使用scrapy模拟登录知乎
1、模拟登录
一般在网站要求强制登陆,并且cookie无法正常访问时,可以进行模拟登录。
2、如何模拟登录
(1)、首先要分析,进行知乎登录验证的时候,知乎服务器需要我们提交什么数据。
(2)、接着这些数据提交到哪个地址。
(3)、是否有验证码,有则进行验证码验证 。
那么问题来了,
(1)、假如有验证码,我们需要分析验证码是如何获取的?
(2)、如何判断验证码的正确性?
根据经验来看,验证码的图片啊展示有两种。
(1)、固定接口,只需刷新接口,每次得到的就是不同的验证码。(如优信二手车)
(2)、验证码url地址和图片是一一对应的,访问同一个url图片地址,得到的就是同一张验证码图片。
现在我们再回头来看知乎验证码是如何弹出的:
(1)、当我们点击从首页点击登录时,会出现一系列请求。通过观察以及登录后尝试后得出如下结论:
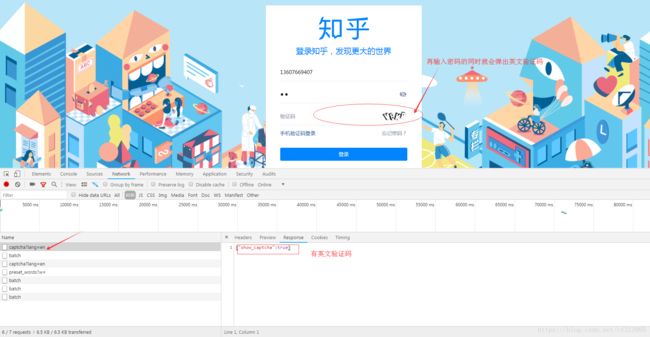
①当对网址https://www.zhihu.com/api/v3/oauth/captcha?lang=en发起一个get请求时,它的响应{“show_captcha”: false/true}决定了是否有英文验证码。
②当对网址https://www.zhihu.com/api/v3/oauth/captcha?lang=cn发起一个get请求时,它的响应{“show_captcha”: false/true}决定了是否有中文验证码。
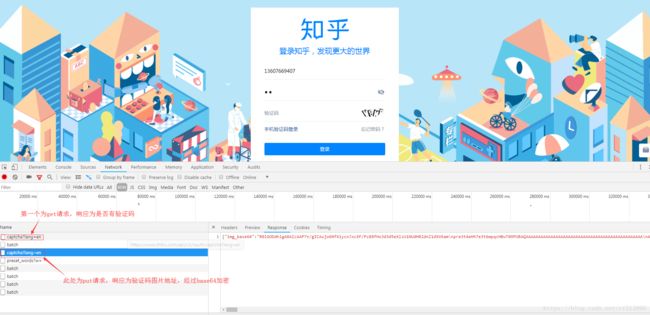
(2)、如果有验证码(不论中英文验证码),继续向https://www.zhihu.com/api/v3/oauth/captcha?lang=en/cn发送一个PUT请求,用于获取验证码图片的地址:{“image_base64”: “fasdguasudgiaufsdofgasdpof…”}
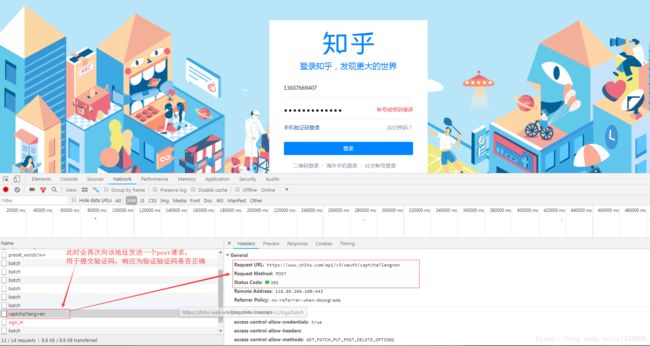
(3)当账号密码输入完毕,验证码输入完毕,再次点击登录,则会继续向该地址发送一个post请求,用于验证输入的验证码是否正确。
搞明白了这些,思路有了,那么我们可以进一步思考逻辑了。
3、思路逻辑实现
(1)重写spider下爬虫文件的start_requests方法,先不去遍历start_urls这个列表,而是先去请求是否有验证码。即起始请求向用于决定验证码是否出现的网址发起请求,先知道此次登录是否有验证码。
(2)解析用于获取是否有验证码的get请求,获取show_captcha的值。
(3)此时:
①若有验证码,继续向https://www.zhihu.com/api/v3/oauth/captcha?lang=en/cn发起put请求,获取验证码图片的地址,然后保存图片进行识别,以便登录。
②若无验证码,那么万事大吉,直接进行登录即可。
(4)对登录网址的post请求发起访问,并携带参数进行登录。
4、代码实现
(1)重写spider下爬虫文件的start_requests方法,先不去遍历start_urls这个列表,而是先去请求是否有验证码。即起始请求向用于决定验证码是否出现的网址发起请求,先知道此次登录是否有验证码。直接将验证码地址写死,写成英文验证的方式。
login_url='https://www.zhihu.com/api/v3/oauth/sign_in'
captcha_url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en'
