log4j2 使用说明
因近期需要编写J2EE程序,所以简单学习了Log4j2,这里把我学习的一些信息做记录:
1、从HelloWorld开始
参考:http://logging.apache.org/log4j/2.x/manual/api.html
首先创建一个Java Project,如下图,在项目中创建lib文件夹,将log4j的api和core包复制进去并配置到项目编译路径中。
创建包com.demo并在包内创建类HelloWorld。
HelloWorld类的内容如下:
package com.demo;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class HelloWorld {
private static final Logger logger = LogManager.getLogger("HelloWorld");
public static void main(String[] args) {
String hello = "Hello, World!";
logger.trace("TRACE: " + hello);
logger.debug("DEBUG: " + hello);
logger.info("INFO: " + hello);
logger.warn("WARN: " + hello);
logger.error("ERROR: " + hello);
logger.fatal("FATAL: " + hello);
}
}
运行HelloWorld,结果显示如下:
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
00:06:16.530 [main] ERROR HelloWorld - ERROR: Hello, World!
00:06:16.532 [main] FATAL HelloWorld - FATAL: Hello, World!
运行时提示没有找到Log4j2的配置文件,使用默认配置,只显示error到控制台。
缺省的配置等同于如下配置,其中Root指定的level是error,所有只输出了error和fatal级别的日志。
2、理解log4j2的结构
参考:http://logging.apache.org/log4j/2.x/manual/architecture.html
结合我们的HelloWorld程序,我们看一下log4j2的结构:
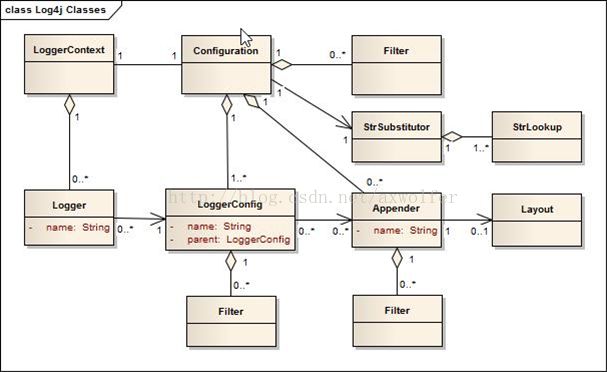
LoggerContext是整个Log系统的锚点,每一个LoggerContext会含有一个Configuration,在congfiguration中会包含Appender(输出器)、Filter(过滤器)、LoggerConfig及StrSubstitutor的引用。
当我们在配置文件中声明一个Loggers时就会创建一个LoggerConfig, LoggerConfig包含有一组Filter,同时持有一组Appender的引用。LoggerConfig所收到的所有LogEvent首先经过过滤器处理才会传递给Appendar输出。
Filter会存在三种返回结果:Accept、Deny、Neutral。Accept表示事件将直接被处理并不继续转发其他Filter,Deny表示事件将被忽略,Neutral表示事件将被转发给下一个filter,如果没有后续的filter,事件将被处理。
3、理解Named Hierarchy (日志名称层次规则)
首先我们在com.demo包内新增一个类NamedHierarchy:
package com.demo;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class NamedHierarchy {
private static final Logger logger = LogManager.getLogger(NamedHierarchy.class);
public static void main(String[] args) {
// TODO Auto-generated method stub
String nh = "Named Hierarchy";
logger.getLevel();
logger.trace("TRACE: " + nh + " " + logger.getLevel());
NamedHierarchy n = new NamedHierarchy();
n.run();
logger.error("ERROR: " + nh + " " + logger.getLevel());
}
public void run(){
String nh = "NamedHierarchy.run";
logger.debug("DEBUG: " + nh + " " + logger.getLevel());
}
}
在src下新增log4j2.xml,并按如下修改文件:
工程结构如下:
运行NamedHierarchy你会发现结果如下:
01:33:48.864 [main] TRACE com.demo.NamedHierarchy - TRACE: Named Hierarchy TRACE
01:33:48.864 [main] TRACE com.demo.NamedHierarchy - TRACE: Named Hierarchy TRACE
01:33:48.864 [main] TRACE com.demo.NamedHierarchy - TRACE: Named Hierarchy TRACE
01:33:48.867 [main] DEBUG com.demo.NamedHierarchy - DEBUG: NamedHierarchy.run TRACE
01:33:48.867 [main] DEBUG com.demo.NamedHierarchy - DEBUG: NamedHierarchy.run TRACE
