CentOS7搭建Hadoop集群
准备工作
1、准备三台虚拟机,参考:CentOS7集群环境搭建(3台)-CSDN博客
2、配置虚拟机之间免密登录,参考:CentOS7集群配置免密登录-CSDN博客
3、虚拟机分别安装jdk,参考:CentOS7集群安装JDK1.8-CSDN博客
4、下载Hadoop安装包,下载地址:链接:https://pan.baidu.com/s/1f1DmqNNFBvBDKi5beYl3Jg?pwd=6666
搭建Hadoop集群
集群部署规划

一、上传并解压Hadoop安装包
1、将hadoop3.3.4.tar.gz使用XFTP上传到opt目录下面的software文件夹下面
2、进入到Hadoop安装包路径
cd /opt/software3、解压安装文件到/opt/moudle下面
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/moudle/![]()
4、查看是否解压成功
cd /opt/moudle
ll
5、重命名
mv hadoop-3.3.4/ hadoop
6、将Hadoop添加到环境变量
1、获取Hadoop安装路径
进入Hadoop目录下输入
pwd
#输出
opt/moudle/hadoop![]()
2、打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh在profile文件末尾添加hadoop路径:(shitf+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/moudle/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
3、保存后退出
esc键然后
:wq
4、分发环境变量文件
分发脚本之前配置的有可以去前面的文章看看
sudo /home/user/bin/xsync /etc/profile.d/my_env.sh5、source 使之生效(3台节点)
[user@hadoop102 module]$ source /etc/profile.d/my_env.sh
[user@hadoop103 module]$ source /etc/profile.d/my_env.sh
[user@hadoop104 module]$ source /etc/profile.d/my_env.sh
二、配置集群
1、核心配置文件
配置core-site.xml
cd $HADOOP_HOME/etc/hadoopvim core-site.xml文件内容如下(在
我这样配置不知道为啥用不了(直接用的root用户)加红的地方换成root
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/opt/moudle/hadoop/data
ha.zookeeper.quorum
hadoop102:2181,hadoop103:2181,hadoop104:2181
hadoop.http.staticuser.user
user
hadoop.proxyuser.user.hosts
*
hadoop.proxyuser.user.groups
*
hadoop.proxyuser.user.users
*

2、HDFS配置文件
配置hdfs-site.xml
vim hdfs-site.xml文件内容如下在
dfs.namenode.name.dir
file://${hadoop.tmp.dir}/name
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/data
dfs.journalnode.edits.dir
${hadoop.tmp.dir}/jn
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
hadoop102:8020
dfs.namenode.rpc-address.mycluster.nn2
hadoop103:8020
dfs.namenode.http-address.mycluster.nn1
hadoop102:9870
dfs.namenode.http-address.mycluster.nn2
hadoop103:9870
dfs.namenode.shared.edits.dir
qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/user/.ssh/id_rsa
dfs.ha.automatic-failover.enabled
true
dfs.replication
3
3、YARN配置文件
配置yarn-site.xml
vim yarn-site.xml文件内容如下(在
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster-yarn1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop102
yarn.resourcemanager.webapp.address.rm1
hadoop102:8088
yarn.resourcemanager.address.rm1
hadoop102:8032
yarn.resourcemanager.scheduler.address.rm1
hadoop102:8030
yarn.resourcemanager.resource-tracker.address.rm1
hadoop102:8031
yarn.resourcemanager.hostname.rm2
hadoop103
yarn.resourcemanager.webapp.address.rm2
hadoop103:8088
yarn.resourcemanager.address.rm2
hadoop103:8032
yarn.resourcemanager.scheduler.address.rm2
hadoop103:8030
yarn.resourcemanager.resource-tracker.address.rm2
hadoop103:8031
yarn.resourcemanager.zk-address
hadoop102:2181,hadoop103:2181,hadoop104:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
4096
yarn.nodemanager.resource.memory-mb
4096
yarn.nodemanager.pmem-check-enabled
true
yarn.nodemanager.vmem-check-enabled
false
4、MapReduce配置文件
配置mapred-site.xml
vim mapred-site.xml文件内容如下(在
mapreduce.framework.name
yarn
5、配置workers
vim /opt/moudle/hadoop/etc/hadoop/workers在该文件中增加如下内容(localhost删除):
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。