def start_requests(self):
#重写start_requests这个方法,不去遍历start_urls这个列表了,而是先去请求验证码。
#起始请求是向captcha_url发送get请求,先知道是否有验证码。
yield scrapy.Request(url=self.captcha_url,callback=self.parse_get_captcha)
def parse_get_captcha(self,response):
'''
解析验证码的get请求,获取show_captcha的值。
:param response:
:return:
'''
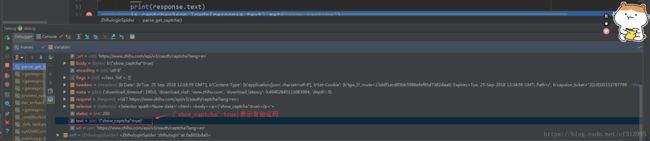
print(response.text)
(2)有验证码
①继续向https://www.zhihu.com/api/v3/oauth/captcha?lang=en/cn发起put请求,获取验证码图片的地址。
#response.text获取的是字符串,为了方便取值,使用json的loads()方法反序列化成字典。
is_captcha=json.loads(response.text).get("show_captcha")
if is_captcha:
print('有验证码')
#继续向captcha_url发送put请求,获取验证码图片的加密地址。
yield scrapy.Request(url=self.captcha_url,method='PUT',callback=self.parse_image_url)
②对加密过的图片地址进行解密,然后保存图片进行识别,以便登录。
import base64
def parse_image_url(self,response):
'''
解析验证码的put请求,获取图片的加密地址。
:param response:
:return:
'''
img_url=json.loads(response.text).get("img_base64")
#对加密图片进行解密,获取原始地址
img_data=base64.b64decode(img_url)
#根据得到的Bytes-like对象,创建一个字节码对象(bytes对象)
img_real_url=BytesIO(img_data)
#利用Image去请求这个图片,获得图片对象
img=Image.open(img_real_url)
img.save('captcha.png')
#调用云打码平台接口进行识别英文字母
result=yan_zheng('captcha.png')[1]
#继续发起一个post请求,获取验证码识别的是否正确
yield scrapy.FormRequest(
url=self.captcha_url,
callback=self.parse_post_captcha,
formdata={
'input_text':str(result)
}
)
③ 获取验证码的识别结果。
def parse_post_captcha(self,response):
'''
解析验证码的post请求,获取验证码的识别结果,输入的验证码是错误还是正确。
:param response:
:return:
'''
result=json.loads(response.text).get("success",'')
