Filebeat+Kafka+Logstash+ElasticSearch+Kibana+Springboot二次部署笔记
带着三年前分分钟搞定环境的优越感,在新的系统环境里重新搭建一套分布式日志采集系统,着实给自己坑了一把,今天把踩到的坑和经验总结一下,希望帮到后来的小伙伴。
先上一张成功的截图,喜悦一把:)

==================================华丽丽的分割线===========================================
首先到elastic官网https://www.elastic.co/cn/downloads/下载使用到的组件 并上传到准备安装的服务器。由于本次安装的环境在阿里云上,所以不用解决错综复杂的网络环境,默认服务器间是在一个局域网中的,无需打通网络环境。
部署架构如下图:
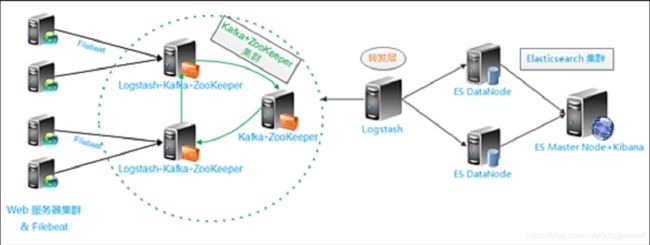
当前在测试环境搭了一套单点的服务,下面的内容为单点情况下部署的步骤,之后会补充集群的部署情况。
部署流程:
一、filebeat

下载解压filebeat到微服务的部署环境当中

修改配置文件filebeat.yml

修改input->paths->,将采集的日志文件地址添加进去,可以使用/* 等通配符,请自行查阅!因为是输出到kafka,所以输出配置如下:
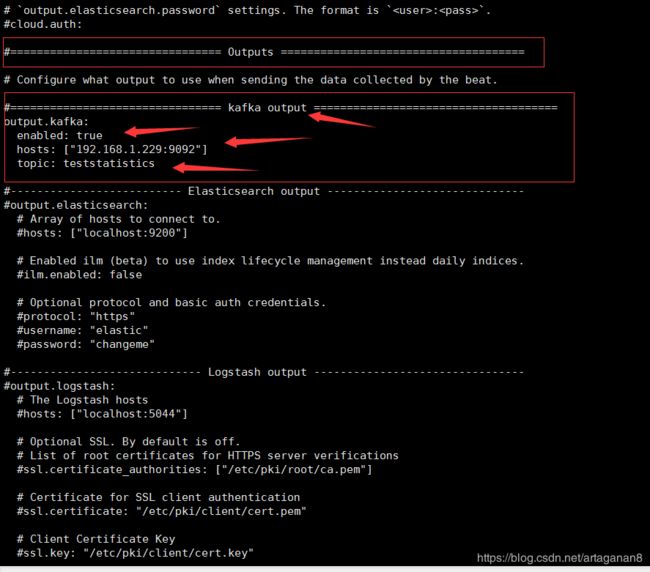
修改output,增加output-kafka标签,配置kafka的地址、端口号及topic,至此filebeat配置就OK了,其他配置待完善后补充。
二、kafka
下载解压kafka到消息服务器中,配置单节点,集群后面补充

我们使用kafka自带的zookeeper
![]()
cd /app/opt/soft/kafka_2.11-2.2.0/ #进入kafka主目录
mkdir -p zk/data #创建zookeeper数据存放目录
mkdir -p zk/logs #创建zookeeperl存放日志目录
cd config #进入配置文件所在目录
mv zookeeper.properties zookeeper.properties.bak #将原配置文件移走
cat > zookeeper.properties << EOF
tickTime=2000
dataDir=/app/opt/soft/kafka_2.11-2.2.0/zk/data
dataLogDir=/app/opt/soft/kafka_2.11-2.2.0/zk/logs
clientPort=2181
EOF![]()
到具体情况时注意修昨dataDir和dataLogDir为自己的相应目录
配置单结点kafka
进入config目录,配置server.config
vi server.properties

