时间序列学习笔记之python详细实践(二)
上一篇文章讲了时间序列的理论基础,对于时间序列数据的分析,总的来说就是以下几点:
- 1、一般不需要进行白噪声检验,直接观测是否是平稳的时间序列,即平稳性检验。如时序图检验 、自相关图检验、单位根ADF检验。
- 2、对于非平稳的时间序列数据,进一步做处理,使之变为平稳。包括差分方法、对数变换方法、移动平均或者指数平均方法等。
- 3、经过第二步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数ACF 和偏自相关系数PACF ,通过对自相关图和偏自相关图的分析,得到最佳的阶层 p 和阶数 q
- 4、检验模型的有效性。如果拟合模型通不过检验,转向步骤3,重新选择模型再拟合。
- 5、模型优化。如果拟合模型通过检验,仍转向步骤2,充分考虑各种可能,建立多个拟合模型,从所 有通过检验的拟合模型中选择最优模型。
- 6、利用拟合模型,预测序列的将来走势。
接下来以详细的实例进行分析:
一、导入数据【AirPassengers.csv】
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
from statsmodels.tsa.stattools import adfuller
plt.rcParams['font.sans-serif']=['SimHei']
rcParams['figure.figsize'] = 10, 5
#data = pd.read_csv('AirPassengers.csv',index_col = [0],header = 0)
data = pd.read_csv('AirPassengers.csv', index_col='Month')
ts = data['Passengers']二、查看导入的数据
ts.head() #查看时间序列的内容
Out[6]:
Month
Jan-49 112
Feb-49 118
Mar-49 132
Apr-49 129
May-49 121
Name: Passengers, dtype: int64
type(ts.index.values[0]) #查看索引是否是时序
Out[7]: str
#可以得知当前的索引非时序类型,通过to_datetime进行转换
ts.index = pd.to_datetime(ts.index)
type(ts.index.values[0])
Out[10]: numpy.datetime64
#转换成功,进一步看一下我们的ts数据
ts.head()
Out[11]:
Month
2049-01-01 112
2049-02-01 118
2049-03-01 132
2049-04-01 129
2049-05-01 121
Name: Passengers, dtype: int64
#查看某日的值既可以使用字符串作为索引,又可以直接使用时间对象作为索引
ts['2049-01-01']
Out[12]: 112
ts[datetime(2049,1,1)]
Out[13]: 112
#查看某年的数据
ts['2049']
Out[15]:
Month
2049-01-01 112
2049-02-01 118
2049-03-01 132
2049-04-01 129
2049-05-01 121
2049-06-01 135
2049-07-01 148
2049-08-01 148
2049-09-01 136
2049-10-01 119
2049-11-01 104
2049-12-01 118
Name: Passengers, dtype: int64三、平稳性检验
1、查看时序图
from pylab import *
plt.plot(ts)
plt.title('Passengers')
show()
从时序图可以明显的看出它具有年周期成分和长期趋势成分,所以可认为是非平稳序列。
2、查看自相关图
from statsmodels.graphics.tsaplots import plot_pacf,plot_acf
plot_acf(ts)
show()
自相关系数并木有很快衰减向0,且具有较大的变化,所以可认为是非平稳序列
3、单位根ADF检验
import statsmodels as sm
temp = np.array(ts)
t = sm.tsa.stattools.adfuller(temp) # ADF检验
output=pd.DataFrame(index=['Test Statistic Value', "p-value", "Lags Used", "Number of Observations Used","Critical Value(1%)","Critical Value(5%)","Critical Value(10%)"],columns=['value'])
output['value']['Test Statistic Value'] = t[0] #t值
output['value']['p-value'] = t[1] #p值
output['value']['Lags Used'] = t[2] #阶数
output['value']['Number of Observations Used'] = t[3]
output['value']['Critical Value(1%)'] = t[4]['1%']
output['value']['Critical Value(5%)'] = t[4]['5%']
output['value']['Critical Value(10%)'] = t[4]['10%']
output
t #
Out[23]:
(0.8153688792060506,
0.991880243437641,
13,
130,
{'1%': -3.4816817173418295,
'10%': -2.578770059171598,
'5%': -2.8840418343195267},
996.692930839019)
Out[22]:
value
Test Statistic Value 0.815369
p-value 0.99188
Lags Used 13
Number of Observations Used 130
Critical Value(1%) -3.48168
Critical Value(5%) -2.88404
