中,另外,底部的杂图(无翻译文字)放在每个中。因此就很明了怎么提取相应的全部图片链接了。
JAVA代码:
//提取文章内所有翻译图片链接
List photoURLs = page.getHtml().xpath("//table[@class='tr-caption-container']/tbody/tr/td/a")
.css("img", "src").all();
//添加文章内底部杂图链接
photoURLs.addAll(page.getHtml().xpath("//div[@class='separator']/a").css("img", "src").all());
最后一个问题就是如何将每张图片保存到本地了。也很简单,将图片URL拿来,输入流中,byte输出存储就行了。以下是存储方法:
/**
* @param urlStr 图片URL
* @param filename 图片文件名
* @param savePath 存储路径
* @throws IOException 读写异常
*/
static void download(String urlStr, String filename, String savePath) throws IOException {
URL url = new URL(urlStr);
//设置本地SSR代理
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress("127.0.0.1", 1080));
//打开url连接
URLConnection connection = url.openConnection(proxy);
//请求超时时间
connection.setConnectTimeout(5000);
//输入流
InputStream in = connection.getInputStream();
//缓冲数据
byte[] bytes = new byte[2048];
//数据长度
int len;
//文件
File file = new File(savePath);
if (!file.exists()) {
file.mkdirs();
}
OutputStream out = new FileOutputStream(file.getPath() + "\\" + filename);
//先读到bytes中
while ((len = in.read(bytes)) != -1) {
//再从bytes中写入文件
out.write(bytes, 0, len);
}
//关闭IO
out.close();
in.close();
}
现在已经万事俱备,只用编写WebMagic中的核心处理方法void process(Page page)就行了。以下是该类的完整实现:
public class HornyDragonBlogProcessor implements PageProcessor {
private static final String URL_POST = "https://hornydragon\\.blogspot\\.com/\\d{4}/\\d{2}/\\d{1,5}[\\w]*\\.html";
private static int INDEX_PHOTO = 0;
/**
* 正则表达式,以提取字符串中数字
*/
private static Pattern pattern = Pattern.compile("[^0-9]");
private List pageURLList = new ArrayList<>();
private Site site = Site
.me()
.setRetryTimes(3)
.setCycleRetryTimes(3)
.setSleepTime(1000)
.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
private void getPageURLList() throws Exception {
pageURLList.addAll(Selenium.getPageList());
}
@Override
public void process(Page page) {
//列表页
if (!page.getUrl().regex(URL_POST).match()) {
List detailURL = page.getHtml().xpath("//div[@class='blog-posts']").links().regex(URL_POST).all();
System.out.println("size:" + detailURL.size());