if result:
print('验证码输入正确')
#访问这个sign_in这个url进行登录
post_data={
'username':'你的账号',
'password':'你的密码'
}
#此时,需要现在settings.py文件中添加scrapy允许处理的状态码(即添加HTTPERROR_ALLOWED_CODES=[400,600]),因为scrapy默认只处理[200,300]之间的状态码。
yield scrapy.FormRequest(
url=self.login_url,
formdata=post_data,
callback=self.parse_login
)
④、对登录网址的post请求发起访问,并携带参数进行登录。此时报了一个错误,告诉我们post请求丢失了一个叫grant_type的参数。

⑤我们假设grant_type的参数对登录没有影响,设定一个空值(即’grant_type’:’’)。再次尝试访问。
⑥然而还是不可以,那么就说明这个参数是个重要的部分。此时回到知乎,对这个参数进行查找,然而并没找到。
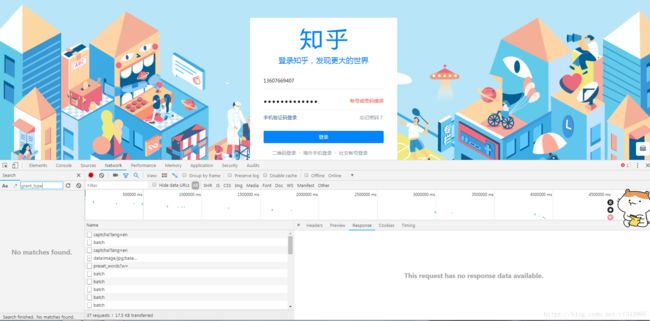
⑦此时我们尝试截取grant_type的部分进行搜索。尝试搜索grant。中状元,救岳母,果然刚刚好。搜索到了一条记录,我们点进去后搜索grant,发现了grantType的值赋值给了digits,并做了严格比较(js中’===’,判断两边值是否相等,类型是否相等,两者皆相等为true),此处做了一个三元运算。判断digits和grantType的值和类型是否相等,是的话e.phoneNo = e.username
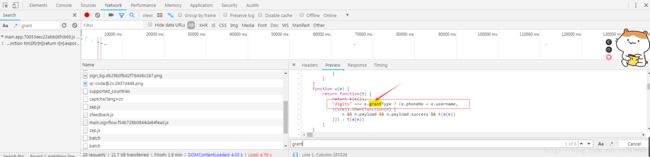
⑧那么我们继续寻找digits,看看它到底是何方神圣。一路向西寻找,发现了如下图所示,男人的第六感告诉我就是它了。它展示了三种登录类型。1.邮箱登录 type:email 2.手机短信验证 type:sms 3.账号密码登录 type:password

⑨我们是密码登录,所以在登录的post请求的参数grant_type加上password。即
post_data = {
'username': '13607669407',
'password': 'caifei313995',
# 三种登录方式:1.邮箱登录 type:email 2.短信验证 type:sms 3.账号密码登录 type:password
'grant_type': 'password'
}
①有了grant_type这个参数,我们再次运行。发现仍旧报错。告诉我们缺少一个client_id的参数。

②同样的我们继续查找,发现并没有client_id这个参数,老办法,继续部分查找,查找client有结果了,几次查找之下,发现它变成了clientId。

③同理,将这个参数填写完毕继续运行,发现仍旧报错缺少timestamp这个参数。发现刚才找的clientId旁边就有这个参数,经过逻辑分析,缜密思考,就是它了。值得注意的是js中获取的额时间戳是十三位整数,所以我们python中获取的时间戳应该做些处理。
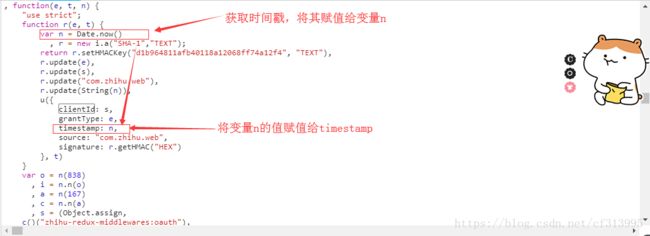
tm=str(int(time.time())*1000)
post_data={
'username':'13607669407',
'password':'caifei313995',
