Deep Stacked Hierarchical Multi-patch Network for Image Deblurring 阅读笔记
Deep Stacked Hierarchical Multi-patch Network for Image Deblurring 阅读笔记
Zhang, H., Dai, Y., Li, H., & Koniusz, P. (2019). Deep Stacked Hierarchical Multi-patch Network for Image Deblurring. Retrieved from http://arxiv.org/abs/1904.03468
本文提出一个深度堆叠的多尺度补丁网络,用于运动去模糊
思路
目前的多尺度递归去模糊的模型存在两个问题:
- 由粗到细的上采样方案计算开销大
- 增加模型深度和细化层次并不能提高去模糊的效果
针对这两个问题,本文提出了一种基于空间金字塔的深堆叠的层级多补丁网络,通过精细到粗糙的分层表示来处理模糊图像。
该网络的优点:
- 由于不同层次的输入具有相同的分辨率,我们使用残差类学习,采用较小的滤波器尺寸,提高网络的计算速度
- 我们使用一个类似spm的模型,由于该模型有相对较多的可用补丁,因此可以在最细致的级别上使用更多的训练数据
- 该网络可以迁移到其他任务,并取得不错的效果。比如图像显著性方面
网络结构
网络结构如下,由4个层堆叠起来行程,每层都有编码器和解码器组成,中间是类似残差网络的结构。网络是从细分的patch逐渐网上计算,对应图上B4->B1这个过程。以B4为例,图片首先被分为不同的patch,输入编码器中,然后将每个patch仅限编码,然后将相邻两个进行连接操作(concatenation),这样就变成了4个patch,再通过解码器解码,的到的结果用 S 4 j S_{4j} S4j来表示。B4得出的结果就可以与叠加(加法操作),叠加之后的结果输入编码器,得到编码的结果,该编码结果与B4编码并连接操作后的特征进行叠加,将叠加后得到的结果每相邻两个patch进行连接操作,得到两个patch的特征…就这样一致迭代下去,最终得到网络预测,即整幅图片。最小化网络预测输出和GT的MSE,更新参数
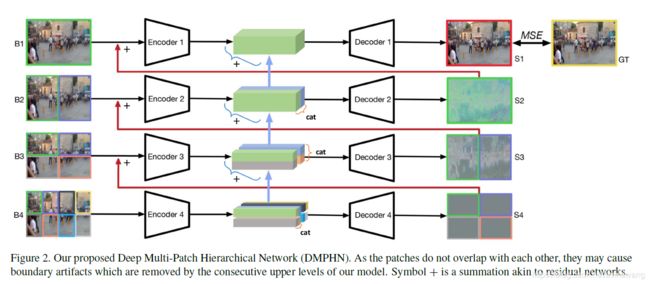
编码器和解码器的结构
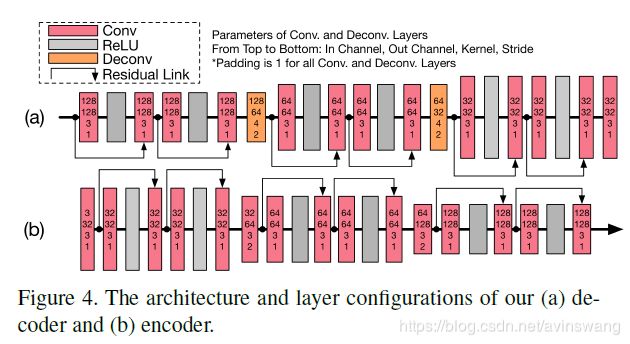
b是编码器结构,a是解码器结构。编码器由15个conv层和6个残差和6个RELU模块组成的,解码器和编码器的结构是相似的,只不过将两个卷积层被反卷积层替换以生成图像。编码器和解码器的参数量只有3.6M,远远小于其他的网络,所以这个网络的运行速度很快。
网络运行原理
下面得是一个1-2-4-8结构的网络,1表示 B 1 B_1 B1层的patch数,只有一个;2表示 B 2 B_2 B2层的patch数,为 1 × 2 = 2 1\times2=2 1×2=2个;同理,3,4表示 B 3 B_3 B3和 B 4 B_4 B4patch的数量,分别为 2 × 2 = 4 2\times2=4 2×2=4个, 2 × 8 2\times8 2×8个。当然,也可以增加网络的patch数,但实验证明再细化patch并不能提高效果。
首先将网络分级,分为4个级,用 i , i = { 1 , 2 , 3 , 4 } i, i=\{1,2,3,4\} i,i={1,2,3,4}表示。
将初始模糊图像输入表示为 B 1 B_1 B1, B i j B_{ij} Bij为第 i i i级的第 j j j个patch,如 B 4 B_4 B4中青色的patch可表示为 B 47 B_{47} B47。 其中 F i F_i Fi和 G i G_i Gi为 i i i级的编码器和解码器, C i j C_{ij} Cij为 B i j B_{ij} Bij经过解码器 G i G_i Gi输出, S i j S_{ij} Sij为 G i G_i Gi的输出patch。
详细步骤
从第4层开始,逐层往上运行。首先将模糊图片 B 1 B_1 B1分成8个不相交的patch,用 B 4 j B_{4j} B4j表示, j { 1 , . . . , 8 } j\{1,...,8\} j{1,...,8}
将输入的每个patch输入进编码器,得到输出结果 C 4 j C_{4j} C4j
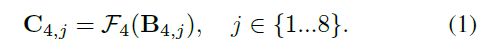
将每两个相邻的pathc进行连接(concatenate)操作,如patch1与patch2,以此类推。最终得到4个patch,用 C 4 j ∗ C^*_{4j} C4j∗来表示。这么做的目的是为了和第三层进行叠加
![]()
第4层的经过解码器输出的结果用 S 4 j S_{4j} S4j表示,如下
![]()
第3层
首先将第4层的输入和第3层输入的模糊图片叠加(这里输入的模糊图片和第4层连接过后的尺度是一样的),将叠加后得到的特征输入编码器,得到一个输出 F 3 ( B 3 j + S 4 j ) \mathcal{F}_3(B_{3j}+S_{4j}) F3(B3j+S4j),将编码器得到的输出和第4层concatenate操作的特征图相加,如下式,得到第3层的特征图
![]()
如此迭代下去,最终和没有patch的图片( B 1 B_1 B1)叠加,得到网络的输出


