全Hadoop2.x版本安装套路(以Hadoop2.6.0为例)
引言
本人是一枚大学生,初探大数据Hadoop安装套路,详细描述安装过程及其我所认知的步骤因果,作为一段时间学习的成果,也希望能与大家一起交流。 众所周知,自“大数据”概念劈头盖脸袭来后,各路人士都跃跃欲试想开一开大数据的车,那么鼎鼎大名的Hadoop理所当然被大家盯上啦,所以想掀开大数据的面纱就先得老老实实把Hadoop这头小象把玩一番。话不多说,今天的重头戏是Hadoop的安装。 再吐槽一下,互联网的发展导致信息共享更为便捷,但同时网络上许多文章的共通点就是只有步骤却没有清晰的注释,有时甚至会误导读者,即使通读按部就班操作,我们大部分也是只知其然而不知其所以然。 那么最稳的想法是饮水溯源,就让我们来啃一啃官方权威,Hadoop官网的安装文档(点击打开全英链接)以及《Hadoop权威指南》= =
安装步骤
准备所需材料
- 一台高配一点的电脑、VMware建好三个Centos7.2虚拟机,配置好网络与主机名
CMaster 192.168.83.137 CSlave01 192.168.83.138 CSlave02 192.168.83.139
- Hadoop2.6.0的编译包
送上 各版本Hadoop下载地址,这里我们选择hadoop-2.6.0,于是就进入了一个下载页面
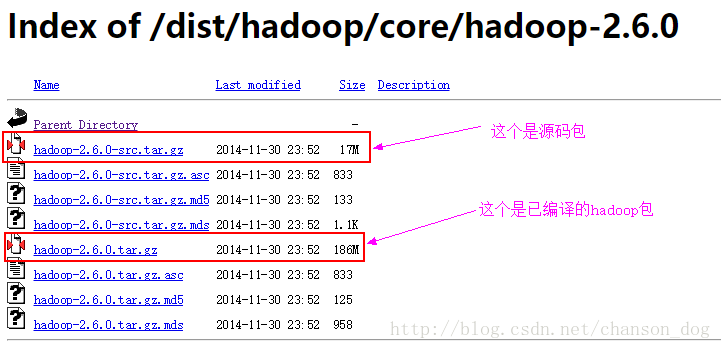
源码包的意思是要你自己编译,由于编译这工作对我们这些菜鸟来说成本太高啦,所以贴心的官方给出了已经编译好的包,有可能会遇到版本兼容以及插件编译问题哦。不过现在管他呢,且让我们安心下载编译包。
- JDK安装包
踩过兼容性坑的伙伴们都知道,两个软件包如果发行版本不匹配的话,就意味着一只脚已经迈入了bug的深渊。为了避免未知的恐惧,我选择先瞄一眼官方老大哥怎么说。 “应该选择一个经过Hadoop产品供应商认证的,操作系统、Java和Hadoop的组合。Hadoop英文维基页面上列出了能够成功运行的组合(Hadoop权威指南第4版P284)” 好的明白了,这就前往 Hadoop英文维基页面 又是全英页面我有点晕,冷静一下

我用蹩脚的英语水平看出了Hadoop2.7以及之后的版本需要装JAVA7,Hadoop2.6以及之前的版本支持JAVA6
好,这就前往JAVA官网拿下 JAVA SE 6