#三种登录方式:1.邮箱登录 type:email 2.短信验证 type:sms 3.账号密码登录 type:password
'grant_type':'password'
'client_id':'c3cef7c66a1843f8b3a9e6a1e3160e20',
'timestamp':tm
}
④同理,将这个参数填写完毕继续运行,发现仍旧报错缺少source这个参数。刚才找的clientId,timestamp旁边就有这个参数。且是个固定值。

⑤同理,将这个参数填写完毕继续运行,发现仍旧报错缺少signature这个参数。刚才找的clientId,timestamp旁边就有这个参数。查看一下,发现它是一个用SHA-1加密方法加密后获得的数据。
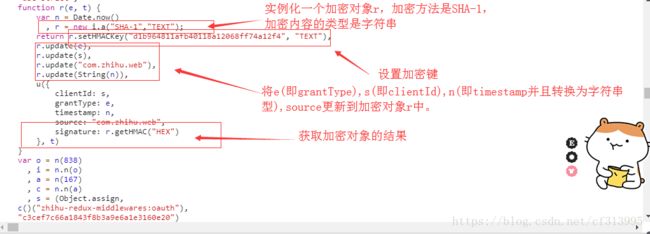
import hmac
from hashlib import sha1
msg参数就是用来填写你要加密的字符串。但是msg只能设置一个字符串,如果需要对多个字符串进行加密,需要使用update()方法。
hm = hmac.new(b'd1b964811afb40118a12068ff74a12f4', msg=None, digestmod=sha1)
# 按照js中顺序,添加四个参数,顺序不一样,加密结果也不一样。
hm.update(b'password')
hm.update(b'c3cef7c66a1843f8b3a9e6a1e3160e20')
hm.update(b'com.zhihu.web')
hm.update(tm.encode())
# 获取加密后的结果
sign = hm.hexdigest()
post_data={
'username':'你的账号',
'password':'你的密码',
#三种登录方式:1.邮箱登录 type:email 2.短信验证 type:sms 3.账号密码登录 type:password
'grant_type':'password'
'client_id':'c3cef7c66a1843f8b3a9e6a1e3160e20',
'source':'com.zhihu.web',
'timestamp':tm,
'signature':sign
}
⑥此时,再次向登录网址发起post请求,返回的是一个json字符串。
5、上面是把验证码出现情况为英文写死的。当然也可以对出现为中文的汉字点选的验证码情况做一个分析。
(1)、打开开发者工具。观察captcha?lang=cn这个请求,此时输入用户名和密码后,弹出的是一个汉字点选的中文验证码。
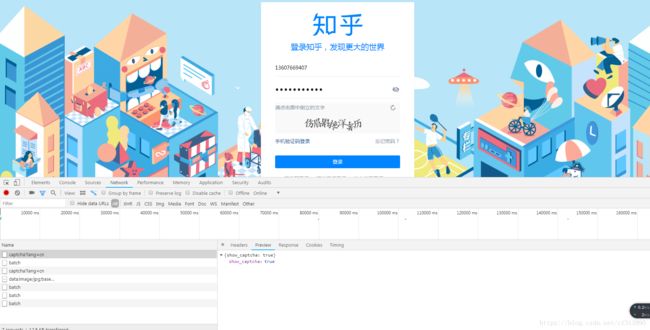
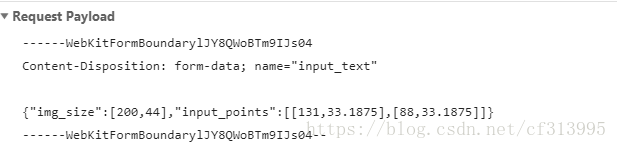
(2)我们先点选个错误的验证码进行提交,观察他的验证验证码的失败的post请求。如下图

发现它有一个img_size参数,推测应该是验证码图片的大小(用qq的热键对验证码截图,证实了我们推测正确)。另外还有一个input_point参数,这是一个列表,列表里面有两个值。推测是根据我们点选的两个倒立汉字而生成的两个坐标点。
(3)另外观察我们点选的汉字。会发现每一个汉字都有一个固定大小的区间,只要你点的是在这个倒立汉字的固定区间大小内,无论是边缘还是中心位置都可以识别成功。且每次刷新验证码图片,他都是在这个图片大小(即img_size)的范围内,每个汉字的大概位置也是没有太大变化的。