Critical Value(10%) -2.57877单位根检验:ADF是一种常用的单位根检验方法,他的原假设为序列具有单位根,即非平稳,对于一个平稳的时序数据,就需要在给定的置信水平上显著,拒绝原假设。以下为检验结果,其p值大于0.99,说明并不能拒绝原假设。
4、对于上述检验方法,可以总结为一个类,如下。
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from pylab import *
plt.rcParams['font.sans-serif']=['SimHei']
rcParams['figure.figsize'] = 10, 5
#data = pd.read_csv('AirPassengers.csv',index_col = [0],header = 0)
data = pd.read_csv('AirPassengers.csv', index_col='Month')
ts = data['Passengers']
ts.index = pd.to_datetime(ts.index)
# 移动平均图
def draw_trend(timeSeries, size):
f = plt.figure(facecolor='white')
# 对size个数据进行移动平均
rol_mean = timeSeries.rolling(window=size).mean()
# 对size个数据进行加权移动平均
rol_weighted_mean = pd.ewma(timeSeries, span=size)
timeSeries.plot(color='blue', label='Original')
rol_mean.plot(color='red', label='Rolling Mean')
rol_weighted_mean.plot(color='black', label='Weighted Rolling Mean')
plt.legend(loc='best')
plt.title('Rolling Mean')
plt.show()
def draw_ts(timeSeries):
f = plt.figure(facecolor='white')
plt.plot(timeSeries,color='blue')
plt.title('Passengers')
plt.show()
def testStationarity(timeSeries):
dftest = adfuller(timeSeries)
# 对上述函数求得的值进行语义描述
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)'%key] = value
return dfoutput
# 自相关和偏相关图,默认阶数为31阶
def draw_acf_pacf(ts, lags=31):
f = plt.figure(facecolor='white')
ax1 = f.add_subplot(211)
plot_acf(ts, lags=31, ax=ax1)
ax2 = f.add_subplot(212)
plot_pacf(ts, lags=31, ax=ax2)
plt.show()四、平稳性处理
由前面的分析可知,该序列是不平稳的,然而平稳性是时间序列分析的前提条件,故我们需要对不平稳的序列进行处理将其转换成平稳的序列。
1、对数变换
对数变换主要是为了减小数据的振动幅度,使其线性规律更加明显。对数变换相当于增加了一个惩罚机制,数据越大其惩罚越大,数据越小惩罚越小。这里强调一下,变换的序列需要满足大于0,小于0的数据不存在对数变换。
ts_log = np.log(ts)
draw_ts(ts_log)
2、平滑法
根据平滑技术的不同,平滑法具体分为移动平均法和指数平均法。移动平均即利用一定时间间隔内的平均值作为某一期的估计值,而指数平均则是用变权的方法来计算均值。
draw_trend(ts_log, 12)
从上图可以发现窗口为12的移动平均能较好的剔除年周期性因素,而指数平均法是对周期内的数据进行了加权,能在一定程度上减小年周期因素,但并不能完全剔除,如要完全剔除可以进一步进行差分操作。
3、差分
时间序列最常用来剔除周期性因素的方法当属差分了,它主要是对等周期间隔的数据进行线性求减。ARIMA模型相对ARMA模型,仅多了差分操作,ARIMA模型几乎是所有时间序列软件都支持的,差分的实现与还原都非常方便。而statsmodel中,对差分的支持不是很好,它不支持高阶和多阶差分。我们可以先用pandas将序列差分好,然后在对差分好的序列进行ARIMA拟合。
diff_14 = ts_log.diff(14)
diff_14.dropna(inplace=True)
testStationarity(diff_14)
Out[52]:
Test Statistic -3.849033
p-value 0.002444
#Lags Used 13.000000
Number of Observations Used 116.000000
Critical Value (1%) -3.488022
Critical Value (5%) -2.886797
Critical Value (10%) -2.580241
dtype: float64从上面的统计检验结果可以看出,经过14阶差分后,该序列满足平稳性的要求了。
4、分解
所谓分解就是将时序数据分离成不同的成分。statsmodels使用的X-11分解过程,它主要将时序数据分离成长期趋势、季节趋势和随机成分。与其它统计软件一样,statsmodels也支持两类分解模型,加法模型和乘法模型,这里我只实现加法,乘法只需将model的参数设置为”multiplicative”即可。
from statsmodels.tsa.seasonal import seasonal_decompose
decomposition = seasonal_decompose(ts_log, model="additive")
f = plt.figure(facecolor='white')
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid
ax1 = f.add_subplot(311)
ax1.plot(trend)
ax2 = f.add_subplot(312)
ax2.plot(seasonal)
ax3 = f.add_subplot(313)
ax3.plot(residual)
五、模型识别
在前面的分析可知,该序列具有明显的年周期与长期成分。对于年周期成分我们使用窗口为12的移动平进行处理,对于长期趋势成分我们采用1阶差分来进行处理。