解释一下,这里x86指的是32位、x64表示64位。这里我选择第三个rpm.bin进行下载
关闭防火墙与SELINUX
“注意,是CMaster、CSlave01、CSlave02均要操作”
防火墙和安全策略相关的SELINUX是个双刃剑,他既能保护我们系统不受侵犯也能限制我们大展拳脚操作Hadoop,为了避免不必要的麻烦,我们选择狠心关闭
- 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service- 关闭SELINUX
vi /etc/selinux/config
重启生效
创建用户账号
“注意,是CMaster、CSlave01、CSlave02均要操作”
你想嘛,无限权力之王root,不敢动不敢动,还是自己建个用户grid来玩吧。并且这也是官方建议的。
useradd grid修改hosts
“注意,是CMaster、CSlave01、CSlave02均要操作”
建立ip和主机名之间的联系,以后需要指定某台主机的时候就不用写无规律的ip啦,只需要填入主机名。
vi /etc/hosts
安装配置JAVA
“注意,是CMaster、CSlave01、CSlave02均要安装”
嗯,怎么把JAVA包弄进去Centos我不管自己想办法啦哈哈哈,我用的方法是通过XShell上传至Linux 先检查一遍系统本身是否藏着个JAVA
rpm -qa | grep jdk若有,则使用命令删除
rpm -e | grep jdk
下一步,解压rpm.bin包
./jdk-6u45-linux-x64-rpm.bin
此时你会惊喜的发现你并不能执行jdk-6u45-linux-x64-rpm.bin

究其原因,就是它不认可你,你没有能力开启它
于是我选择变成修改文件权限变成超能力者强上
chmod 777 jdk-6u45-linux-x64-rpm.bin再次执行,果然听话了

不过出现一堆乱七八糟的东西,但不用管,JAVA6已经悄悄安装成功了,不信你看
java -version
为了让java的命令可以随时随地随心情执行,所以需要配置搜索目录,即环境变量
vi /etc/profile
#PATH
PATH=$PATH:$JAVA_HOME/bin:$JPS
#JAVA_ENVIRONMENT
JAVA_HOME=/usr/java/jdk1.6.0_45
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#EXPORT
export PATH JAVA_HOME CLASS_PATH
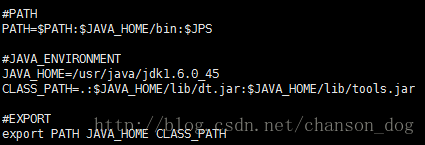
保存退出后,使文件生效
source /etc/profile配置SSH
“注意,CMaster、CSlave01、CSlave02均要安装”
SSH是一套有关于公钥密钥的工具,用来让Master为所欲为任意支配Slaves,毕竟你是要让Slaves存放数据,所以这就是Hadoop联机操作的必要步骤啦。
先进入我们之前配置的用户grid
su - grid各个节点先安装ssh工具
ssh-keygen –t rsa一路回车,此时会生成一个.ssh的隐藏文件夹,里面存放的是公钥密钥文件
在CMaster节点上执行下述命令
cat ~/.ssh/id_rsa.pub >authorized_keys
chmod 600 authorized_keys
scp authorize_keys grid@CSlave01:~/.ssh/
scp authorize_keys grid@CSlave02:~/.ssh/这堆命令就能完成SSH的搭建,注意将我的主机名和用户名改成对应自己的哦。好奇宝宝们可以去看一下SSH的原理。
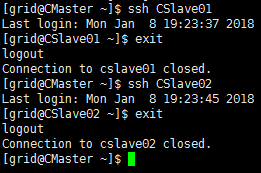
在CMaster上测试一下
ssh CSlave01
ssh CSlave02结果能自由进出CSlave01和CSlave02的用户,就证明配置成功啦
上传并解压配置Hadoop包
“注意,只在CMaster上安装”
上传自己想办法,我再推一下XShell的上传下载的功能嘻嘻
解压.tar.gz文件
tar -zxvf hadoop-2.6.0.tar.gz这时候已经生成了一个hadoop-2.6.0的文件夹,接下来就要配置一些文件能让我们的Hadoop能顺利运行
你要用hadoop的命令,难道还要进它的目录bin里面执行嘛?设置了环境变量之后,就可以随时随地执行hadoop命令啦
su - grid
vi .bashrc解释一下,在用户家目录底下,有两个隐藏的能配置环境变量的文件,分别为.bash_profile和.bashrc,它们两个还是有微妙的区别的,不过在这里不是重点,我选用的是.bashrc
#HADOOP_ENVIRONMENT
HADOOP_HOME=/home/grid/hadoop-2.6.0
#PATH
PATH=$PATH:$HADOOP_HOME/bin
#EXPORT
export PATH HADOOP_HOME

wq保存,强制使配置文件生效
source .bashrc配置env.sh文件和site.xml文件
“注意,以下操作只在CMaster上执行”
贴一张Hadoop权威指南的配置文件说明图