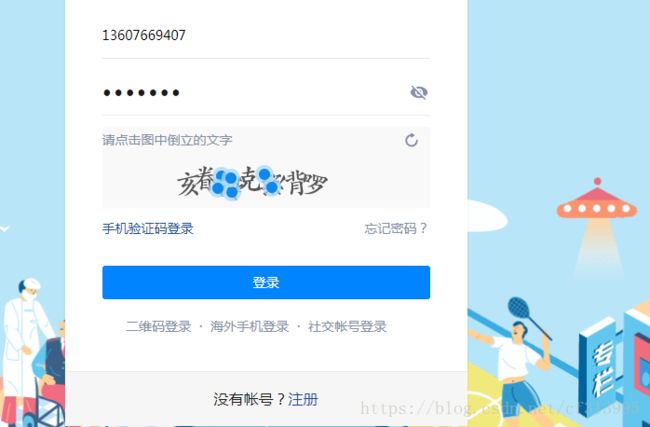
(4)分析出了这些,那么就好办了,我们将这七个汉字,每个汉字挨个点一遍,且都点在每个汉字大概中心的位置。

然后提交这个post请求,查看他的参数。此时它给出了我们这七个汉字的大概位置。

(5)我们以这七个坐标点为基准,将其存放在一个大列表中。
all_points = [[15.5,26.1875],[33.5,18.1875],[62.5,30.1875],[79.5,18.1875],[105.5,24.1875],[133.5,22.1875],[151.5,22.1875]]
(6)先对是否出现验证码的get请求发起请求,如果出现的是中文验证码,则继续发起put请求,获取验证码图片的加密地址,并对其进行解密,获得原始地址,并将验证码图片保存下来,以便我们人工识别。
img_url = json.loads(response.text).get('img_base64')
# 对加密图片进行解密,获取原始地址,
img_data = base64.b64decode(img_url)
# 根据得到的bytes-like对象,创建的字节码对象(bytes对象)
img_real_url = BytesIO(img_data)
# 利用Image去请求这个图片,获得图片对象
img = Image.open(img_real_url)
# 直接打开这张图片
img.show()
(7)定义一个空列表points,根据上一步展示在我们眼前的中文汉字验证码,输入其中倒立汉字的顺序。共有七个汉字,如果倒立的汉字位置是第一个和第七个,则输入17。然后根据这两个数在大列表all_points中获取两个坐标点,作为验证验证码的post请求的参数。
points = []
result = input('输入倒立汉字坐标(汉字位置):')
if len(result) == 2:
# 说明有两个倒立汉字
# 分别获取输入的两个位置:1 2
first_index = int(result[0])
second_index = int(result[1])
# 以first_index、second_index为索引,从self.all_points列表中,获取两个点坐标
first_p = self.all_points[first_index-1]
second_p = self.all_points[second_index-1]
points.append(first_p)
points.append(second_p)
值得注意的是,有时会出现一个倒立汉字的验证码,需要对以上代码稍加变更。
elif len(result) == 1:
# 说明只有一个倒立汉字
first_index = int(result[0])
first_p = self.all_points[first_index - 1]
points.append(first_p)
然后再次发起验证验证码的post请求。
yield scrapy.FormRequest(
url=self.captcha_url,
callback=self.parse_post_captcha,
formdata={
'input_text': str(points)
}
)
(8)验证成功后,即可请求登录网址。并携带从这一步后的代码中获取到的所有参数,进行登录即可。至此,无论是中文的汉字点选验证码还是英文的验证码模拟登录完成。