基于树模型的lightGBM文本分类
目录
1、基于TF的关键词提取
2、根据词频将文本转化为向量
3、基于树模型的重要特征选择
5、完整代码实现
6、分类结果
1、基于TF的关键词提取
使用TF词频对训练集clean_data_train进行关键词提取,选取topK个关键词作为特征词,即topK=10000。
# 训练集中词频统计,并计算TF值
def words_tf():
train_data = pd.read_csv('data/clean_data_train.csv', sep=',', names=['contents', 'labels']).astype(str)
sentence_list = []
lenth = len(train_data)
for i in range(lenth):
sentence_list.append(str(train_data['contents'][i]).split())
# 总词频统计
doc_frequency = defaultdict(int)
for word_list in sentence_list:
for i in word_list:
doc_frequency[i] += 1
# 计算每个词的TF值
word_tf = {} # 存储每个词的tf值
for i in doc_frequency:
word_tf[i] = doc_frequency[i] / sum(doc_frequency.values())
words_tf = sorted(word_tf.items(), key=lambda x: x[1], reverse=True)
return words_tf[:10000]
2、根据词频将文本转化为向量
根据所提取的关键词及其词频权重值,将训练集clean_data_train和测试集clean_data_test转换为向量,作为模型的输入。
# 根据词频,将文本转换为向量
def word2vec(keywords_tf, doc_sentence):
keywords = list(dict(keywords_tf).keys()) # 获取关键词
tf_weight = list(dict(keywords_tf).values()) # 获取关键词tf值
docvec_list = []
for sentence in doc_sentence:
docvec = [0] * len(keywords_tf)
for word in sentence:
if word in keywords:
docvec[keywords.index(word)] = tf_weight[keywords.index(word)]
docvec_list.append(docvec)
return docvec_list
# 将训练集和测试集换为文本向量
def doc_vec(x_train, x_test):
keywords_tf = words_tf() # 获取词频关键词
# 训练集转换为向量
train_lenth = len(x_train)
train_data_list = []
for i in range(train_lenth):
train_data_list.append(str(x_train[i]).split())
train_docvec_list = word2vec(keywords_tf, train_data_list)
# 测试集转换为向量
test_lenth = len(x_test)
test_data_list = []
for i in range(test_lenth):
test_data_list.append(str(x_test[i]).split())
test_docvec_list = word2vec(keywords_tf, test_data_list)
return train_docvec_list, test_docvec_list
3、基于树模型的重要特征选择
使用树模型对样本进行训练,从10000个特征中选择重要特征(选择特征重要性为1.5倍均值的特征),即features=986。
# 导入SelectFromModel结合ExtraTreesClassifier计算特征重要性,并按重要性阈值选择特征。
clf_model = ExtraTreesClassifier(n_estimators=250, random_state=0)
# clf_model=RandomForestClassifier(n_estimators=250,random_state=0)
clf_model.fit(x_train, y_train)
# 获取每个词的特征权重,数值越高特征越重要l
importances = clf_model.feature_importances_
'''
# 将词和词的权重存入字典并写入文件
feature_words_dic = {}
for i in range(len(words_list)):
feature_words_dic[words_list[i][0]] = importances[i]
# 对字典按权重由大到小进行排序
words_info_dic_sort = sorted(feature_words_dic.items(), key=lambda x: x[1], reverse=True)
#将前2000个词的权重字典写入文件
key_words_importance=dict(words_info_dic_sort[:2000])
with open('data/key_words_importance','w') as f:
f.write(str(key_words_importance))
'''
# 选择特征重要性为1.5倍均值的特征
model = SelectFromModel(clf_model, threshold='1.5*mean', prefit=True)
x_train_new = model.transform(x_train) # 返回训练集所选特征
x_test_new = model.transform(x_test) # 返回测试集所选特征4、lightGBM模型构建
lightGBM参数设置:num_round=2000,max_depth=6,learning_rate=0.1,其余采用模型默认参数。
# 创建成lgb特征的数据集格式
lgb_train = lgb.Dataset(x_train_new, y_train)
lgb_val = lgb.Dataset(x_test_new, y_test, reference=lgb_train)
# 构建lightGBM模型
params = {'max_depth': 6, 'min_data_in_leaf': 20, 'num_leaves': 35, 'learning_rate': 0.1, 'lambda_l1': 0.1,
'lambda_l2': 0.2, 'objective': 'multiclass', 'num_class': 3, 'verbose': -1}
# 设置迭代次数,默认为100,通常设置为100+
num_boost_round = 2000
# 训练lightGBM模型
gbm = lgb.train(params, lgb_train, num_boost_round, verbose_eval=100, valid_sets=lgb_val)5、完整代码实现
# coding=utf-8
import pandas as pd
import numpy as np
from collections import defaultdict
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.feature_selection import SelectFromModel
import lightgbm as lgb
from sklearn import metrics
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# 训练集中词频统计,并计算TF值
def words_tf():
train_data = pd.read_csv('data/clean_data_train.csv', sep=',', names=['contents', 'labels']).astype(str)
sentence_list = []
lenth = len(train_data)
for i in range(lenth):