page.addTargetRequests(detailURL);
} else {//文章页
//提取文章编号
int pageNo = Integer.parseInt(pattern.matcher(page.getHtml().xpath("//div[@class='post hentry']/h3/text()").toString()).replaceAll("").trim());
//提取文章发布时间
ZonedDateTime publishedTime = ZonedDateTime.parse(page.getHtml().xpath("//div[@class='post hentry']/meta/@content").toString());
//提取文章内所有翻译图片链接
List photoURLs = page.getHtml().xpath("//table[@class='tr-caption-container']/tbody/tr/td/a")
.css("img", "src").all();
//添加文章内底部杂图链接
photoURLs.addAll(page.getHtml().xpath("//div[@class='separator']/a").css("img", "src").all());
String title = page.getHtml().xpath("//div[@class='post hentry']/h3/text()").toString();
Matcher m = pattern.matcher(title);
String pageURL = page.getUrl().toString();
String pageYear = pageURL.split("/")[pageURL.split("/").length - 3];
int pageMonth = Integer.parseInt(pageURL.split("/")[pageURL.split("/").length - 2]);
try {
//遍历单页内所有图片
for (String s : photoURLs) {
//438之前的文章图片链接不带协议前缀,检测加上,不然URL类无法解析
if (s.startsWith("//")) {
s = "https:" + s;
}
String[] nickNames = s.split("/");
//存储到硬盘
SpiderDownload.download(s, nickNames[nickNames.length - 1], "F:\\HornyDragonBlogImage\\" + pageYear + "\\" + m.replaceAll("").trim() + "\\");
//持久化入数据库
SpiderDownload.save2DB(new Image(pageMonth, s, publishedTime, pageNo, Integer.parseInt(pageYear)));
System.out.println("第" + (INDEX_PHOTO++) + "张");
}
} catch (Exception e) {
e.printStackTrace();
}
}
//仅加载一次全部列表
if (pageURLList.isEmpty()) {
try {
getPageURLList();
page.addTargetRequests(pageURLList);
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] arv) {
Spider spider = Spider.create(new HornyDragonBlogProcessor())
.addUrl("https://hornydragon.blogspot.com/search/label/%E9%9B%9C%E4%B8%83%E9%9B%9C%E5%85%AB%E7%9F%AD%E7%AF%87%E6%BC%AB%E7%95%AB%E7%BF%BB%E8%AD%AF?&max-results=30")
.thread(300);
//设置爬虫本地SSR代理
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("127.0.0.1", 1080)));
spider.setDownloader(httpClientDownloader);
spider.run();
}
}
关于存入数据库部分就不说了,就是基础。整个项目已经传到github中了,欢迎指正