rol_mean = ts_log.rolling(window=12).mean()
rol_mean.dropna(inplace=True)
ts_diff_1 = rol_mean.diff(1)
ts_diff_1.dropna(inplace=True)
testStationarity(ts_diff_1)
Out[57]:
Test Statistic -2.709577
p-value 0.072396
#Lags Used 12.000000
Number of Observations Used 119.000000
Critical Value (1%) -3.486535
Critical Value (5%) -2.886151
Critical Value (10%) -2.579896
dtype: float64观察其统计量发现该序列在置信水平为95%的区间下并不显著,我们对其进行再次一阶差分。
ts_diff_2 = ts_diff_1.diff(1)
ts_diff_2.dropna(inplace=True)
testStationarity(ts_diff_2)
Out[60]:
Test Statistic -4.443325
p-value 0.000249
#Lags Used 12.000000
Number of Observations Used 118.000000
Critical Value (1%) -3.487022
Critical Value (5%) -2.886363
Critical Value (10%) -2.580009再次差分后的序列其自相关具有快速衰减的特点,t统计量在99%的置信水平下是显著的。
查看自相关和偏自相关的图:
draw_acf_pacf(ts_diff_2, lags=1)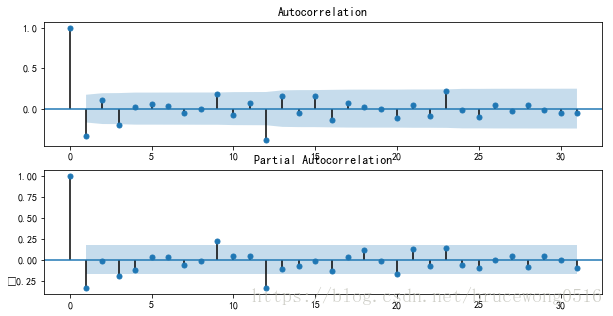
数据平稳后,需要对模型定阶,即确定p、q的阶数。观察上图,发现自相关和偏相系数都存在拖尾的特点,并且他们都具有明显的一阶相关性,所以我们设定p=1, q=1。下面就可以使用ARMA模型进行数据拟合了。
from statsmodels.tsa.arima_model import ARMA
model = ARMA(ts_diff_2, order=(1, 1))
result_arma = model.fit( disp=-1, method='css')六、样本拟合
模型拟合完后,我们就可以对其进行预测了。由于ARMA拟合的是经过相关预处理后的数据,故其预测值需要通过相关逆变换进行还原。
predict_ts = result_arma.predict()
# 一阶差分还原
diff_shift_ts = ts_diff_1.shift(1)
diff_recover_1 = predict_ts.add(diff_shift_ts)
# 再次一阶差分还原
rol_shift_ts = rol_mean.shift(1)
diff_recover = diff_recover_1.add(rol_shift_ts)
# 移动平均还原
rol_sum = ts_log.rolling(window=11).sum()
rol_recover = diff_recover*12 - rol_sum.shift(1)
# 对数还原
log_recover = np.exp(rol_recover)
log_recover.dropna(inplace=True)我们使用均方根误差(RMSE)来评估模型样本内拟合的好坏。利用该准则进行判别时,需要剔除“非预测”数据的影响。
ts = ts[log_recover.index] # 过滤没有预测的记录
plt.figure(facecolor='white')
log_recover.plot(color='blue', label='Predict')
ts.plot(color='red', label='Original')
plt.legend(loc='best')
plt.title('RMSE: %.4f'% np.sqrt(sum((log_recover-ts)**2)/ts.size))
plt.show()
七、完善ARIMA模型
前面提到statsmodels里面的ARIMA模块不支持高阶差分,我们的做法是将差分分离出来,但是这样会多了一步人工还原的操作。基于上述问题,我将差分过程进行了封装,使序列能按照指定的差分列表依次进行差分,并相应的构造了一个还原的方法,实现差分序列的自动还原。
# 差分操作
def diff_ts(ts, d):
global shift_ts_list
# 动态预测第二日的值时所需要的差分序列
global last_data_shift_list
shift_ts_list = []
last_data_shift_list = []
tmp_ts = ts
for i in d:
last_data_shift_list.append(tmp_ts[-i])
print last_data_shift_list
shift_ts = tmp_ts.shift(i)
shift_ts_list.append(shift_ts)
tmp_ts = tmp_ts - shift_ts
tmp_ts.dropna(inplace=True)
return tmp_ts
# 还原操作
def predict_diff_recover(predict_value, d):
if isinstance(predict_value, float):
tmp_data = predict_value
for i in range(len(d)):
tmp_data = tmp_data + last_data_shift_list[-i-1]
elif isinstance(predict_value, np.ndarray):
tmp_data = predict_value[0]
for i in range(len(d)):
tmp_data = tmp_data + last_data_shift_list[-i-1]
else:
tmp_data = predict_value
for i in range(len(d)):
try:
tmp_data = tmp_data.add(shift_ts_list[-i-1])
except:
raise ValueError('What you input is not pd.Series type!')
