Flume实战开发配置
example 1.
实际开发中我们常用的是把Flume采集的日志按照指定的格式传到HDFS上,为我们的离线分析提供数据支撑
我们使用二个主机进行数据的生产与采集,简单的了写了一个脚本,
服务器 hadoop1
#!/bin/bash
#打印100次文本到dynamic.log文本中
for((i=1;i<=100;i++))
do
echo $i hello,wolrd >> /usr/local/dynamic.log
done
然后使用定时任务crontab 去定时执行
crontab -e去编译定时任务
*/1 * * * * sh /usr/local/printData.sh(一分钟执行一次这个脚本)
crontab -l 查看我们编辑的定时任务
然后配置Flume来采集这台机子的数据
#a2代表agent,一个agent由source,channel,sink组成
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source 配置source组件
a2.sources.r1.type = exec
a2.sources.r1.command =tail -F /usr/local/dynamic.log
a2.sources.r1.shell= /bin/sh -c
# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.channel = c1
a2.sinks.k1.hostname = hadoop3 (Arvo通过rpc 发送的数据IP,hadoop3我做了网络映射可以直接写Hadoop3,没有做的过就写你要传送的机器ip)
a2.sinks.k1.port = 16888 (Arvo通过rpc 发送的数端口)
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
我们hadoop1使用Flume架构是 Exec Source => Memory Channel=> Avro Sink
然后我们准备hadoop3服务器,作为数据接收端来使用
Flume采用的架构是 Avro Source=> File Channel=> HDFS Sink
然后我们编辑conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop3
a1.sources.r1.port = 16888
# Use a channel which buffers events in memory
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/local/flume_data/checkpointDir
a1.channels.c1.dataDirs = /usr/local/flume_data/dir
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.capacity = 10000000
#sink to hdfs
a1.sinks.k1.type = hdfs
#文件的格式是/flume/年月日/小时
a1.sinks.k1.hdfs.path = hdfs://hadoop3:8020/flume/%Y%m%d/%H
#文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#设置多少events写到hdfs
a1.sinks.k1.hdfs.batchSize = 1000
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
##多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
##重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
##是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
##积攒多少个 Event 才 flush 到 HDFS 一次
a1.sinks.k1.hdfs.batchSize = 1000
##多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 30
##设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
##文件的滚动与 Event 数量无关
a1.sinks.k1.hdfs.rollCount = 0
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:MemoryChannel提供高吞吐的性能,同时在断电和程序崩溃之后会造成数据丢失。因此需要开发一个持久化的Channel。File Channel的目标是提供一个可靠的高吞吐Channel。File Channel保证当事务被提交后,不会因为一系列程序崩溃或者掉电而造成数据丢失。所以开发我们一般都会才会File Channel,测试的话就方便随意了
然后我们hadoop3的Flume ng,注意一定要先启动这个,这个是提供端口服务的。
nohup sh bin/flume-ng agent --conf /usr/local/flume-1.8.0/ --conf-file conf/example4.conf --name a1 logger.conf -Dflume.root.logger=INFO,console &
我们采用的是后台启动 ,使用nohup 和&,日志就会输出在nohup.out
![]()
服务正常启动,然后我们启动hadoop1的Flume

然后我们的定时脚本就会一分钟执行一次了,然后hadoop1的Flume就是收集这一分钟的数据进行传输,然后查看你hadoop的文件夹的数据,这个example就到此结束了。
example2:
Flume采集数据,Sink到kafka的topic中,这才是我们企业中常用的例子
配置还都使用上面的配置,只需要把hadoop3这台机器sink的配置改成kafka就行了
# Describe the sink
a2.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a2.sinks.k1.kafka.topic = bosir
a2.sinks.k1.kafka.bootstrap.servers = 192.168.1.4:9092
a2.sinks.k1.kafka.flumeBatchSize = 100
a2.sinks.k1.kafka.producer.acks = 1
a2.sinks.k1.kafka.producer.max.request.size = 500
其他的不变.
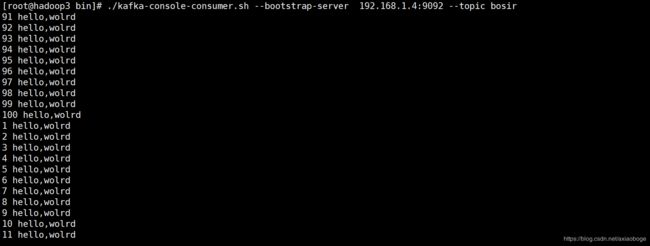
这样我们就能通过hadoop1机器上的flume采集到的文件通过该avro传输到hadoop3的机器上,然后hadoop3在sink到kafka中,给sparkStreaming提供数据分析。
note:配置过程中如果没有出现我们想到的结果可以检测防火墙,端口,以及kafka的监听端口

发现和解决问题的过程才是愉快的,有问题欢迎加入qq群 56461419,一起讨论学习交流进步.