作者/分享人:张杨,热爱技术分享,活跃于今日头条和腾讯课堂,开设的《Python3网络爬虫入门》、《Python开发课程》等专栏受到好评。
一、前言
强烈建议:请在电脑的陪同下,阅读本文。本文以实战为主,阅读过程如稍有不适,还望多加练习。
本文的实战内容有:
二、网络爬虫简介
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。比如:https://www.baidu.com/,它就是一个URL。
在讲解爬虫内容之前,我们需要先学习一项写爬虫的必备技能:审查元素(如果已掌握,可跳过此部分内容)。
1. 审查元素
在浏览器的地址栏输入URL地址,在网页处右键单击,找到检查,如下图所示:(不同浏览器的叫法不同,Chrome浏览器叫做检查,Firefox浏览器叫做查看元素,但是功能都是相同的)

我们可以看到,右侧出现了一大推代码,这些代码就叫做HTML。什么是HTML?举个容易理解的例子:我们的基因决定了我们的原始容貌,服务器返回的HTML决定了网站的原始容貌。
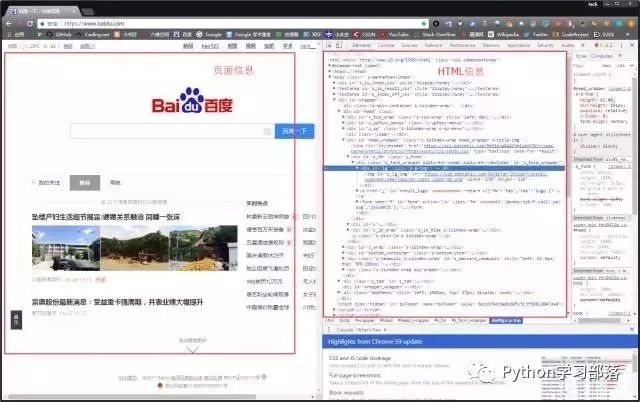
为啥说是原始容貌呢?因为人可以整容啊!扎心了,有木有?那网站也可以"整容"吗?可以!请看下图:

我能有这么多钱吗?显然不可能。我是怎么给网站"整容"的呢?就是通过修改服务器返回的HTML信息。我们每个人都是"整容大师",可以修改页面信息。我们在页面的哪个位置点击审查元素,浏览器就会为我们定位到相应的HTML位置,进而就可以在本地更改HTML信息。
再举个小例子:我们都知道,使用浏览器"记住密码"的功能,密码会变成一堆小黑点,是不可见的。可以让密码显示出来吗?可以,只需给页面"动个小手术"!以淘宝为例,在输入密码框处右键,点击检查。
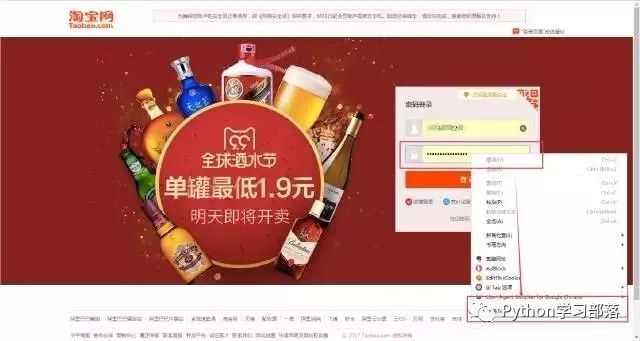
可以看到,浏览器为我们自动定位到了相应的HTML位置。将下图中的password属性值改为text属性值(直接在右侧代码处修改):