整个爬取总共花了十分钟左右?一半时间都花在线程休眠那里 - - ,之后有时间把PhantomJS 换了,直接上浏览器的无头模式也许更精简
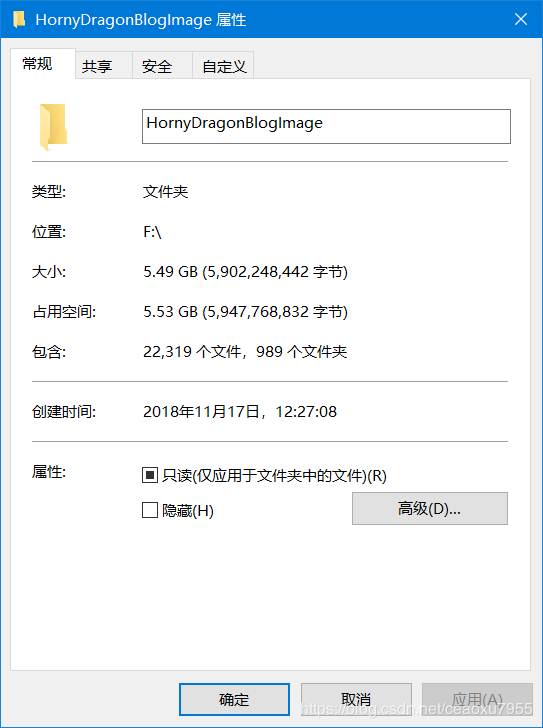
爬下了两万多张图片,5个G左右。惊了已经,默默向好色龍表以最诚恳地敬意
你可能感兴趣的:(爬虫)
Java爬虫-WebMagic爬取博客图片(好色龍的網路觀察日誌)
WebMagic爬取博客图片
最近在学习java爬虫,接触到WebMagic框架,正好拿我喜爱的博客来练习,希望龙哥(博主)不要责备我~~
博客链接: 好色龍的網路觀察日誌 ,超级有趣的翻译漫画,持续了七年之久,惊叹!访问需要科学上网
不多说,上过程。
-
创建Maven项目(我用的是IDEA),在pom.xml中添加WebMagic依赖:
`us.codecraft webmagic-core 0.7.3 us.codecraft webmagic-extension 0.7.3 org.slf4j slf4j-log4j12 而如何使用WebMagic请访问其官网,上有中文文档。
中文文档上手就是快啊 -
揣摩要爬取博客的HTML代码。我仅想爬取他的雜七雜八短篇漫畫翻譯中的图片,那么我们找到相关列表页面,看到文章列表在
之下,那么我们只要将页面中这部分连接提取出来就行了。
接着我们看每篇单独文章的链接以编写正则表达式匹配。容易发现博文链接格式是这样的https://hornydragon.blogspot.com/2018/11/1014.html,其中2018,11,1014是可变的,分别是发布的年份,月份,博文编号。那就可以编写正则表达式:https://hornydragon\.blogspot\.com/\d{4}/\d{2}/\d{1,5}[\w]*\.html。(也许会想为什么最后是四位数字,还需要加[\w]*?因为我发现有时候博主推送的博文会在最后有test等字符跟着,这是以防出现的万一)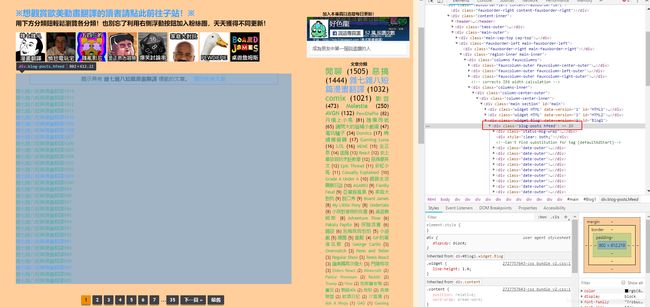
现在一个列表页我们已经能获得上面全部文章的链接了,那么重复这个过程,将其他列表页都弄进来就结束了噻,正当我点击看到第二页列表页的时候,发现有些不对劲。第一列表页的链接是这样的:
https://hornydragon.blogspot.com/search/label/%E9%9B%9C%E4%B8%83%E9%9B%9C%E5%85%AB%E7%9F%AD%E7%AF%87%E6%BC%AB%E7%95%AB%E7%BF%BB%E8%AD%AF?&max-results=30,第二页却是这样的:https://hornydragon.blogspot.com/search/label/%E9%9B%9C%E4%B8%83%E9%9B%9C%E5%85%AB%E7%9F%AD%E7%AF%87%E6%BC%AB%E7%95%AB%E7%BF%BB%E8%AD%AF?updated-max=2018-06-05T17%3A24%3A00%2B08%3A00&max-results=30#PageNo=2。多了两部分,PageNo还好弄,updated-max跟日期就不好弄了,因为每推送一篇博文都会刷新这个日期。最大的问题其实还不是在这,WebMagic爬取是利用表达式筛选URL,这样我们可以找到页脚上的下一页标签,不断地筛选并获取下一列表页的链接就行了。当我想琢磨下一页链接的套路以编写正则表达式时,发现这博客下一页链接使用JS函数捣鼓出来跳转的,那意味着我们就不能简单地拿到之后的列表页链接了。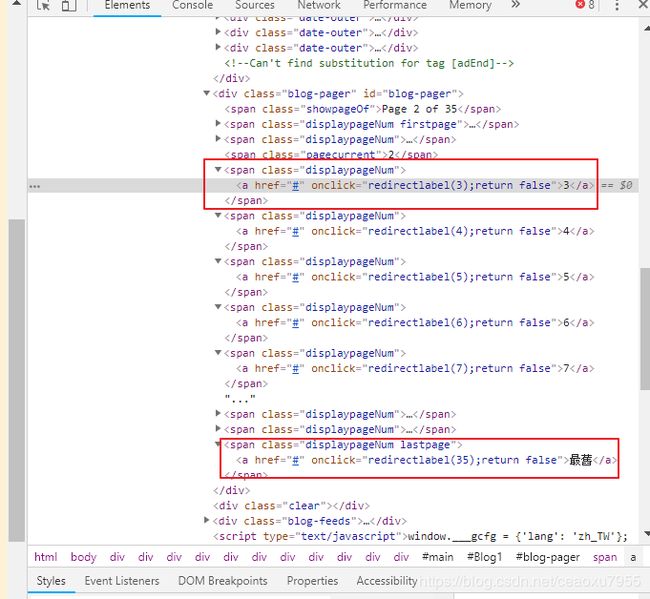
于是我开始寻找如何写代码来运行JS脚本。接触到了Selenium,其是用来自动化测试,搭配相应的WebDriver可在相应的浏览器中执行JS脚本。我使用的版本是v3.141.59。WebDriver版本为ChromeDriver v2.44(Chrome浏览器版本为 v70.0.3538.102)。这个2.44版本理论上支持所有 v69-71的Chrome浏览器。若是不太了解可参阅这篇博客。
接下来在pom.xml中添加Selenium依赖:org.seleniumhq.selenium selenium-java 3.141.59 当我对Selenium做Test时候,总是报错:
WebDriverError: unknown error: chrome failed to start。一直网上找寻答案未果,因为每一项都配置好的。最后再想一切配置没问题代码没问题,为什么启动不了Chrome呢。然后我用管理员身份运行IDEA时候再运行,启动成功了。真是对Windows无语睿智OS。
