Spark Streaming消费kafka,不同topic-join实时统计
前言
习惯用了Spark Sql,做实时统计的时候,也想用Structured Streaming .
但发现一个特殊情况
目前Structured Streaming (spark2.1.2) 不支持两个topic join,
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
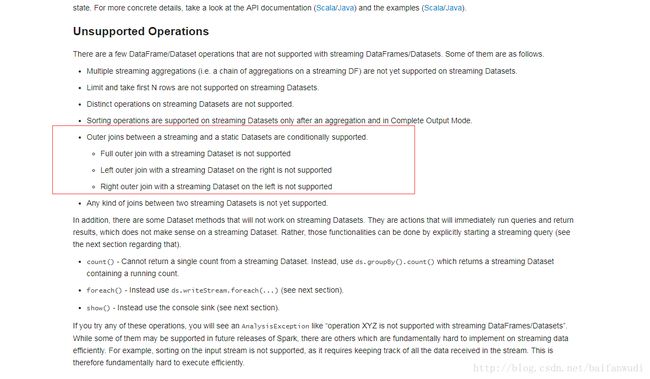
所以用DStream做处理.
Spark Streaming消费
kafka连接配置参数
SparkConf sparkConf = new SparkConf().setAppName("CheckDownOnlineBak");
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.seconds(30));
jssc.checkpoint(checkpointDirectory);
Map kafkaParams = new HashMap<>(12);
kafkaParams.put("bootstrap.servers", KafkaConfig.KAFKA_BROKER_LIST);
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "local_test");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
kafkaParams.put("max.poll.records", 1000); KafkaConfig.KAFKA_BROKER_LIST 为你所在kafka的broke-list地址.
Durations.seconds(30)为每隔30秒从kafka拉取消息,
checkpointDirectory为checkpoint目录
Topic1(ota_check)消费逻辑
Collection<String> checkTopics = Arrays.asList("ota_check");
JavaInputDStream<ConsumerRecord<String, String>> streamCheck = KafkaUtils.createDirectStream(jssc, LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(checkTopics, kafkaParams));
JavaPairDStream<Tuple4, Tuple2> checkResult = streamCheck.mapToPair(
s -> {
try {
CheckInfo checkInfo = JSON.parseObject(s.value().toString(), CheckInfo.class);
String mid = checkInfo.getMid();
Long productId = checkInfo.getProductId();
String deviceId = checkInfo.getDeviceId();
Integer deltaId = checkInfo.getDeltaId();
String lac = checkInfo.getLac();
String cid = checkInfo.getCid();
Tuple4<String, Long, String, Integer> tuple4 = new Tuple4<String, Long, String, Integer>(mid, productId, deviceId, deltaId);
Tuple2<String, String> tuple2 = new Tuple2<String, String>(lac, cid);
return new Tuple2<Tuple4, Tuple2>(tuple4, tuple2);
} catch (Exception e) {
return new Tuple2<Tuple4, Tuple2>(null, null);
}
}
).filter(s -> s._2() != null && s._2()._1() != null && s._2._2 != null).window(Durations.minutes(10), Durations.minutes(1));
checkResult.print();window(Durations.minutes(10), Durations.minutes(1))为数据的时间窗口是10分钟
,超过10分钟的message自动删除,
且每1分钟算一次.
Topic2(ota_download)消费逻辑
Collection<String> downTopics = Arrays.asList("ota_download");
JavaInputDStream<ConsumerRecord<String, String>> streamDown = KafkaUtils.createDirectStream(jssc, LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(downTopics, kafkaParams));
JavaPairDStream<Tuple4, Float> downResult = streamDown.mapToPair(
s -> {
try {
DownInfo downInfo = JSON.parseObject(s.value().toString(), DownInfo.class);
Integer downloadStatus = downInfo.getDownloadStatus();
if (downloadStatus != 1) {
return new Tuple2<Tuple4, Float>(null, null);
}
Long downStart = Long.parseLong(downInfo.getDownStart());
Long downEnd = Long.parseLong(downInfo.getDownEnd());
String mid = downInfo.getMid();
Long productId = downInfo.getProductId();
String deviceId = downInfo.getDeviceId();
Integer deltaId = downInfo.getDeltaId();
Integer downSize = downInfo.getDownSize();
Float downRate = (float) downSize / (downEnd - downStart) / 1024;
Tuple4<String, Long, String, Integer> tuple4 = new Tuple4<String, Long, String, Integer>(mid, productId, deviceId, deltaId);
return new Tuple2<Tuple4, Float>(tuple4, downRate);
} catch (Exception e) {
e.printStackTrace();
return new Tuple2<Tuple4, Float>(null, null);
}
}
).filter(s -> s._2 != null).window(Durations.minutes(5), Durations.minutes(1));
downResult.print();这里面window(Durations.minutes(5), Durations.minutes(1))的时间窗口为5分钟,每一分钟算一次.
downloadStatus =1 表示为下载成功,
只取了下载成功数据,类似于SparkSql中 filter($”downloadStatus”===1)语法,
downRate为计算出下载速率.
Topic-Join操作
JavaPairDStream<Tuple3<String,String,String>,Tuple2<String,Double>> joinResult=checkResult.join(downResult).mapToPair(
s->{
String productId=s._1._2().toString();
String deviceId=s._1._3().toString();
String lac=s._2()._1()._1().toString();
String cid=s._2()._1()._2().toString();
Double downRate=s._2()._2();
Tuple3<String,String,String> tuple3=new Tuple3<String,String,String>(productId,lac,cid);
Tuple2<String,Double> tuple2=new Tuple2<String,Double>(deviceId,downRate);
return new Tuple2<Tuple3<String,String,String>,Tuple2<String,Double>>(tuple3,tuple2);
}
);
joinResult.print();join后结果 ,key为(productId,lac,cid),value为(deviceId,downRate),
productId为项目id,(lac,cid)表示基站,deviceId是设备号,downRate表示该设备在这个基站的下载速率.
做groupBy操作
JavaPairDStream<Tuple3<String,String,String>,Tuple4<Double,Integer,Double,Date>> finalResult=joinResult.groupByKey().mapValues(
(set)->{
int countNum=0;
Double downRateSum=0.0;
for(Tuple2<String,Double> tuple2:set){
countNum++;
downRateSum+=tuple2._2;
}
Double downRateAvg=downRateSum/countNum;
Date date=new Date();
return new Tuple4<Double,Integer,Double,Date>(downRateSum,countNum,downRateAvg,date);
}
);
finalResult.print();总的结果计算(productId,lac,cid)一个项目在某一个基站下,平均设备更新的下载速率
补充
maven依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_2.11artifactId>
<version>2.1.2version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.11version>
dependency>