R语言下的自然语言处理学习笔记一
第一章 基础
1 安装
R 是一个有着统计分析功能及强大作图功能的软件系统, 是由奥克兰大学统计学系的Ross Ihaka 和Robert Gentleman 共同创立(两个名字都是R打头,所以叫R语言)。据说R语言很像S语言,但是我也不知道S语言是什么样的。
安装R的工具可以去官网http://mirror.bjtu.edu.cn/cran/我的安装环境是Win7 32位,安装的时候会自动帮你选择32位还是64位
2 R的自然语言处理包
根据R语言入门教程,Journal of Statistical Software的Text Mining Infrastructure in R,对R语言下的自然语言做一些了解。
我们可能需要的几个包是emu,wordnet,KEA,openNLP,RWeka,Snowball,Rstem,KoNLP,tm,lsa,topicmodels,RTextTools,textcat,corpora,zipfR,maxent,TextRegression,wordcloud。挺多的,任务挺艰巨的,不过初学嘛,先过个手知道个大概,到要实际用的时候再详细了解某一个或几个。
演示一下安装R语言的程序包使用函数 install.packages()。
使用的时候会提示选择哪个镜像,我猜都是有钱又有品味的几个单位在维护国内镜像,北大,中科院,中国科技大学,厦门大学什么的。看着距离选择一个吧。

当我回车的时候报错了,具体是这样的

第一次没成功是因为install.packages()的()里需要加引号,第二次是提示版本太高不兼容,官网装的最新的版本3.0.3果断是兼容性还不行啊,果断降版本到2.15.3。
再次尝试安装各种包,不过还是出现了错误,报错版本不对
> install.packages('emu')
--- 在此連線階段时请选用CRAN的鏡子 ---
警告信息:
package ‘emu’ is not available (for R version2.15.3)
好吧,emu的包是一个用于创建,收集,处理和语音数据库的工具包。说实话我是用不上的,而且它的版本要求还很奇怪,最新的不行,最稳定的不行,那就算了吧。只对用的上的包进行安装尝试。
根据需要安装Snowball,当然先使用一个小操作Ctrl+L,清屏一下,然后方向键↑调出之前的指令。
install.packages('Snowball')
install.packages('rmmseg4j')
install.packages('tm')

好像会自动下载依赖包,挺好的。

下载完包就可以进入测试步骤了。
3 在R语言下进行简单的自然语言处理
3.1 Snowball包下的英文的词干化
> library(Snowball)
> SnowballStemmer(c('functions', 'stemming','liked', 'doing'))
[1] "function""stem" "like" "do"
3.2 rmmseg4j包下的中文分词
> library(rmmseg4j)
Loading required package: rJava
> mmseg4j(' 花儿为什么这样红')
[1] "花儿 为什么 这样 红"
3.3 tm包下的文本挖掘
1 Crops操作
在 tm 中主要的管理文件的结构被称为语料库Crops,其下分动态语料库(Volatile Corpus,作为 R 对象保存在内存中)和静态语料库(Permanent Corpus,R 外部保存)。在语料库构成中,x 必须有一个说明资料来源(input location)的源对象(Source Object)。
这个意思就是对于某个Crops变量,必须包含元素(资料来源x,内容解析器readerControl,使用静态语料库条件下内存对象外的资料来源(比如数据库)dbControl)
对于一个动态语料库的样例
> txt <- system.file("texts","txt", package = "tm")
> (ovid <- Corpus(DirSource(txt),
+ readerControl = list(language ="lat")))
这三个部分的详细是这样的:
资料来源x:
txt <- system.file("texts","txt", package = "tm")
意思是txt是一个地址,指向‘C:/Program Files/R/R-3.0.3/library/tm/texts/txt’,是一个叫txt的文件夹,里面有5个.txt文件。
当然也可以写成txt=‘C:/Program Files/R/R-3.0.3/library/tm/texts/txt’,就是提供一个你放crops的文件目录。
内容解析器readerControl:
readerControl = list(language ="lat")
完整的应该是readerControl = list(reader = x$DefaultReader, language = "en")
使用getReaders()可以看到有哪些类型的文档时可以被解析的
[1]"readDOC" "readPDF" "readReut21578XML"
[4]"readReut21578XMLasPlain" "readPlain" "readRCV1"
[7]"readRCV1asPlain" "readTabular" "readXML"
对于每一类源,都会有自己默认的 reader,可以缺省。比如对DirSource来说,默认读入输入文件并把内容解释为文本,使用readPlain。第二个 language 就比较简单了,即字符集,比如可能是 UTF-8 字符集。例子里用的是’lat’,是拉丁字符。
因为是动态语料库的示例所以没有dbControl。
执行上面的示例会得到:
A corpus with 5 text documents
换一个示例
install.packages('XML')
library(tm)
reut21578 <-system.file("texts", "crude", package = "tm")
reuters <- Corpus(DirSource(reut21578),readerControl = list(reader = readReut21578XML))
reuters
详情是reut21578=’C:/ProgramFiles/R/R-3.0.3/library/tm/texts/ crude ‘
文档类型是XML文件( 需要install.packages('XML'))
得到的结果是:
A corpus with 20 text documents是一个20个文本文件的语料集。
如果需要得到某一篇的文档的内容,可以使用编号和文档名,类似于reuters[[2]]和reuters[['reut-00002.xml']]是等价的。
2 语料整理
(1) 转化为纯文本
在 reuters 这个语料库中保存的是 XML 格式的文本,XML 格式文本没有分析的意义,我
们只需要使用其中的文本内容。这个操作可以使用 as.PlainTextDocument() 函数来实现:
reuters <- tm_map(reuters, as.PlainTextDocument)
这样就不会有那些标签了,反正那些标签也不包含语义。
(2) 去除多余的空白
reuters<- tm_map(reuters, stripWhitespace)
类似于Java的trim和Python里的strip
(3) 小写变化
reuters<- tm_map(reuters, tolower)
(4) 停止词去除
reuters<- tm_map(reuters, removeWords, stopwords("english"))
(5) 元数据管理
元数据是为了标记语料库的附加信息,最简单的使用方式就是调用 meta() 函数。文档会被预先被定义一些属性,比如作者信息,但也可能是任意自定义的元数据标签。这些附加的元
据标签都是独立的附加在单个文档上。从语料库的视角上看,这些元数据标签被独立的存储在每个文档上。
继续之前的那个例子使用meta(crude[[1]]得到文档标签可以看到,默认的Creator那一项是空的,但是可以通过
DublinCore(reuters[[1]], tag ="creator") <- "LiTC"
meta(reuters, tag = "test", type ="corpus") <- "test meta"
来指定creator和test项目
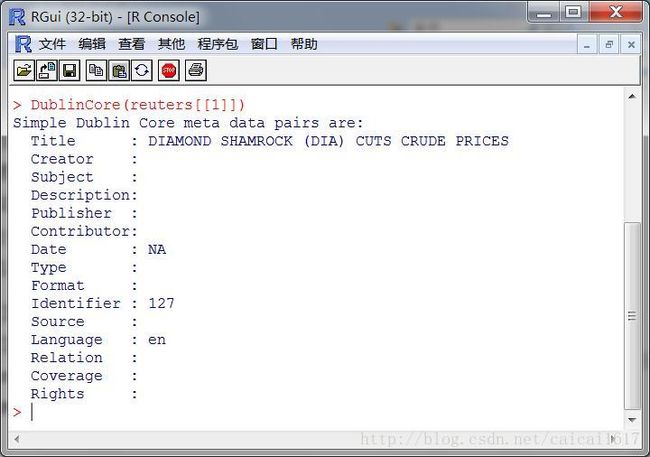
修改元组信息后