启动了Chrome,能自动打开了页面,自动运行的JS脚本。但是这不是我想要的,因为爬虫程序你不可能还显式的调用弹出个浏览器来吧,一会拖慢程序运行,二这也太蠢了吧。随即顺着Selenium找下去,发现和其有个搭配的PhantomJS ,可以只运行浏览器内核,而不用弹出浏览器。该死,写到这里时我随便再看了一点相关信息,PhantomJS 这家伙已经停止更新了,用的时候没注意到。而且新版的Chrome或Firefox他们已经有了无头模式(Headless,无界面,使用脚本进行操作)。你完全可以省掉PhantomJS 配置安装这部分,而直接用无头版本的WebDriver就行了!
接着添加PhantomJS 的依赖com.codeborne phantomjsdriver 1.4.4 再官网下载
最新的PhantomJS 工具,解压到本地后就可以编写相应类的代码了。以下是Selenium配合PhantomJS 来获取爬取博客的所有列表页链接的方法:static ListgetPageList() throws Exception { //加载phantomjs,路径自定义 System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe"); DesiredCapabilities caps = new DesiredCapabilities(); //设置访问代理 String proxyIpAndPort = "127.0.0.1:1080"; Proxy proxy = new Proxy(); proxy.setHttpProxy(proxyIpAndPort).setFtpProxy(proxyIpAndPort).setSocksProxy(proxyIpAndPort); caps.setCapability(CapabilityType.ForSeleniumServer.AVOIDING_PROXY, true); caps.setCapability(CapabilityType.ForSeleniumServer.ONLY_PROXYING_SELENIUM_TRAFFIC, true); caps.setCapability(CapabilityType.PROXY, proxy); WebDriver driver = new PhantomJSDriver(caps); driver.get("https://hornydragon.blogspot.com/search/label/%E9%9B%9C%E4%B8%83%E9%9B%9C%E5%85%AB%E7%9F%AD%E7%AF%87%E6%BC%AB%E7%95%AB%E7%BF%BB%E8%AD%AF?&max-results=30"); System.out.println(driver.getTitle()); JavascriptExecutor js = (JavascriptExecutor) driver; Thread.sleep(2000); //获取最后一页页码 WebElement element = driver.findElement(By.cssSelector(".displaypageNum.lastpage a")); String onclickSrt = element.getAttribute("onclick"); int pageNum = Integer.parseInt(pattern.matcher(onclickSrt).replaceAll("").trim()); System.out.println("Total Page num: " + pageNum); List pageList = new ArrayList<>(); for (int i = 2; i < pageNum + 1; i++) { //在网页中执行JS代码,此代码为跳转页面 js.executeScript("redirectlabel(" + i + ");"); //停5秒,以等待页面加载 Thread.sleep(5000); pageList.add(driver.getCurrentUrl()); } driver.close(); driver.quit(); return pageList; } 因为我的SSR和电脑速度并不是很快,所以设置了5秒的线程sleep,你可以根据自身情况设定。整个爬虫耗时最长的就是这个
Thread.sleep(5000);了。。-_-|- 有了列表页,我们再找文章页中想要爬取图片的元素定位就行了。再回去看博客文章详情页的源码。很明显,所有图片都在中,而每张翻译的图片单独放在一个