01:33:48.867 [main] DEBUG com.demo.NamedHierarchy - DEBUG: NamedHierarchy.run TRACE
01:33:48.868 [main] ERROR com.demo.NamedHierarchy - ERROR: Named Hierarchy TRACE
01:33:48.868 [main] ERROR com.demo.NamedHierarchy - ERROR: Named Hierarchy TRACE
01:33:48.868 [main] ERROR com.demo.NamedHierarchy - ERROR: Named Hierarchy TRACE
为什么同样的日志信息会被输出三次呢?这是因为logger的命名符合命名层次规则,而层次关系是由对应的LoggerConfig来维护的。root是整个层次规则(或结构)的顶层,父节点和子节点是通过“.”来识别的,如com.demo是com.demo.NamedHierarchy的父节点,com.demo.NamedHierarchy是com.demo的子节点。
同时Logger的命名和类的命名又有关联的,如果我们在配置文件中配置一个Logger的名称为com.demo.NamedHierarchy,那么类com.demo.NamedHierarchy中的Logger就会匹配到这一配置,同时所有父节点的配置也会被适用。所以在我们使用logger.trace("TRACE: " + nh + " " + logger.getLevel()); 输出日志时,配置文件中3个Logger对应的Appender分别被调用。
如果你把
修改为
运行,结果如下:
21:40:44.389 [main] ERROR com.demo.NamedHierarchy - ERROR: Named Hierarchy ERROR
21:40:44.389 [main] ERROR com.demo.NamedHierarchy - ERROR: Named Hierarchy ERROR
21:40:44.389 [main] ERROR com.demo.NamedHierarchy - ERROR: Named Hierarchy ERROR
为什么父节点的Appender没有输出?这是由于LogEvent的level和LoggerConfig的level在特定组合下,LogEvent不会被继续向下转发处理,组合关系如下,其中YES表示转发继续处理,NO表示不继续转发。
| Event Level |
LoggerConfig Level |
||||||
| 聽 |
TRACE |
DEBUG |
INFO |
WARN |
ERROR |
FATAL |
OFF |
| ALL |
YES |
YES |
YES |
YES |
YES |
YES |
NO |
| TRACE |
YES |
NO |
NO |
NO |
NO |
NO |
NO |
| DEBUG |
YES |
YES |
NO |
NO |
NO |
NO |
NO |
| INFO |
YES |
YES |
YES |
NO |
NO |
NO |
NO |
| WARN |
YES |
YES |
YES |
YES |
NO |
NO |
NO |
| ERROR |
YES |
YES |
YES |
YES |
YES |
NO |
NO |
| FATAL |
YES |
YES |
YES |
YES |
YES |
YES |
NO |
| OFF |
NO |
NO |
NO |
NO |
NO |
NO |
NO |
如果你不希望LogEvent被按命名层次分别处理,只希望最低一层的子节点处理,那么可以在Logger配置时增加additivity="false",如:
4、定时重新加载配置
Log4j2支持定时检查配置文件是否变化并根据变化重新加载,这个功能在实际应用中比较有价值,比如产品上网后有问题,如果默认的error级别的日志不能支撑定位,需要切换到trace级别,定时加载的功能就可以避免重启服务,毕竟商用产品重启服务代价还是很大的,有时候还必须先获取客户的授权。
在Configuration中增加monitorInterval="30"参数,其中30指30秒,如下:
...
5、常用的Appender
关于详细的Appender及配置参数,建议查看API:http://logging.apache.org/log4j/2.x/manual/appenders.html
5.1 FileAppender
FileAppender支持把日志信息写入文件,典型的配置如下:
append用来设置程序开始时日志是否被追加到原日志文件上,fileName表示要保存的文件名称,bufferedIO和bufferSize表示将日志内容缓存到bufferSize大小后写入文件:
5.2 RollingFileAppender
循环写入文件,典型配置如下:
以下的配置可以简单概括为:初始日志名称是rolling.log,当rolling.log日志文件达到1KB时,将rolling.log修改为app-日期-1.log并压缩为app-日期-1.log.gz,rolling.log重新开始写;当再次达到1KB时,将rolling.log修改为app-日期-2.log并压缩为app-日期-2.log.gz,rolling.log重新开始写;当再次达到1KB时,删除app-日期-1.log.gz,修改app-日期-2.log.gz为app-日期-1.log.gz,将rolling.log修改为app-日期-2.log并压缩为app-日期-2.log.gz,rolling.log重新开始写;
filePattern="logs/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz"> 建议你使用此配置写一个简单的脚步验证效果。 更多详细内容,请查看官方文档:http://logging.apache.org/log4j/2.x/manual/architecture.html