这是对于单文档的,对于语料集reuters这样的也可以设定标签
meta(reuters,tag = "creator", type = "corpus") <- "LiTC"
meta(reuters,tag = "test", type = "corpus") <- "test meta"
meta(reuters, type ="corpus") 
(6) 生成词文档(文档词)矩阵
dtm <- DocumentTermMatrix(reuters)
inspect(dtm[1:10,1:9])
从结果看,确实很稀疏啊

词频筛选,找到出现5次以上的词
findFreqTerms(dtm, 5)

或者找到相关性,比如对于 opec,找到相关系数在 0.8 以上的条目,使用 findAssocs():
findAssocs(dtm, "opec", 0.8)
结果:
meeting 15.8 oil emergency analysts buyers
0.88 0.85 0.85 0.83 0.82 0.80
对稀疏矩阵进行主成分提取:
inspect(removeSparseTerms(dtm, 0.1))#除了词频统计中低于90%的稀疏条目项。
得到的矩阵稀疏比例为0,可以看到oil和reuter是最高频的两个词,每篇文档都出现了。

(7) 词典
(d <- Dictionary(c("prices","crude", "oil")))#字典d里放了3个元素
attr(d,"class")#查看d的类型是"Dictionary""character"
inspect(DocumentTermMatrix(reuters,list(dictionary = d)))#将字典d里的元素放到list里面,检查它们在retuers里的文档矩阵
试着调整一下做一下测试,没有问题的。

4 网页数据处理
library(XML)
doc<- xmlParse(system.file("exampleData", "tagnames.xml",package = "XML"))#一个测试文件
els<- getNodeSet(doc, "/doc//a[@status]")#读到els
els#可以看到els有两个节点
sapply(els,function(el) xmlGetAttr(el, "status"))#处理得到网页内容
得到的结果是

第二章 具体任务
1 文本聚类
library(tm)#导入text mining包
data(acq)#acq: C:\ProgramFiles\R\R-2.15.3\library\tm\texts\acq,包括了50篇文档
data(crude)#crude: C:\ProgramFiles\R\R-2.15.3\library\tm\texts\crude,20篇文档
m<- c(acq, crude)#acq和crude合并到一起记为m
dtm<- DocumentTermMatrix(m)#m的文档词矩阵
dtm<- removeSparseTerms(dtm, 0.8)#删除词频低于0.2的低频词
inspect(dtm[1:5,1:5])#得到一个小的样例文档词矩阵
dist_dtm<- dissimilarity(dtm, method = 'cosine')#对dtm矩阵使用余弦相似度计算距离
hc<- hclust(dist_dtm, method = 'ave')#使用HAC层次聚类,HAC使用平均相似度作为判断标准
plot(hc,xlab = '')#画图显示层次聚类结果

也可以使用k-means聚类
km<-kmeans(dist_dtm,centers=3)
结果也还可以。
2 主题模型
本来准备写在这里的,后来发现一时半会搞不定啊,只能先按下不表,等之后发个详细的学习笔记二了。