就这样,浏览器"记住的密码"显现出来了:
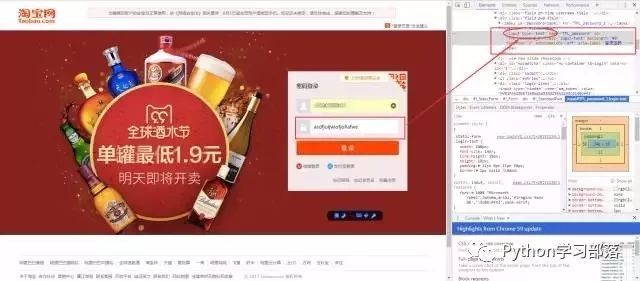
说这么多,什么意思呢?浏览器就是作为客户端从服务器端获取信息,然后将信息解析,并展示给我们的。我们可以在本地修改HTML信息,为网页"整容",但是我们修改的信息不会回传到服务器,服务器存储的HTML信息不会改变。刷新一下界面,页面还会回到原本的样子。这就跟人整容一样,我们能改变一些表面的东西,但是不能改变我们的基因。
2. 简单实例
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
requests库强大好用,所以本文使用requests库获取网页的HTML信息。requests库的github地址:https://github.com/requests/requests
(1)requests安装
在学习使用requests库之前,我们需要在电脑中安装好requests库。在cmd中,使用如下指令安装requests库:
pip install requests
easy_install requests
使用pip和easy_install都可以安装,二选一即可。
(2)简单实例
安装好requests库之后,我们先来大体浏览一下requests库的基础方法:
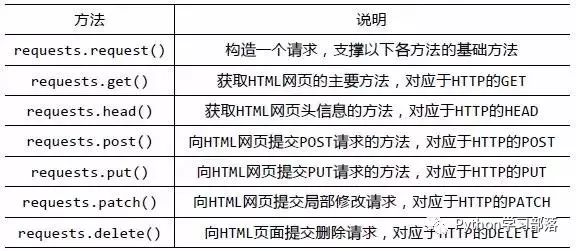
官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests库的开发者为我们提供了详细的中文教程,查询起来很方便。本文不会对其所有内容进行讲解,摘取其部分使用到的内容,进行实战说明。
首先,让我们看下requests.get()方法,它用于向服务器发起GET请求,不了解GET请求没有关系。我们可以这样理解:get的中文意思是得到、抓住,那这个requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。让我们看一个例子(以 www.gitbook.cn为例)来加深理解:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://gitbook.cn/'
req = requests.get(url=target)
print(req.text)
requests.get()方法必须设置的一个参数就是url,因为我们得告诉GET请求,我们的目标是谁,我们要获取谁的信息。我们将GET请求获得的响应内容存放到req变量中,然后使用req.text就可以获得HTML信息了。运行结果如下:

左侧是我们程序获得的结果,右侧是我们在www.gitbook.cn网站审查元素获得的信息。我们可以看到,我们已经顺利获得了该网页的HTML信息。这就是一个最简单的爬虫实例,可能你会问,我只是爬取了这个网页的HTML信息,有什么用呢?客官稍安勿躁,接下来进入我们的实战正文。
三、爬虫实战
实战内容由简单到复杂,难度逐渐增加,但均属于入门级难度。下面开始我们的第一个实战内容:网络小说下载。
1. 小说下载
(1)实战背景
小说网站《笔趣看》URL:http://www.biqukan.com/
《笔趣看》是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。因此,本次实战就是从该网站爬取并保存一本名为《一念永恒》的小说,该小说是耳根正在连载中的一部玄幻小说。PS:本实例仅为交流学习,支持耳根大大,请上起点中文网订阅。
(2)小试牛刀
我们先看下《一念永恒》小说的第一章内容,URL:http://www.biqukan.com/1_1094/5403177.html

用已经学到的知识获取HTML信息试一试,编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
print(req.text)
运行代码,可以看到如下结果:
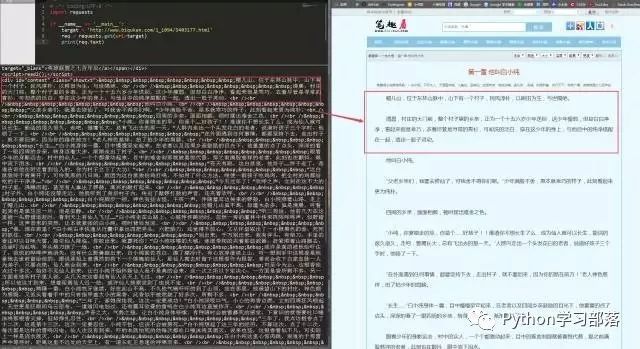
可以看到,我们很轻松地获取了HTML信息。但是,很显然,很多信息是我们不想看到的,我们只想获得如右侧所示的正文内容,我们不关心那些看着眼晕的英文字母。如何把正文内容从这些众多的HTML信息中提取出来呢?这就是本小节实战的主要内容。
(3)Beautiful Soup
爬虫的第一步,获取整个网页的HTML信息,我们已经完成。接下来就是爬虫的第二步,解析HTML信息,提取我们感兴趣的内容。对于本小节的实战,我们感兴趣的内容就是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup等。对于初学者而言,最容易理解,并且使用简单的方法就是使用Beautiful Soup提取感兴趣内容。
Beautiful Soup的安装方法和requests一样,使用如下指令安装(也是二选一):
一个强大的第三方库,都会有一个详细的官方文档。我们很幸运,Beautiful Soup也是有中文的官方文档。URL:http://beautifulsoup.readthedocs.io/zh_CN/latest/
同理,我会根据实战需求,讲解Beautiful Soup库的部分使用方法,更详细的内容,请查看官方文档。
现在,我们使用已经掌握的审查元素方法,查看一下我们的目标页面,你会看到如下内容:

不难发现,文章的所有内容都放在了一个名为div的“东西下面”,这个"东西"就是html标签。HTML标签是HTML语言中最基本的单位,HTML标签是HTML最重要的组成部分。不理解,没关系,我们再举个简单的例子:一个女人的包包里,会有很多东西,她们会根据自己的习惯将自己的东西进行分类。镜子和口红这些会经常用到的东西,回归放到容易拿到的外侧口袋里。那些不经常用到,需要注意安全存放的证件会被放到不容易拿到的里侧口袋里。
html标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。显然,上述例子中的div标签下存放了我们关心的正文内容。这个div标签是这样的:
细心的朋友可能已经发现,除了div字样外,还有id和class。id和class就是div标签的属性,content和showtxt是属性值,一个属性对应一个属性值。这东西有什么用?它是用来区分不同的div标签的,因为div标签可以有很多,我们怎么加以区分不同的div标签呢?就是通过不同的属性值。
仔细观察目标网站一番,我们会发现这样一个事实:class属性为showtxt的div标签,独一份!这个标签里面存放的内容,是我们关心的正文部分。
知道这个信息,我们就可以使用Beautiful Soup提取我们想要的内容了,编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
print(texts)
在解析html之前,我们需要创建一个Beautiful Soup对象。BeautifulSoup函数里的参数就是我们已经获得的html信息。然后我们使用find_all方法,获得html信息中所有class属性为showtxt的div标签。find_all方法的第一个参数是获取的标签名,第二个参数class_是标签的属性,为什么不是class,而带了一个下划线呢?因为python中class是关键字,为了防止冲突,这里使用class_表示标签的class属性,class_后面跟着的showtxt就是属性值了。看下我们要匹配的标签格式:
这样对应的看一下,是不是就懂了?可能有人会问了,为什么不是find_all('div', id = 'content', class_ = 'showtxt')?这样其实也是可以的,属性是作为查询时候的约束条件,添加一个class_='showtxt'条件,我们就已经能够准确匹配到我们想要的标签了,所以我们就不必再添加id这个属性了。运行代码查看我们匹配的结果:

我们可以看到,我们已经顺利匹配到我们关心的正文内容,但是还有一些我们不想要的东西。比如div标签名,br标签,以及各种空格。怎么去除这些东西呢?我们继续编写代码:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
print(texts[0].text.replace('\xa0'*8,'\n\n'))
find_all匹配的返回的结果是一个列表。提取匹配结果后,使用text属性,提取文本内容,滤除br标签。随后使用replace方法,剔除空格,替换为回车进行分段。 在html中是用来表示空格的。replace('\xa0'*8,'\n\n')就是去掉下图的八个空格符号,并用回车代替:

程序运行结果如下:

可以看到,我们很自然的匹配到了所有正文内容,并进行了分段。我们已经顺利获得了一个章节的内容,要想下载正本小说,我们就要获取每个章节的链接。我们先分析下小说目录,URL:http://www.biqukan.com/1_1094/

