array对象,n为图片数量
"""
return decode_idx1_ubyte(file)
def load_test_images(file):
"""
TEST SET IMAGE FILE (t10k-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 10000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
:param idx_ubyte_file: idx文件路径
:return: n*row*col维np.array对象,n为图片数量
"""
return decode_idx3_ubyte(file)
def load_test_labels(file):
"""
TEST SET LABEL FILE (t10k-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 10000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9.
:param idx_ubyte_file: idx文件路径
:return: n*1维np.array对象,n为图片数量
"""
return decode_idx1_ubyte(file)
def load_data():
train_images = load_train_images(train_image_file)
train_labels = load_train_labels(train_label_file)
test_images = load_test_images(test_image_file)
test_labels = load_test_labels(test_label_file)
X_train = train_images
X_test = test_images
y_train = train_labels
y_test = test_labels
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = load_data()
X_train.shape
# (60000, 28, 28)
y_train.shape
# (60000,)
X_train = X_train.reshape(-1, 28*28)
X_test = X_test.reshape(-1, 28*28)
看一看某一个数字
import matplotlib
import matplotlib.pyplot as plt
some_digit=X_train[30000]
plt.imshow(some_digit.reshape(28,28), cmap=matplotlib.cm.binary)
plt.axis("off")
plt.show()
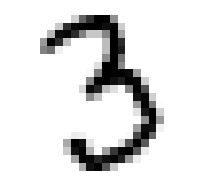
3. 训练一个二值分类器
先只尝试去识别一个数字,比如3
y_train_3 = (y_train == 3)
# 本来是3的全部变成true,其他的都是false
y_test_3 = (y_test == 3)
使用随机梯度下降分类器SGDClassifier
SGD主要应用在大规模稀疏数据问题上,经常用在文本分类及自然语言处理。假如数据是稀疏的,该模块的分类器可轻松解决如下问题:超过10^5 的训练样本、超过10^5 的features。利用梯度来求解参数。
SGDClassifier是一种通过SGD求解参数的线性分类器,如SVM,逻辑回归。数据的要求是均值为0,单位方差。
模型通过参数loss设置,默认是线性SVM(hinge),可以是逻辑回归(log)等。
- 优点:高效处理大数据集
- 注意:该算法依赖数据集的随机程度
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_3)
sgd_clf.predict([some_digit])
# array([ True]) 结果正确
专题:如何评估性能
交叉验证
'''
自己实现的交叉验证
'''
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
# StratifiedFold保证分层采样
skfolds = StratifiedKFold(n_splits=3, random_state=42)
clone_clf = SGDClassifier(random_state=42)
# split返回的是generator,返回n_splites次下标的tuple
for train_index, test_index in skfolds.split(X_train, y_train_3):
# clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = (y_train_3[train_index])
X_test_fold = X_train[test_index]
y_test_fold = (y_train_3[test_index])
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred))
# 0.9691515424228788 0.89555 0.9310965548277413
'''
使用cross_val_score()
'''
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_3, cv=3, scoring="accuracy")
# array([0.96915154, 0.89555 , 0.93109655])
精度(accuracy)通常来说不是一个好的性能度量指标,特别是当你处理有偏差的数据集,比方说其中一些类比其他类频繁得多。
混淆矩阵 Confusion Matrix
混淆矩阵计算输出类别A被分类成类别B的次数。为了知道分类器将3误分为5的次数,需要查看混淆矩阵的第三行第五列。混淆矩阵每一行表示一个实际类,每一列表示预测类
from sklearn.model_selection import cross_val_predict
# 首先需要一系列的预测值
# cross_val_predict()不是返回一个评估分数,而是返回基于每一个测试折(fold)做出的一个预测值。
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_3, cv=3)
# 计算混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_3, y_train_pred)
'''
array([[50454, 3415],
[ 669, 5462]], dtype=int64)
显然,如果是完美的分类器,那么混淆矩阵是一个对角矩阵。
'''
准确率(precision)、召回率(recall)
准确率=真正例TP/(真正例+假正例FP) (预测为A时实际为A的概率)
召回率=真正例/(真正例+假反例FN) (所有A中呗预测为A的概率)
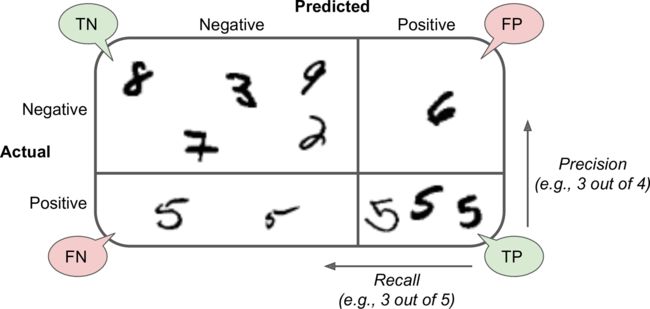
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_3, y_train_pred)
# 0.615297961022868 也就是说,预测true的时候只有61.5%的概率是正确的
recall_score(y_train_3, y_train_pred)
# 0.890882400913391 也就是说所有3中89%预测正确
通常结合准确率和召回率会更加方便,这个指标叫做“F1值”,是准确率和召回率的调和平均。
from sklearn.metrics import f1_score
f1_score(y_train_3, y_train_pred)
# 0.7278784648187633
折中准确率、召回率
分类器对于每个样例,会根据决策函数计算分数,如果这个分数大于一个阈值,它会将样例分配给正例,否则它将分配给反例.