1.hadoop-env.sh
cd $HADOOP_HOME/etc/hadoop
vi hadoop-env.sh![]()
Hadoop运行需要调用JVM,所以它会在hadoop-env.sh里面找JDK的路径在哪里,所以我们在文件内给它添上JAVA_HOME的位置
![]()
wq保存退出
2.yarn-env.sh
vi yarn-env.sh同样道理,yarn也想知道JVM在哪里
![]()
不过值得注意的是,export前面的#号一定要去掉
3.core-site.xml
vi core-site.xml
fs.defaultFS
hdfs://CMaster:9000
io.file.buffer.size
131072
hadoop.tmp.dir
file:/home/grid/hadoop-2.6.0/tmp
Abase for other temporary directories.
hadoop.proxyuser.hduser.hosts
*
hadoop.proxyuser.hduser.groups
*
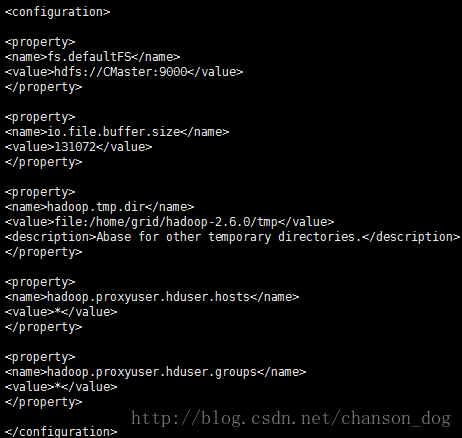
添上图里的内容,wq退出
解释一下: fs.defaultFS就是描述HDFS文件系统的URI,其主机是namenode的主机或IP地址,端口是namenode监听RPC的端口。如果没有指定,那么默认端口是8020 io.file.buffer.size,io读写文件时的块大小,一般为131072K(128M) hadoop再次启动时会自动寻找/tmp/hadoop-grid/dfs/name文件 由于重新启动Linux服务时,会自动清空/tmp目录,因此hadoop找不到文件就会出错,所以一定要先指明hadoop.tmp.dir目录
4.hdfs-site.xml
vi hdfs-site.xml
dfs.namenode.secondary.http-address
CMaster:9001
dfs.namenode.name.dir
file:/home/grid/hadoop-2.6.0/name
dfs.datanode.data.dir
file:/home/grid/hadoop-2.6.0/data
dfs.replication
3
dfs.webhdfs.enabled
true
dfs.permissions
fslse
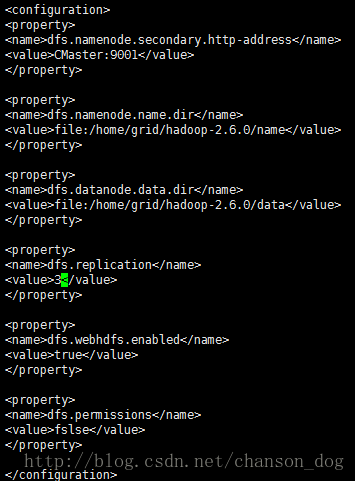
这个文件指明了一些监听地址和端口号
5.mapred-site.xml.template
vi mapred-site.xml.template
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
CMaster:10020
mapreduce.jobhistory.webapp.address
CMaster:19888
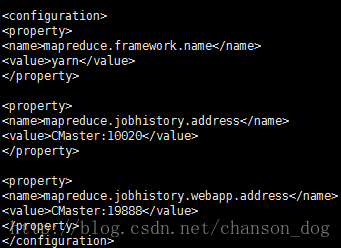
指明我们所用的框架是yarn,并且指定特定端口
wq退出后,还要改个名字
mv mapred-site.xml.template mapred-site.xml6.yarn-site.xml
vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
CMaster:8032
yarn.resourcemanager.scheduler.address
CMaster:8030
yarn.resourcemanager.resource-tracker.address
CMaster:8031
yarn.resourcemanager.admin.address
CMaster:8033
yarn.resourcemanager.webapp.address
CMaster:8088
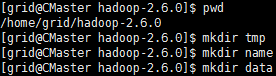
7.把上述配置文件提及的目录没有创建的都创建好
哈哈哈我知道如果有人要深究这些配置文件还有什么隐藏功能,我小白是讲不清楚的,献上官方说明文档与我的膝盖 官方全英安装配置说明文档
8.配置slaves文件
vi $HADOOP_HOME/etc/hadoop/slaves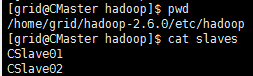
分发配置好的Hadoop给其它节点
“注意,以下操作只在CMaster上执行”scp -r ~/hadoop-2.6.0 grid@CSlave01:~
scp -r ~/hadoop-2.6.0 grid@CSlave02:~
scp ~/.bashrc grid@CSlave01:~
scp ~/.bashrc grid@CSlave02:~格式化namenode
“注意,以下操作只在CMaster上执行”
cd $HADOOP_HOME/bin
./hdfs namenode –format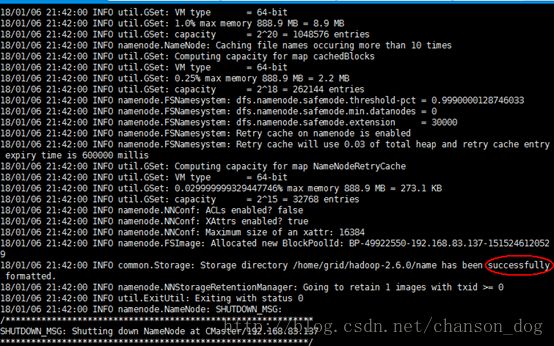
出现红圈中的successfully就表示格式化成功啦
启动Hadoop集群
“注意,以下操作只在CMaster上执行”
可以激动一下了,毕竟到临门一脚的时候了
cd $HADOOP_HOME/sbin
./start-all.sh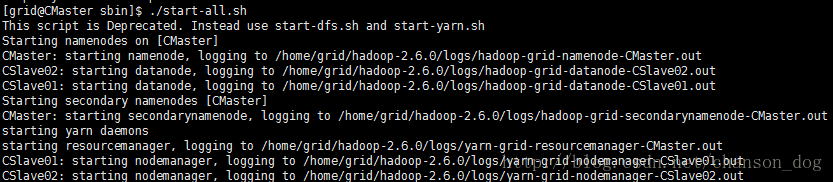
然后用JAVA里面自带的jps可以查看Hadoop的进程是否已经成功启动了
/usr/java/jdk1.6.0_45/bin/jps
CSlave01、CSlave02