通过审查元素,我们发现可以发现,这些章节都存放在了class属性为listmain的div标签下,选取部分html代码如下:
在分析之前,让我们先介绍一个概念:父节点、子节点、孙节点。和
标签的开始和结束的位置,他们是成对出现的,有开始位置,就有结束位置。我们可以看到,在
标签包含
标签,那这个
标签就是
标签的子节点,
标签又包含
标签和
标签,那么
标签和
标签就是
标签的孙节点。有点绕?那你记住这句话:
谁包含谁,谁就是谁儿子!
他们之间的关系都是相对的。比如对于
看到这里可能有人会问,这有好多
好了,概念明确清楚,接下来,让我们分析一下问题。我们看到每个章节的名字存放在了
我们将之前获得的第一章节的URL和
http://www.biqukan.com/1_1094/5403177.html
第一章 他叫白小纯
不难发现,/1_1094/5403177.html是章节URLhttp://www.biqukan.com/1_1094/5403177.html的后半部分。其他章节也是如此!那这样,我们就可以根据
总结一下:小说每章的链接放在了class属性为listmain的标签下的
标签中。链接具体位置放在html->body->div->dl->dd->a的href属性中。先匹配class属性为listmain的
标签,再匹配
标签。编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/'
req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
print(div[0])
还是使用find_all方法,运行结果如下:

很顺利,接下来再匹配每一个
第一章 他叫白小纯
方法很简单,对Beautiful Soup返回的匹配结果a,使用a.get('href')方法就能获取href的属性值,使用a.string就能获取章节名,编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
server = 'http://www.biqukan.com/'
target = 'http://www.biqukan.com/1_1094/'
req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
for each in a:
print(each.string, server + each.get('href'))
因为find_all返回的是一个列表,里边存放了很多的