Scikit-Learn 不让你直接设置阈值,但可以获取每个预测的分数。
y_scores = sgd_clf.decision_function([some_digit])
# array([198808.26046614])
y_some_digit_pred = (y_scores > threshold)
那么问题来了,如何确定阈值呢?
# 计算每个样例的决策分数
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function")
y_scores
#对于任何可能的阈值,计算准确率和召回率
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_3, y_scores)
# 画出准确率和召回率
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.xlabel("Threshold", fontsize=16)
plt.legend(loc="upper left", fontsize=16)
plt.ylim([0, 1])
plt.figure(figsize=(8, 4))
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.xlim([-700000, 700000])
plt.show()
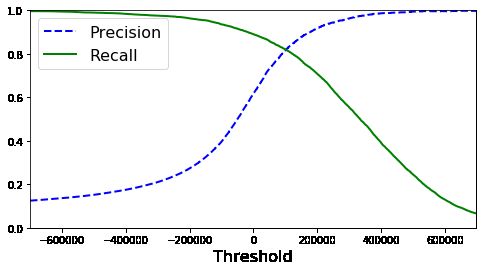
ROC曲线
receiver operating characteristic
ROC=召回率(TPR)/反例被错误分成正例的比率(FPR)
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_3, y_scores)
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plot_roc_curve(fpr, tpr)
plt.show()
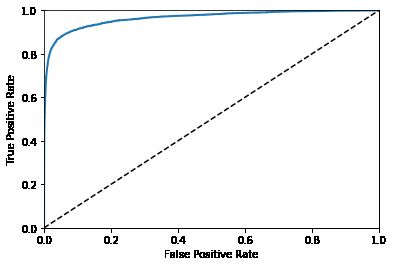
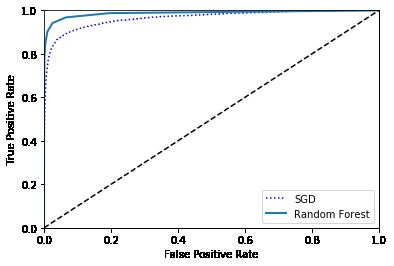
一个比较分类器之间优劣的方法是:测量ROC曲线下的面积(AUC)。一个完美的分类器的ROC AUC 等于 1,而一个纯随机分类器的 ROC AUC 等于 0.5。
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_3, y_scores)
# 0.9652235630769691
- 当正例很少,或者关注假正例多于假反例的时候优先使用 PR 曲线。其他情况使用 ROC 曲线。
用RandmonForest和SGD做对比
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_3, cv=3, method="predict_proba")
# 使用正例的概率当作样例的分数。
y_scores_forest = y_probas_forest[:, 1]
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_3,y_scores_forest)
plt.plot(fpr, tpr, "b:", label="SGD")
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")
plt.legend(loc="lower right")
plt.show()
roc_auc_score(y_train_3, y_scores_forest)
# 0.9873360345325553
4. 多类分类
二值分类器只能区分两个类(如SVM、线性分类器),多类分类器可以区分多个类别(如随机森林、朴素贝叶斯)。那如何使用二值分类器去执行多类分类呢?有两种办法:
一对所有
对0-9分别训练10个二值训练器,执行的时候用每一个分类器对图像进行分类,选择决策分数最高的那个分类器
一对一
训练45个分类器分别用来处理数字0-1,0-2,...,8-9。分类的时候,使用45个分类器分别计算,最后看哪个类获得的票数最多。
Scikit-Learn
Scikit-learn会根据任务自动将二值分类器用一对所有方式扩展到多类分类器。(除了SVM是根据一对一进行扩展)
sgd_clf.fit(X_train, y_train)
sgd_clf.predict([some_digit])