tmp_data.dropna(inplace=True)
return tmp_data现在我们直接使用差分的方法进行数据处理,并以同样的过程进行数据预测与还原。
diffed_ts = diff_ts(ts_log, d=[12, 1])
model = arima_model(diffed_ts)
model.certain_model(1, 1)
predict_ts = model.properModel.predict()
diff_recover_ts = predict_diff_recover(predict_ts, d=[12, 1])
log_recover = np.exp(diff_recover_ts)
发现这里的预测结果和上一篇的使用12阶移动平均的预测结果一模一样。这是因为12阶移动平均加上一阶差分与直接12阶差分是等价的关系,后者是前者数值的12倍,这个应该不难推导。
对于个数不多的时序数据,我们可以通过观察自相关图和偏相关图来进行模型识别,倘若我们要分析的时序数据量较多,例如要预测每只股票的走势,我们就不可能逐个去调参了。这时我们可以依据BIC准则识别模型的p, q值,通常认为BIC值越小的模型相对更优。这里我简单介绍一下BIC准则,它综合考虑了残差大小和自变量的个数,残差越小BIC值越小,自变量个数越多BIC值越大。个人觉得BIC准则就是对模型过拟合设定了一个标准。
def proper_model(data_ts, maxLag):
init_bic = sys.maxint
init_p = 0
init_q = 0
init_properModel = None
for p in np.arange(maxLag):
for q in np.arange(maxLag):
model = ARMA(data_ts, order=(p, q))
try:
results_ARMA = model.fit(disp=-1, method='css')
except:
continue
bic = results_ARMA.bic
if bic < init_bic:
init_p = p
init_q = q
init_properModel = results_ARMA
init_bic = bic
return init_bic, init_p, init_q, init_properModel相对最优参数识别结果:BIC: -1090.44209358 p: 0 q: 1 , RMSE:11.8817198331。我们发现模型自动识别的参数要比我手动选取的参数更优。
八、滚动预测
所谓滚动预测是指通过添加最新的数据预测第二天的值。对于一个稳定的预测模型,不需要每天都去拟合,我们可以给他设定一个阀值,例如每周拟合一次,该期间只需通过添加最新的数据实现滚动预测即可。基于此我编写了一个名为arima_model的类,主要包含模型自动识别方法,滚动预测的功能,详细代码可以查看附录。数据的动态添加:
from dateutil.relativedelta import relativedelta
def _add_new_data(ts, dat, type='day'):
if type == 'day':
new_index = ts.index[-1] + relativedelta(days=1)
elif type == 'month':
new_index = ts.index[-1] + relativedelta(months=1)
ts[new_index] = dat
def add_today_data(model, ts, data, d, type='day'):
_add_new_data(ts, data, type) # 为原始序列添加数据
# 为滞后序列添加新值
d_ts = diff_ts(ts, d)
model.add_today_data(d_ts[-1], type)
def forecast_next_day_data(model, type='day'):
if model == None:
raise ValueError('No model fit before')
fc = model.forecast_next_day_value(type)
return predict_diff_recover(fc, [12, 1])现在我们就可以使用滚动预测的方法向外预测了,取1957年之前的数据作为训练数据,其后的数据作为测试,并设定模型每第七天就会重新拟合一次。这里的diffed_ts对象会随着add_today_data方法自动添加数据,这是由于它与add_today_data方法中的d_ts指向的同一对象,该对象会动态的添加数据。
ts_train = ts_log[:'1956-12']
ts_test = ts_log['1957-1':]
diffed_ts = diff_ts(ts_train, [12, 1])
forecast_list = []
for i, dta in enumerate(ts_test):
if i%7 == 0:
model = arima_model(diffed_ts)
model.certain_model(1, 1)
forecast_data = forecast_next_day_data(model, type='month')
forecast_list.append(forecast_data)
add_today_data(model, ts_train, dta, [12, 1], type='month')
predict_ts = pd.Series(data=forecast_list, index=ts['1957-1':].index)
log_recover = np.exp(predict_ts)
original_ts = ts['1957-1':]动态预测的均方根误差为:14.6479,与前面样本内拟合的均方根误差相差不大,说明模型并没有过拟合,并且整体预测效果都较好。
九、模型序列化
在进行动态预测时,我们不希望将整个模型一直在内存中运行,而是希望有新的数据到来时才启动该模型。这时我们就应该把整个模型从内存导出到硬盘中,而序列化正好能满足该要求,使用pickle模块建模型存入和导出。
import pickle
#将对象model_arma保存到文件file中去
with open('model_arma.pkl','wb') as f:
model_arma = pickle.dump(result_arma,f,-1)
#从file中读取原来的python对象model_arma;
with open('model_arma.pkl','rb') as f:
model_arma = pickle.load(f)