最上面匹配的一千多章的内容是最新更新的12章节的链接。这12章内容会和下面的重复,所以我们要滤除,除此之外,还有那3个外传,我们也不想要。这些都简单地剔除就好。
(3)整合代码
每个章节的链接、章节名、章节内容都有了。接下来就是整合代码,将获得内容写入文本文件存储就好了。编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests, sys
"""
类说明:下载《笔趣看》网小说《一念永恒》
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
class downloader(object):
def __init__(self):
self.server = 'http://www.biqukan.com/'
self.target = 'http://www.biqukan.com/1_1094/'
self.names = [] #存放章节名
self.urls = [] #存放章节链接
self.nums = 0 #章节数
"""
函数说明:获取下载链接
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
def get_download_url(self):
req = requests.get(url = self.target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
self.nums = len(a[15:]) #剔除不必要的章节,并统计章节数
for each in a[15:]:
self.names.append(each.string)
self.urls.append(self.server + each.get('href'))
"""
函数说明:获取章节内容
Parameters:
target - 下载连接(string)
Returns:
texts - 章节内容(string)
Modify:
2017-09-13
"""
def get_contents(self, target):
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
texts = texts[0].text.replace('\xa0'*8,'\n\n')
return texts
"""
函数说明:将爬取的文章内容写入文件
Parameters:
name - 章节名称(string)