sentence_list.append(str(train_data['contents'][i]).split())
# 总词频统计
doc_frequency = defaultdict(int)
for word_list in sentence_list:
for i in word_list:
doc_frequency[i] += 1
# 计算每个词的TF值
word_tf = {} # 存储每个词的tf值
for i in doc_frequency:
word_tf[i] = doc_frequency[i] / sum(doc_frequency.values())
words_tf = sorted(word_tf.items(), key=lambda x: x[1], reverse=True)
return words_tf[:10000]
# 根据词频,将文本转换为向量
def word2vec(keywords_tf, doc_sentence):
keywords = list(dict(keywords_tf).keys()) # 获取关键词
tf_weight = list(dict(keywords_tf).values()) # 获取关键词tf值
docvec_list = []
for sentence in doc_sentence:
docvec = [0] * len(keywords_tf)
for word in sentence:
if word in keywords:
docvec[keywords.index(word)] = tf_weight[keywords.index(word)]
docvec_list.append(docvec)
return docvec_list
# 将训练集和测试集换为文本向量
def doc_vec(x_train, x_test):
keywords_tf = words_tf() # 获取词频关键词
# 训练集转换为向量
train_lenth = len(x_train)
train_data_list = []
for i in range(train_lenth):
train_data_list.append(str(x_train[i]).split())
train_docvec_list = word2vec(keywords_tf, train_data_list)
# 测试集转换为向量
test_lenth = len(x_test)
test_data_list = []
for i in range(test_lenth):
test_data_list.append(str(x_test[i]).split())
test_docvec_list = word2vec(keywords_tf, test_data_list)
return train_docvec_list, test_docvec_list
if __name__ == '__main__':
train_data = pd.read_csv('data/clean_data_train.csv', sep=',', names=['contents', 'labels']).astype(str)
x_train, x_test, y_train, y_test = train_test_split(train_data['contents'], train_data['labels'], test_size=0.05)
x_train = np.array(x_train)
x_test = np.array(x_test)
cw = lambda x: int(x)
y_train = np.array(y_train.apply(cw))
y_test = np.array(y_test.apply(cw))
x_train, x_test = doc_vec(x_train, x_test) # 训练集和测试集向量化
x_train, y_train = shuffle(x_train, y_train, random_state=0) # 打乱顺序
# 导入SelectFromModel结合ExtraTreesClassifier计算特征重要性,并按重要性阈值选择特征。
clf_model = ExtraTreesClassifier(n_estimators=250, random_state=0)
# clf_model=RandomForestClassifier(n_estimators=250,random_state=0)
clf_model.fit(x_train, y_train)
# 获取每个词的特征权重,数值越高特征越重要l
importances = clf_model.feature_importances_
'''
# 将词和词的权重存入字典并写入文件
feature_words_dic = {}
for i in range(len(words_list)):
feature_words_dic[words_list[i][0]] = importances[i]
# 对字典按权重由大到小进行排序
words_info_dic_sort = sorted(feature_words_dic.items(), key=lambda x: x[1], reverse=True)
#将前2000个词的权重字典写入文件
key_words_importance=dict(words_info_dic_sort[:2000])
with open('data/key_words_importance','w') as f:
f.write(str(key_words_importance))
'''
# 选择特征重要性为1.5倍均值的特征
model = SelectFromModel(clf_model, threshold='1.5*mean', prefit=True)
x_train_new = model.transform(x_train) # 返回训练集所选特征
x_test_new = model.transform(x_test) # 返回测试集所选特征
print(x_train_new.shape)
print(x_test_new.shape)
# 创建成lgb特征的数据集格式
lgb_train = lgb.Dataset(x_train_new, y_train)
lgb_val = lgb.Dataset(x_test_new, y_test, reference=lgb_train)
# 构建lightGBM模型
params = {'max_depth': 6, 'min_data_in_leaf': 20, 'num_leaves': 35, 'learning_rate': 0.1, 'lambda_l1': 0.1,
'lambda_l2': 0.2, 'objective': 'multiclass', 'num_class': 3, 'verbose': -1}
# 设置迭代次数,默认为100,通常设置为100+
num_boost_round = 2000
# 训练lightGBM模型
gbm = lgb.train(params, lgb_train, num_boost_round, verbose_eval=100, valid_sets=lgb_val)
# 保存模型到文件
# gbm.save_model('data/lightGBM_model')
# 预测数据集
result = gbm.predict(x_test_new, num_iteration=gbm.best_iteration)
y_predict = np.argmax(result, axis=1) # 获得最大概率对应的标签
label_all = ['负面', '中性', '正面']
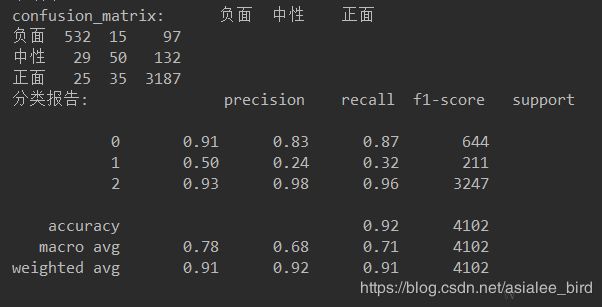
confusion_mat = metrics.confusion_matrix(y_test, y_predict)
df = pd.DataFrame(confusion_mat, columns=label_all)
df.index = label_all
print('准确率:', metrics.accuracy_score(y_test, y_predict))
print('confusion_matrix:', df)
print('分类报告:', metrics.classification_report(y_test, y_predict))6、分类结果