如果所有进程都成功了你就是人生赢家了
但是,如果其中有某个进程启动不起来也不要着急,最万能最稳的操作是先停止整个集群
cd $HADOOP_HOME/sbin
./stop-all.sh然后查看启动日志
cd $HADOOP_HOME/logs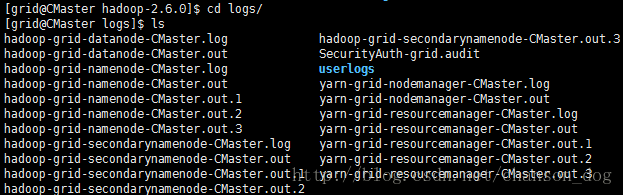
直接vi打开对应出问题的进程的log文件,查看具体问题再自行百度祝你一路顺风
PS:由于Hadoop调用本地库处理事务比用java快,因此hadoop为了提升性能,会加载本地库。以前会出现官方下载编译好的包是32位的,不过这次试验看来hadoop2.6.0的本地库包即是64位。否则需要编译源码。

总结
这种编辑器不熟,很难受
好啦总结一下,按照官方权威的要求来安装其实没有什么版本的障碍,包括其余的Hadoop2.x版本,甚至于目前最新的Hadoop-3.0.0,安装的方法其实也是一模一样的~
接下来我会更新一些hadoop的有趣操作,继续深入Hadoop,一起努力!