三、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1、配置mapred-site.xml
vim mapred-site.xml在该文件里面增加如下配置。
mapreduce.jobhistory.address
hadoop102:10020
mapreduce.jobhistory.webapp.address
hadoop102:19888
四、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
1、配置yarn-site.xml
vim yarn-site.xml在该文件里面增加如下配置。
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
五、分发Hadoop
xsync /opt/moudle/hadoop/六、启动Hadoop-HA
1、在3个JournalNode节点上,输入以下命令启动journalnode服务
进入/opt/moudle/hadoop
![]()
hdfs --daemon start journalnode2、在hadoop102[nn1]上,对其进行格式化,并启动
hdfs namenode -format
hdfs --daemon start namenode3、在hadoop103[nn2]上,同步nn1的元数据信息
hdfs namenode -bootstrapStandby4、启动hadoop103[nn2]
hdfs --daemon start namenode5、格式化zkfc(102)
zookeeper必须先启动
zk.sh start具体参考zookeeper集群安装
hdfs zkfc -formatZK6、在所有nn节点(102、103)启动zkfc
hdfs --daemon start zkfc7、在所有节点上(3台),启动datanode
hdfs --daemon start datanode8、第二次启动可以在NameNode所在节点执行start-dfs.sh启动HDFS所有进程
(这一步不用管)关闭之时,提示我权限不够,我直接用root用户操作,然后在hadoop-env.sh中加入以下几行
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_JOURNALNODE_USER="root"
export HDFS_ZKFC_USER="root"在yarn-env.sh中加入了以下几行 :然后分发给三台机器
export YARN_NODEMANAGER_USER="root"
export YARN_RESOURCEMANAGER_USER="root"start-dfs.sh
stop-dfs.sh9、在ResourceMamager所在节点执行start-yarn.sh 启动yarn所有进程
start-yarn.sh
stop-yarn.sh10、部署完成可以通过start-all.sh和stop-all.sh控制Hadoop-HA所有节点的启停
start-all.sh
stop-all.shHadoop群起脚本
1、在/home/user/bin目录下创建hdp.sh
2、写入以下内容
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs 和 yarn ---------------"
ssh hadoop102 "/opt/moudle/hadoop/sbin/start-all.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/moudle/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/moudle/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 hdfs 和 yarn ---------------"
ssh hadoop102 "/opt/moudle/hadoop/sbin/stop-all.sh"
;;
*)
echo "Input Args Error..."
;;
esac
3、增加(+x指的是增加可以运行权限)权限
chmod +x hdp.sh4、启动集群
hdp.sh start查看进程
xcall.sh jps5、关闭集群
hdp.sh stop查看进程
xcall.sh jps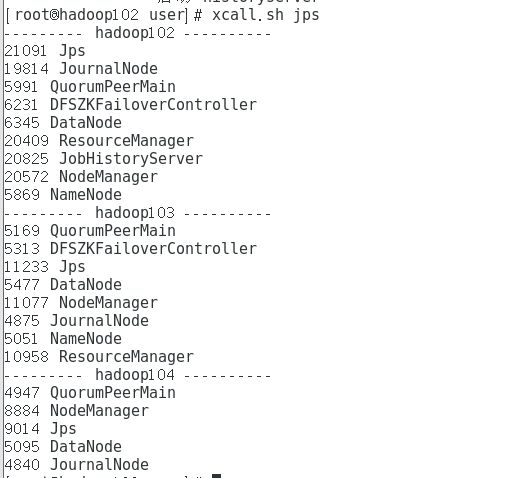
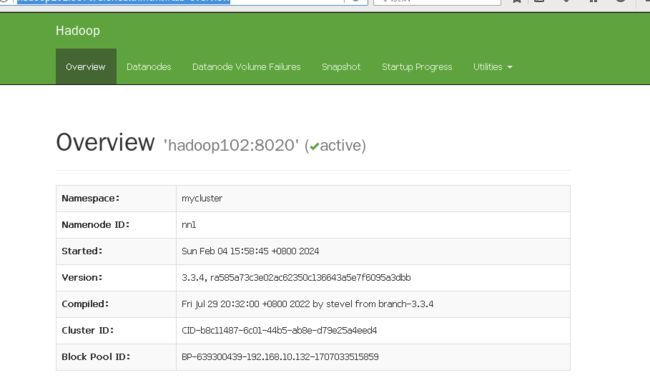
UI
http://hadoop102:9870/dfshealth.html#tab-overview
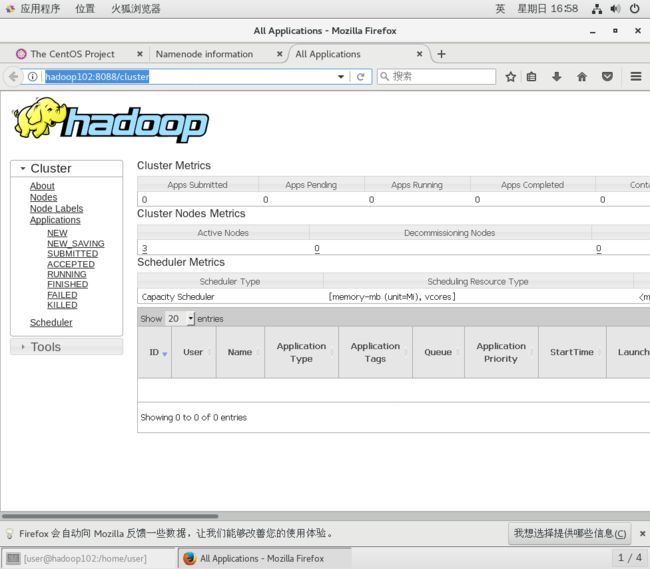
http://hadoop102:8088/cluster http://hadoop102:8088/cluster
http://hadoop102:8088/cluster
至此Hadoop集群就顺利搭建完成,遇见错误可以私我,共勉~