path - 当前路径下,小说保存名称(string)
text - 章节内容(string)
Returns:
无
Modify:
2017-09-13
"""
def writer(self, name, path, text):
write_flag = True
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == "__main__":
dl = downloader()
dl.get_download_url()
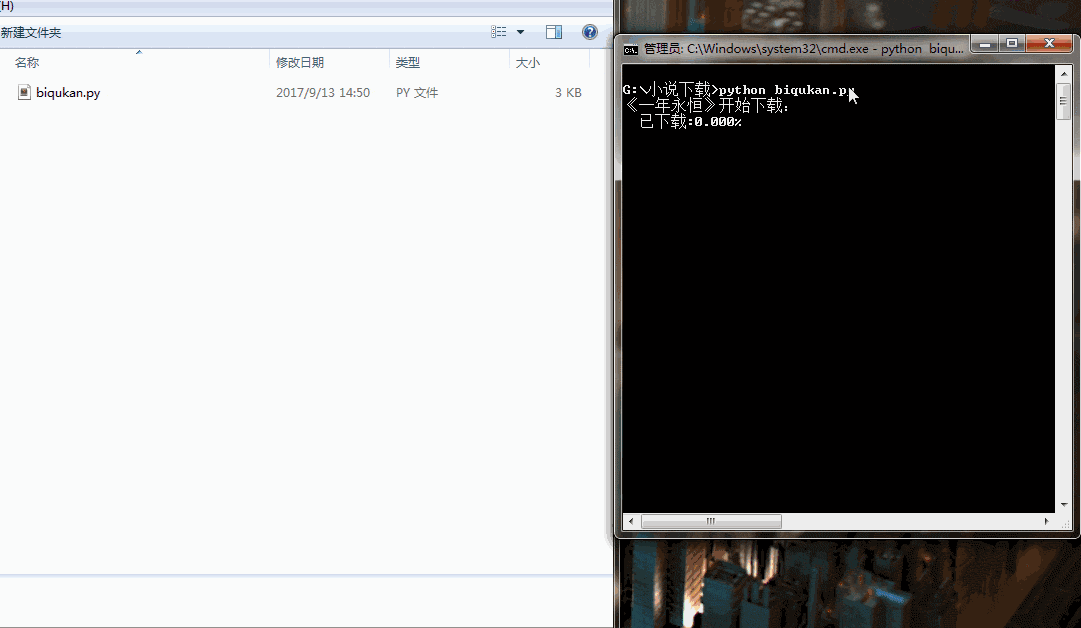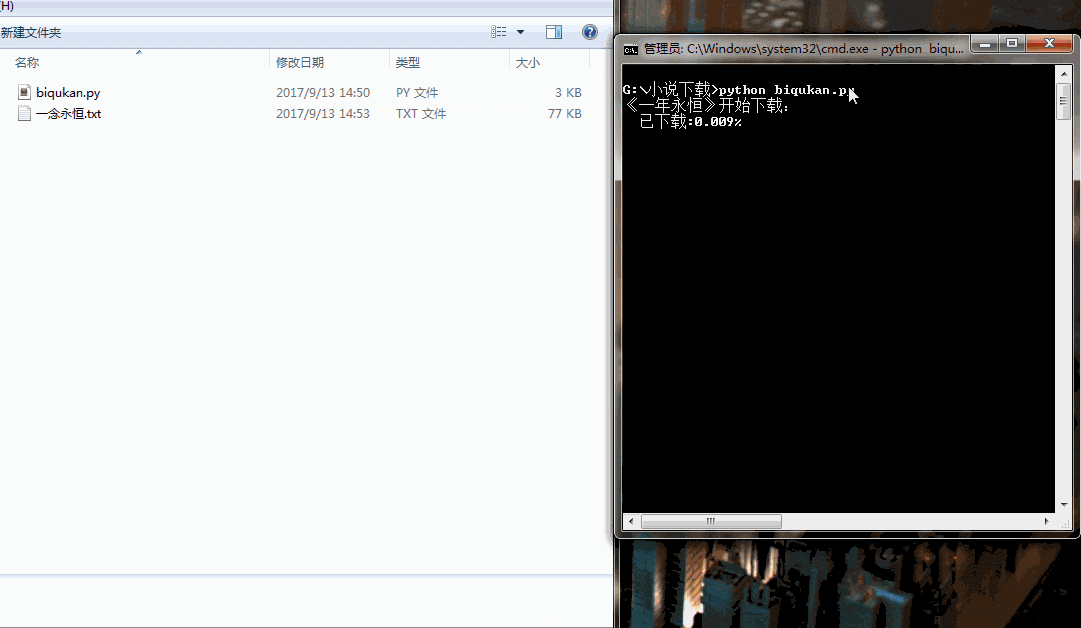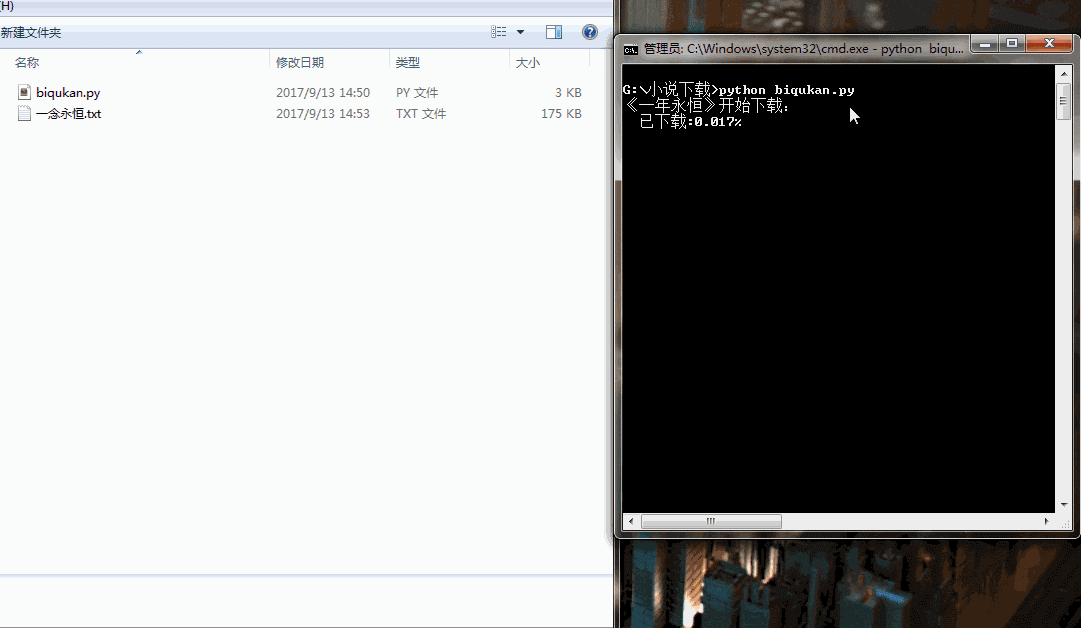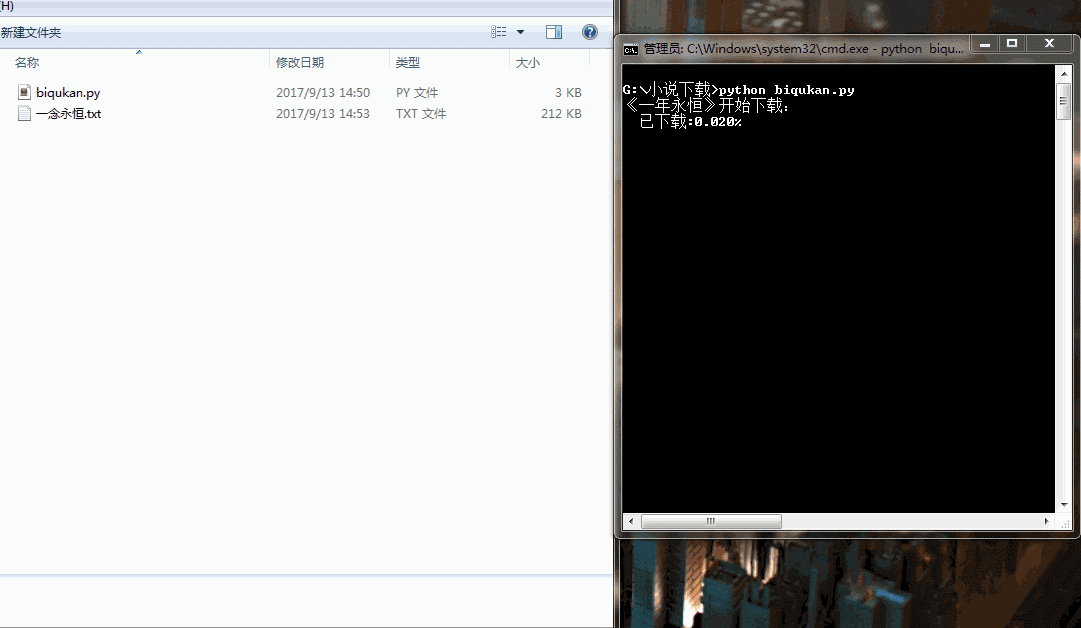
print('《一年永恒》开始下载:')
for i in range(dl.nums):
dl.writer(dl.names[i], '一念永恒.txt', dl.get_contents(dl.urls[i]))
sys.stdout.write(" 已下载:%.3f%%" % float(i/dl.nums) + '\r')
sys.stdout.flush()
print('《一年永恒》下载完成')
很简单的程序,单进程跑,没有开进程池。下载速度略慢,喝杯茶休息休息吧。代码运行效果如下图所示:
二. 爱奇艺VIP视频下载
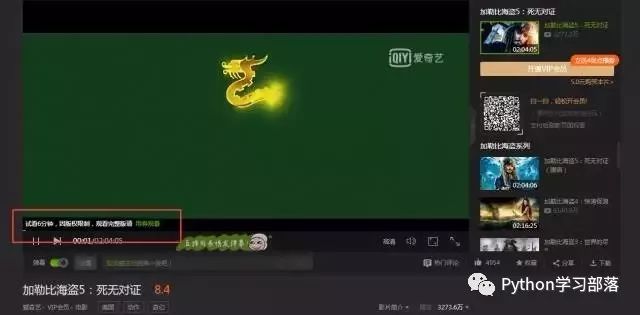
(1)实战背景
爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟。比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1
我们怎么免费看VIP视频呢?一个简单的方法,就是通过旋风视频VIP解析网站。URL:http://api.xfsub.com/
这个网站为我们提供了免费的视频解析,它的通用解析方式是:
http://api.xfsub.com/index.php?url=[播放地址或视频id]
比如,对于绣春刀这个电影,我们只需要在浏览器地址栏输入:
http://api.xfsub.com/index.php?url=http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1
这样,我们就可以在线观看这些VIP视频了:

但是这个网站只提供了在线解析视频的功能,没有提供下载接口,如果想把视频下载下来,我们就可以利用网络爬虫进行抓包,将视频下载下来。
(2)实战升级
分析方法相同,我们使用Fiddler进行抓包:
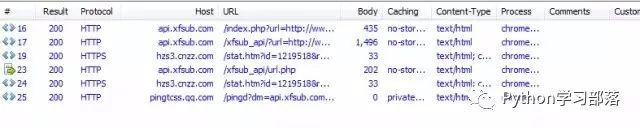
我们可以看到,有用的请求并不多,我们逐条分析。我们先看第一个请求返回的信息。

可以看到第一个请求是GET请求,没有什么有用的信息,继续看下一条。

我们看到,第二条GET请求地址变了,并且在返回的信息中,我们看到,这个网页执行了一个POST请求。POST请求是啥呢?它跟GET请求正好相反,GET是从服务器获得数据,而POST请求是向服务器发送数据,服务器再根据POST请求的参数,返回相应的内容。这个POST请求有四个参数,分别为time、key、url、type。记住这个有用的信息,我们在抓包结果中,找一下这个请求,看看这个POST请求做了什么。
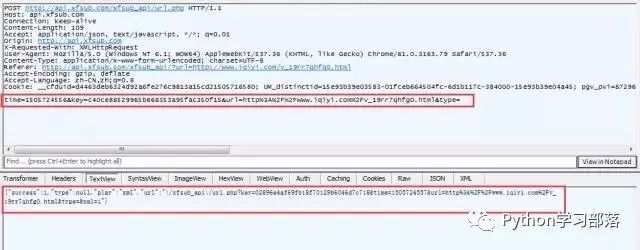
很显然,这个就是我们要找的POST请求,我们可以看到POST请求的参数以及返回的json格式的数据。其中url存放的参数如下:
xfsub_api\/url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http%3A%2F%2Fwww.iqiyi.com%2Fv_19rr7qhfg0.html&type=&xml=1
这个信息有转义了,但是没有关系,我们手动提取一下,变成如下形式:
xfsub_api/url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http://www.iqiyi.com/v_19rr7qhfg0.html&type=&xml=1
我们已经知道了这个解析视频的服务器的域名,再把域名加上:
http://api.xfsub.com/xfsub_api\url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http://www.iqiyi.com/v_19rr7qhfg0.html&type=&xml=1
这里面存放的是什么东西?不会视频解析后的地址吧?我们有浏览器打开这个地址看一下:

果然,我们可以看到视频地址近在眼前啊,URL如下:
http://disp.titan.mgtv.com/vod.do?fmt=4&pno=1121&fid=1FEA2622E0BD9A1CA625FBE9B5A238A6&file=/c1/2017/09/06_0/1FEA2622E0BD9A1CA625FBE9B5A238A6_20170906_1_1_705.mp4
我们再打开这个视频地址:

瞧,我们就这样得到了这个视频在服务器上的缓存地址。根据这个地址,我们就可以轻松下载视频了。
PS:需要注意一点,这些URL地址,都是有一定时效性的,很快就会失效,因为里面包含时间信息。所以,各位在分析的时候,要根据自己的URL结果打开网站才能看到视频。
接下来,我们的任务就是编程实现我们所分析的步骤,根据不同的视频播放地址获得视频存放的地址。
现在梳理一下编程思路:
用正则表达式匹配到key、time、url等信息。
根据匹配的到信息发POST请求,获得一个存放视频信息的url。
根据这个url获得视频存放的地址。
根据最终的视频地址,下载视频。
(3)编写代码
编写代码的时候注意一个问题,就是我们需要使用requests.session()保持我们的会话请求。简单理解就是,在初次访问服务器的时候,服务器会给你分配一个身份证明。我们需要拿着这个身份证去继续访问,如果没有这个身份证明,服务器就不会再让你访问。这也就是这个服务器的反爬虫手段,会验证用户的身份。