# array([3.])
# 为了验证sklearn背后训练了10个二值分类器:
some_digit_scores = sgd_clf.decision_function([some_digit])
some_digit_scores
#array([[-512758.67276683, -101342.87555673, -203227.77433503,
# 198808.26046614, -560734.96681417, -257289.30301749,
# -624490.71751773, -315341.57248572, -124822.5391974 ,
# -76050.76860889]])
np.argmax(some_digit_scores)
# 3
sgd_clf.classes_
# array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
如何强制使用一对一或者一对所有
from sklearn.multiclass import OneVsOneClassifier
ovo_clf = OneVsOneClassifier(SGDClassifier(max_iter=5, random_state=42))
ovo_clf.fit(X_train, y_train)
ovo_clf.predict([some_digit])
# array([3.])
len(ovo_clf.estimators_)
# 45
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
# array([0.86872625, 0.87639382, 0.87848177])
'''
86%的准确率已经很不错了,用standardScaler预处理训练数据,可以得到更好的结果
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
# array([0.90736853, 0.90884544, 0.91363705])
'''
RandomForestClassifier
forest_clf.fit(X_train, y_train)
forest_clf.predict([some_digit])
# array([3.])
# 这次 Scikit-Learn 没有必要去运行 OvO 或者 OvA,因为随机森林分类器能够直接将一个样例分到多个类别
# 得到对应所有类别的概率值列表
forest_clf.predict_proba([some_digit])
# array([[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])
专题:误差分析
这里假设已经通过GridSearchCV找到了一个不错的模型,如何去改善它呢?一种方式就是分析模型产生的误差的类型。
首先查看混淆矩阵
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx
'''
array([[5726, 2, 26, 12, 11, 47, 47, 9, 39, 4],
[ 1, 6479, 42, 33, 8, 39, 8, 9, 113, 10],
[ 55, 35, 5319, 104, 79, 20, 106, 51, 174, 15],
[ 45, 40, 145, 5372, 3, 210, 33, 50, 135, 98],
[ 17, 26, 38, 8, 5361, 5, 57, 31, 86, 213],
[ 74, 38, 43, 199, 71, 4584, 116, 26, 175, 95],
[ 33, 22, 43, 2, 42, 90, 5640, 3, 43, 0],
[ 24, 23, 73, 29, 60, 12, 4, 5774, 18, 248],
[ 49, 165, 73, 150, 16, 153, 50, 24, 5038, 133],
[ 39, 31, 26, 92, 163, 35, 3, 177, 79, 5304]],
dtype=int64)
一堆数字没法看,用Matplotlib展示
'''
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()

这个混淆矩阵看起来相当好,因为大多数的图片在主对角线上。在主对角线上意味着被分类正确。数字 5 对应的格子看起来比其他数字要暗淡许多。这可能是数据集当中数字 5 的图片比较少,又或者是分类器对于数字 5 的表现不如其他数字那么好。现在来验证两种情况。
- 关注仅包含误差数据的图像呈现。需要将混淆矩阵的每一个值除以相应类别的图片的总数目。这样比较的是错误率,而不是绝对的错误数(那样对大的类别不公平)。
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
# 用 0 填充对角线
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()
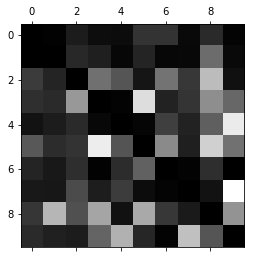
记住:行代表实际类别,列代表预测的类别。
第 8、9 列相当亮,这告诉你许多图片被误分成数字 8 或者数字 9。相似的,第 8、9 行也相当亮,告诉你数字 8、数字 9 经常被误以为是其他数字。另外3和5也很容易混淆。
举例子,你尝试去收集更多的数据,或者你可以构造新的、有助于分类器的特征。举例子,写一个算法去数闭合的环(比如,数字 8 有两个环,数字 6 有一个, 5 没有)。又或者你可以预处理图片(比如,使用 Scikit-Learn,Pillow, OpenCV)去构造一个模式,比如闭合的环。
当然也可以通过画出这些存在误差的例子,寻找规律
def plot_digits(instances, images_per_row=10, **options):
size = 28
images_per_row = min(len(instances), images_per_row)
images = [instance.reshape(size,size) for instance in instances]
n_rows = (len(instances) - 1) // images_per_row + 1
row_images = []
n_empty = n_rows * images_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row * images_per_row : (row + 1) * images_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap = matplotlib.cm.binary, **options)
plt.axis("off")
cl_a, cl_b = 3, 5
X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)]
X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)]
X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)]
X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)]
plt.figure(figsize=(8,8))
plt.subplot(221); plot_digits(X_aa[:25], images_per_row=5)
plt.subplot(222); plot_digits(X_ab[:25], images_per_row=5)
plt.subplot(223); plot_digits(X_ba[:25], images_per_row=5)
plt.subplot(224); plot_digits(X_bb[:25], images_per_row=5)
plt.show()

5. 多标签分类
到目前为止,所有的样例都总是被分配到仅一个类。有些情况下,需要分类器给一个样例输出多个类别。(比如一张图识别出多个人脸)
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
# 这段代码创造了一个 y_multilabel 数组,里面包含两个目标标签。第一个标签指出这个数字是否为大数字(7,8 或者 9),第二个标签指出这个数字是否是奇数。
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
knn_clf.predict([some_digit])
# array([[False, True]])
那么如何评估多标签分类器?