![]()
cd /usr/myapp/kafka_2.11 #进入kafka主目录
mkdir logs #创建logs目录用于存放日志
cd config #进入配置文件所在目录
mv server.properties server.properties.bak #将原配置文件移走
cat > server.properties << EOF
broker.id=1
listeners=PLAINTEXT://192.168.1.229:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/app/opt/soft/kafka_2.11-2.2.0/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
EOF![]()
上边配置的server.properties的内容基本都是原server.properties的默认配置,到自己安装时主要修改:
broker.id--broker的id;修改为任意自己想要的数值(和zookeeper中的id类似的)
listeners--对外暴露的服务器ip及端口信息,此处修改是为了跨服务调用,如单机配置使用默认localhost即可
log.dirs--日志文件存放目录;修改为自己要存放日志的目录
zookeeper.connect--zookeeper监听地址;修改为自己的zookeeper的监听地址,如果是集群所有地址全写上用逗号(半角)隔开即可
启动和停止
启动前要配置JAVA_HOME,不然无法启动(和tomcat一样虽然输出started了但并有有启,可查看kafkaServer.out)
启动:
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties 启动zookeeoer
./kafka-server-start.sh -daemon ../config/server.properties 启动kafka停止:
./zookeeper-server-stop.sh #停止zookeeper
./kafka-server-stop.sh #停止kafka,centos7上可能关不了用kill -9直接杀掉查看是否有zookeeper和kafka进程:
jps
下面两条命令为查看topiclist 以及具体list内容:
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --list
/kafka-topics.sh --zookeeper 127.0.0.1:2181 --topic teststatistics --describe
至此kafka单点的部署已经完成,现在可以启动filebeat了,kafka集群的部署稍后更新
nohup ./filebeat -e -c filebeat.yml -d "publish" >/app/opt/soft/filebeat-6.7.2-linux-x86_64/null 2>&1 &
三、logstash
下载解压losgtash
tar zxvf logstash-6.7.2.tar.gz
配置losgtash输入输出以及topics
vi first-pipeline.conf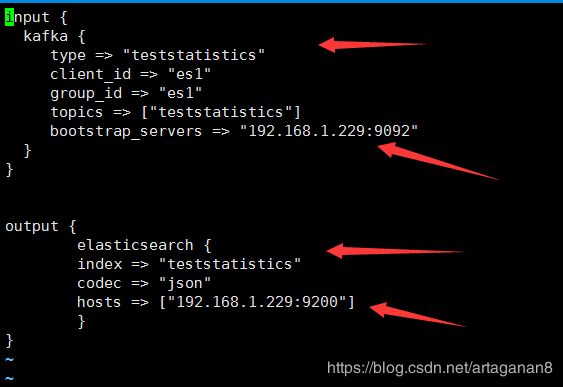
input {
kafka {
type => "teststatistics"
client_id => "es1"
group_id => "es1"
topics => ["teststatistics"]
bootstrap_servers => "192.168.1.229:9092"
}
}
output {
elasticsearch {
index => "teststatistics"
codec => "json"
hosts => ["192.168.1.229:9200"]
}
}
启动logstash
nohup ./logstash -f first-pipeline.conf --config.reload.automatic --path.data=/app/opt/soft/logstash-6.7.2 >/app/opt/soft/logstash-6.7.2/bin/null 2>&1 &
四、elasticsearch
下载解压elasticsearch
配置network.host、端口号和Node
cat elasticsearch.yml

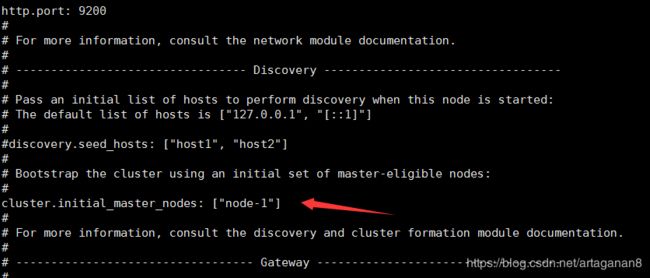
启动elasticsearch
nohup ./elasticsearch >/app/opt/soft/elasticsearch-7.0.1/bin/null 2>&1 &
启动过程遇到了一些坑,搜索到下面这两篇帖子,完美解决,感谢分享!
https://blog.csdn.net/showhilllee/article/details/53404042
https://blog.csdn.net/lixiaohai_918/article/details/89569611
创建elsearch用户组及elsearch用户
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
更改elasticsearch文件夹及内部文件的所属用户及组为elsearch:elsearch
chown -R elsearch:elsearch elasticsearch
elasticsearch为你elasticsearch的目录名称
切换到elsearch用户再启动
su elsearch #切换账户
cd elasticsearch/bin #进入你的elasticsearch目录下的bin目录
./elasticsearch
配置vim /etc/security/limits.conf文件
* soft nofile 65535
* hard nofile 65535
vim
配置vim /etc/security/limits.conf文件
* soft nproc 4096
* hard nproc 4096
配置vim /etc/sysctl.conf 文件
vm.max_map_count=262144
至此,单机elasticsearch安装配置完成,集群后补
五、kibana
下载解压kibana
修改端口号、host、elasticsearch-host配置
vi kibana.yml

启动kibana
nohup ./kibana >/app/opt/soft/kibana-6.7.2-linux-x86_64/bin/null 2>&1 &
kibana使用参考下面链接:
https://www.jianshu.com/p/2f7cf66bb9fc
https://blog.csdn.net/artaganan8/article/details/77891892
至此,所有组件安装,配置,启动完毕,单点环境可以使用了,后边会补充集群环境配置,敬请期待!
===================================未完待续=======================================