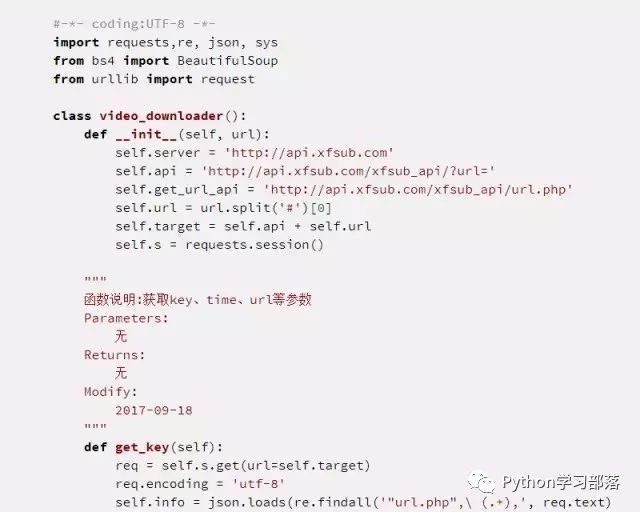
思路已经给出,希望喜欢爬虫的人可以在运行下代码之后,自己重头编写程序,因为只有经过自己分析和测试之后,才能真正明白这些代码的意义。上述代码运行结果如下:

我们已经顺利获得了mp4这个视频文件地址。根据视频地址,使用 urllib.request.urlretrieve() 即可将视频下载下来。编写代码如下:



urlretrieve()有三个参数,第一个url参数是视频存放的地址,第二个参数filename是保存的文件名,最后一个是回调函数,它方便我们查看下载进度。代码量不大,很简单,主要在于分析过程。代码运行结果如下:

下载速度挺快的,几分钟视频下载好了。
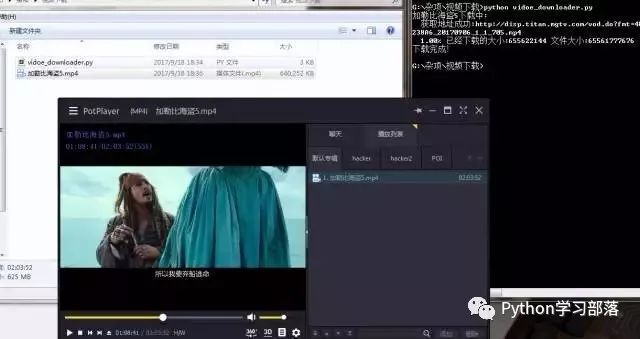
对于这个程序,感兴趣的朋友可以进行扩展一下,设计出一个小软件,根据用户提供的url,提供PC在线观看、手机在线观看、视频下载等功能。
三、总结
本场 Chat 讲解的实战内容,均仅用于学习交流,请勿用于任何商业用途!
爬虫时效性低,同样的思路过了一个月,甚至一周可能无法使用,但是爬取思路都是如此,完全可以自行分析。
本次实战代码,均已上传我的Github,欢迎Follow、Star:
https://github.com/Jack-Cherish/python-spider
如有问题,请留言。如有错误,还望指正,谢谢!
通知一下

你还在犹豫什么?加我助理老师,每晚八点半,发你课题通知你听课!

学完Python的就业前景



今天的内容就给大家分享在这里,今天没有所谓的妹纸来给大家值班。还是我,一直在后台给大家码字分享的张杨。其实每天在朋友圈还是在QQ群,各种平台,都会有很多的粉丝来私信我,想跟着我学Python,很多人大多数也是问问,我也是简简单单的应付一下,因为很多人在和我聊的第一感觉,我就能感觉这个人是不是真正的想学习Python,一般真真正正想学习Python的同学,他都很热情,对代码和程序充满了兴趣。在后台找到我的时候都是给我码了很长的一段字,这让我很欣慰,我也很高兴,看见你真正想学习的态度,其实很多时候,成长只是一个学习,一个态度的问题,而简简单单的一个态度就能看见你对这件事物的认真程度。
我是张杨,人生苦短,我用Python,喜欢请点赞。