比如对每个标签度量F1值,(上文提到的其他度量方法也都可以)然后计算平均值。
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_train, cv=3)
f1_score(y_train, y_train_knn_pred, average="macro")
# 0.9671989524961443
# 如果各标签之间有权重之分,则设置average="weighted"
6. 多输出分类
在多标签的基础上,每一个标签的输出可以是多类别的。
为了说明这点,我们建立一个系统,它可以去除图片当中的噪音。它将一张混有噪音的图片作为输入,期待它输出一张干净的数字图片,用一个像素强度的数组表示,就像 MNIST 图片那样。注意到这个分类器的输出是多标签的(一个像素一个标签)和每个标签可以有多个值(像素强度取值范围从 0 到 255)。所以它是一个多输出分类系统的例子。
给图像加噪声
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = matplotlib.cm.binary,
interpolation="nearest")
plt.axis("off")
# 查看其中一个例子
some_index = 5500
plt.subplot(121); plot_digit(X_test_mod[some_index])
plt.subplot(122); plot_digit(y_test_mod[some_index])
plt.show()
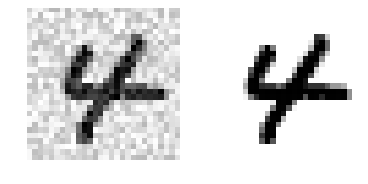
左边的加噪声的输入图片。右边是干净的目标图片。现在我们训练分类器,让它清洁这张图片:
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[some_index]])
plot_digit(clean_digit)

常见分类算法优缺点
练习
1. 尝试用KNeighborsClassifier对MNIST创建一个分类器,使得精度尽量高。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
param_grid = [
{"n_neighbors":[2,4,6], "weights":['distance', 'uniform']}
]
# n_jobs指定使用多少个CPU core
knn_clf = KNeighborsClassifier(n_jobs=4)
grid_search=GridSearchCV(knn_clf, param_grid, cv=5, verbose=3, n_jobs=4)
# 这里会运行很久
grid_search.fit(X_train, y_train)
grid_search.best_params_
# {'n_neighbors': 4, 'weights': 'distance'}
y_knn_pred = grid_search.best_estimator_.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_knn_pred)
# 0.9714
2. 对训练集上的每张图片,复制四个移动后的副本(每个方向一个副本),把它们加到训练集当中去。最后在扩展后的训练集上训练你最好的模型,并且在测试集上测量它的精度。
from scipy.ndimage.interpolation import shift
# cval指定边界填充的灰度值,默认是0
def shift_digit(digit_array, dx, dy, new=0):
return shift(digit_array.reshape(28, 28), [dy, dx], cval=new).reshape(784)
plot_digit(shift_digit(some_digit, 5, 1, new=100))
X_train_expanded = [X_train]
y_train_expanded = [y_train]
for dx, dy in ((1, 0), (-1, 0), (0, 1), (0, -1)):
# 对X_train第一个轴(维)的每个元素调用shift_digit方法
shifted_images = np.apply_along_axis(shift_digit, axis=1, arr=X_train, dx=dx, dy=dy)
X_train_expanded.append(shifted_images)
y_train_expanded.append(y_train)
X_train_expanded = np.concatenate(X_train_expanded)
y_train_expanded = np.concatenate(y_train_expanded)
X_train_expanded.shape, y_train_expanded.shape
# ((300000, 784), (300000,))
grid_search.best_estimator_.fit(X_train_expanded, y_train_expanded)
y_knn_expanded_pred = grid_search.best_estimator_.predict(X_test)
accuracy_score(y_test, y_knn_expanded_pred)
# 0.9763