![]()
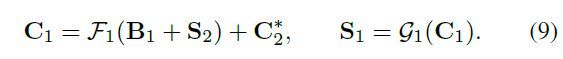
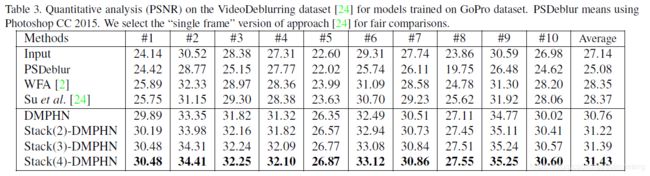
最终得到的网络输出用 S 1 S_1 S1表示
L o s s Loss Loss计算的是 S 1 S_1 S1和 G T GT GT的MSE
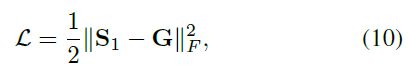
设计的两种网络结构
下图上面的一种称为堆叠-DMPHN,下面的一种称为堆叠-VMPHN。这是将单个DMPHN网络按照两种不同的策略堆叠起来,用于提高网络的性能

堆叠实验的结果
从图中可以看到
- 个DMPH网络,stack-DMPHN,Stack-VMPHN网络都取得了同组对比实验中最好的结果, 第3组和第4组实验结果可知
- Stack-VMPHN的性能达到最优,PSNR比DMPHN高1.3%
- 第2组实验结果可知, 使用更加细分的patch不能提高网络的性能
- DMPHN的运算速度是Stack(2)-VMPHN的18倍
- Stack(4)-DMPHN 比 DMPHN模型的PSNR高1%
- VMPHN比DMPHN高0.7%
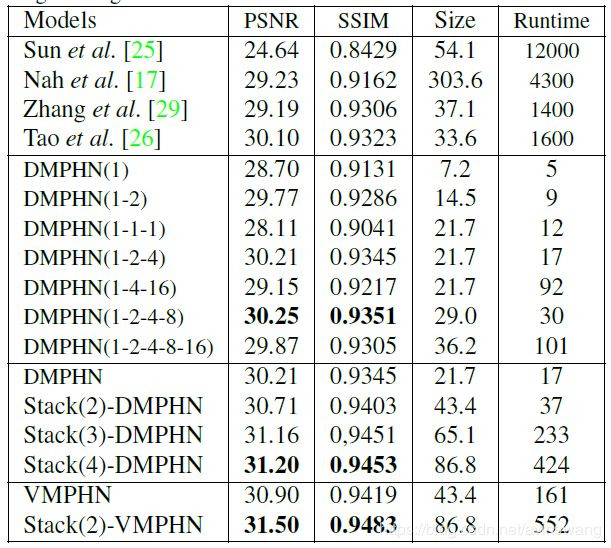
这是在VedioDeblurring数据集和GoPro数据集进行实验, 得到的实验结果如下, 可以看到Stack(4)-DMPHN的性能都是最优的
 为了使我们的网络兼容显著性检测任务,将输出通道修改为1进行灰度图像生成,并在VMPHN中禁用第1层输入与输出之间的残差连接。这是与其他方法的对比, 可以看出本文的方法的效果较好。显著性这块没有看过, 把论文结果贴在这
为了使我们的网络兼容显著性检测任务,将输出通道修改为1进行灰度图像生成,并在VMPHN中禁用第1层输入与输出之间的残差连接。这是与其他方法的对比, 可以看出本文的方法的效果较好。显著性这块没有看过, 把论文结果贴在这

这个是在MSRA-B运行的结果

总结
本文提出了多层堆叠的多尺度patch网络用于去除运动模糊, 可以实现实时处理(30fps, 1280*760,GPU)。本文采用了多层级联的方法, 从细粒度的patch到粗粒度patch, 使得网络能够能够提取到图片中更多信息, 通过逐层融合, 提高了网络的性能。通过对网络的叠加, 进一步提高了网络的性能。该网络不仅可以运用到运动去模糊,也可以运用到显著性检测任务上
评价
网络主要有两点贡献: 1. 多层多patch网络模型, 2. 网络模型叠加, 主要贡献点在第一个上, 将下一层输出的特征与上一次输入图片叠加, 将下一层编码后的特征与上一层编码的特征叠加。但是为什么这么做是有效的, 文章中并没有指出。总得来说, 文章是用一个SPM思路来解决运动去模糊问题, 并取得了很好地效果