python多线程爬取电影天堂多页磁力链接(续)
利用多线程改进后代码
import time
from urllib import request
import re
import threading
from datetime import datetime
#按F12查看
'''
headers={
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134
'''
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
#获取网页源代码函数
def gethtml(url):
url_request = request.Request(url, headers=headers) # 加上头部
response = request.urlopen(url_request)
data = response.read().decode('gb2312','ignore')#解决中文乱码问题
#print(data) # 输出源代码
return data
#查询函数,返回一个列表
def search(msg,html):
list=re.findall(msg,html)#正则表达式查询所有符合条件的msg,保存在列表
return list
#查询网页标题
def search_name(html):
begin=html.find('title')
end = html.find(')
name = html[begin + 6:end]
return name
#获取磁力链接
def get_ftp(html):
begin = html.find('magnet')
end = html.find('fannounce')
ftp = html[begin:end+len('fannounce')]
return ftp#">
#获取网页url函数
def get_url(num):
#num=int(num)
if num==1:
return 'https://www.dytt8.net/html/gndy/dyzz/index.html'#最新电影分类的主页链接
return 'https://www.dytt8.net/html/gndy/dyzz/list_23_'+str(num)+'.html'
# 线程操作函数
def thread_func(i):
url=get_url(i)
print(url)
html = gethtml(url)
#print(html)
purl = '= search(purl, html) # 查找符合条件的网页url
for each in plist:
pos = each.find('/html')
each = 'https://www.dytt8.net' + each[pos:]
html = gethtml(each)
name = search_name(html)
print('第' + str(i) + '页')
print(name)
# print(each)
ftp = get_ftp(html)
print(ftp)
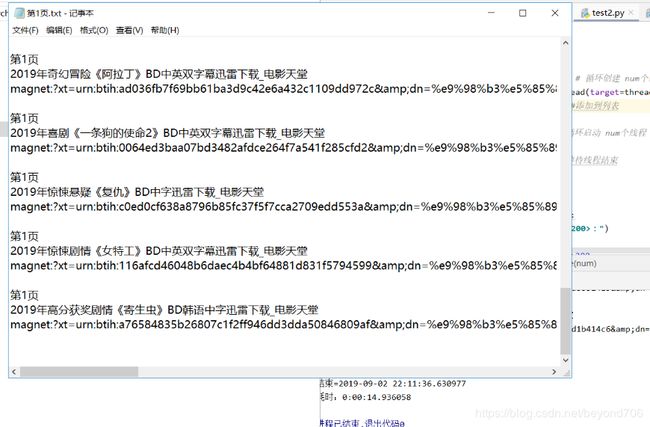
filename = '第' + str(i) + '页' + '.txt'
f = open(filename, 'a', encoding='utf-8')
f.write('第'+str(i) +'页'+'\n'+name + '\n' + ftp + '\n\n')
def many_thread(num):
threads = []
for i in range(num): # 循环创建 num个线程
t = threading.Thread(target=thread_func,args=(i+1,))#传参数,第一个是0,所以+1
threads.append(t)#添加到列表
for t in threads: # 循环启动 num个线程
t.start()
for t in threads: #等待线程结束
t.join()
#主函数
if __name__ == '__main__':
num=input("输入页数<1~200>:")
num=int(num)
while num < 1 or num >200:
num = input("输入正确页数<1~200>:")
num = int(num)
start = datetime.today().now()
many_thread(num)
duration = datetime.today().now()
print('----------\nfinally')
print('开始='+str(start))
print('结束='+str(duration))
print('耗时:'+str(duration-start))