Path Aggregation Network for Instance Segmentation 论文阅读
写在最前面:仅是翻译,未有个人观点。
这篇文章是实例分割方向文献,Mask R-CNN的改进。其中参考了很多大佬的现有的理解,可能参考的东西太多,有疏漏。提示:排版对手机不友好。
原文地址:Path Aggregation Network for Instance Segmentation
参考译文:实例分割--(PANet)Path Aggregation Network for Instance Segmentation
论文的背景
由何凯明等人提出的Mask R-CNN[1]的网络架构,可以很好的解决实例分割的问题。本论文基于Mask R-CNN,进一步将低层和高层的特征进行融合。具体来说,特征金字塔网络提供了一个自上而下的路径增强语义特征的流动,PANet则是提供了一个自下而上的增强路径。从ROIAlign上采样候选区域得到的多个特征网格,通过自适应特征池化做融合操作用于后续预测。在预测时,本论文结合了全卷积网络(FCN)和全连接层(![]() )的优点,得到了相对Mask R-CNN更好的结果。另外创建了一个分支用于捕获各个候选区域的不同识图,进一步提升掩模预测。
)的优点,得到了相对Mask R-CNN更好的结果。另外创建了一个分支用于捕获各个候选区域的不同识图,进一步提升掩模预测。
论文内容
1、论文结构
Section 1(Introduction):
对Mask R-CNN使用的特征提取以及掩模生成做了一个简单的介绍,数据量日益增加的数据集对当前算法的提升也提供了可能性,并介绍了分类方向的一些可借鉴的方法。引出本文PANet,介绍了该算法的优越性和贡献,通过实验结果说明算法的高精度。
Section 2 (Related Work):
对基于区域推荐的R-CNN系列和分割为基础系列的论文进行了简单的说明,阐述了不同层次的特征对于物体识别的贡献,对更大的情景区域的运用情况做了简短介绍。
Section 3 (Framework):
对论文中的算法网络框架进行了阐述,包括自下而上的路径增强、自适应特征池化和全连接融合。
Section 4 (Experiments):
将该算法在不同的数据集上进行测试对比,说明了算法的优越性。
Section 5 (Conclusion):
论文总结和展望。
2、Introduction
Mask R-CNN基于Fast R-CNN[2]和Faster R-CNN[3],运用全卷积网络(FCN)做掩模的预测、边界框回归和分类任务。为了达到高性能,Mask R-CNN运用特征金字塔网络(FPN)[4]提取网内的特征结构,使用具有侧面连接的自上而下的路径增加强语义特征的流动。
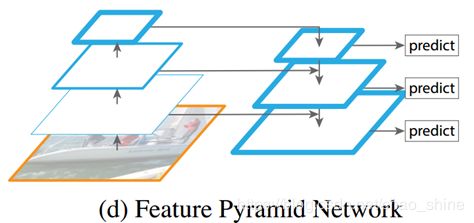 图1 自上而下的网络增强的特征金字塔网络
图1 自上而下的网络增强的特征金字塔网络
实例分割的进步离不开数据集的发展,论文中主要介绍了一下实验用到的三个数据集:COCO[5]、Cityscapes[6]和MVD[7]。其中COCO数据集[1]包含了200k(目前网站显示有330k张图片,已经有超过200k张图片得到了标注)张图片,每张图中的大部分实例都有复杂的空间结构。
 图2 COCO数据集的样例
图2 COCO数据集的样例
Cityscapes[2]和MVD数据集则提供了大量的街道的不同交通场景,包括了模糊、高度重叠和极小的实例。
 图3 Cityscapes数据集中细化的场景
图3 Cityscapes数据集中细化的场景
A、Our Findings
研究表明,特征信息传播可以在Mask R-CNN中进一步得到运用,以得到更好的结果。具体来说,低层次的特征信息对大型的实例分类比较有用。但是现有的网络结构中,低层次的结构到高层次特征(topmost feature)间有较长的距离,使得低层次得位置信息较难传到高层去。
另外,每个候选区域都是由一个特征层次上的特征网络池化得到的,是一种基于经验(heuristically)的做法。这个过程可以进行改进,因为在其他层次丢弃掉的信息也许对最后的预测有用。最后掩模的预测是在一个view(视图??)上,丢失了收集不同信息(??)的机会。
B、Our Contribution
如下图所示,文章中一个PANet网络架构:
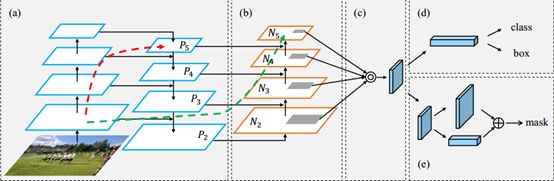 图4 PANet的网络结构
图4 PANet的网络结构
- (a)部分是FPN网络结构,第一次使用横向连接(Lateral Connection);
- (b)部分是自下而上的路径增强路径,使得高低层的信息得到交互,将低层次的位置信息得到了更好的利用;
- (c)部分自适应特征卷积层,用于恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免任意分配的结果;
- (d)部分同Mask R-CNN一样,对B-Box进行预测;
- (e)部分使用一个小型
 (全连接)层用于补充掩模的预测,这能够捕获每个候选区域不同视图,与Mask R-CNN原始的FPN有互补作用。通过融合两个视图,信息的多样性会增加,可以得到预测的更好的掩模。
(全连接)层用于补充掩模的预测,这能够捕获每个候选区域不同视图,与Mask R-CNN原始的FPN有互补作用。通过融合两个视图,信息的多样性会增加,可以得到预测的更好的掩模。
模型的前两个组件是目标检测和实例分割共享的,这大大提高了两个任务的性能。
C、Experience Results
经过实验,本文的方法在多个数据集上都达到了顶尖的效果。以ResNet-50为基础网络,该算法在目标检测和实例分割双任务上超过了2016年的COCO最佳方法,并且还只是测试单尺度的性能。在COCO2017比赛中,获得了实例分割第一,目标检测任务第二。同时本文还在CityScapes和MVD数据集上进行了测试,均达到了一流的效果。
3、Related Work
A、Instance Segmentation
目前流行着两种实例分割的方法:
- 基于区域推荐的方法:这是一种相对更加流行的方法,与物体检测强烈相关。R-CNN[8]采用优于滑窗法的Selective Search对图像中最有可能包含物体的区域搜索,然后送进特征提取的网络(CNN),Fast/Faster R-CNN和SPPNet[9]则通过池化全局特征映射来加速该过程。更早的研究中,将从MCG得到的候选掩模送入特征提取网络,同时利用CFM和MNC等方法将特征进行融合,以得到更好的效率。还有的方法是将产生的实例掩模作为一种推荐或者最后的结果,Mask R-CNN就是基于这种思路的一种有效的架构。
- 基于分割的方法:首先学习特定的设计转换或实例边界,然后将实例掩模从预测转换中解码出来。DIN从物体检测和语义分割两方面进行融合预测结果。有的方法使用图模型(?)来推断实例顺序,使用RNN在每一步进行推荐实例中得到了应用。
B、Multi-level Feature
不同层的特征常被用来做图像识别,SharpMask和LPP均采用融合特征以获得精细分割,而FCN和U-Net通过跳连接(skip-connection)融合来自低层的信息,FPN和TDM均使用了侧向连接进行路径增强提高物体检测的效果。与将最高分辨率的特征融入到池化特征中的TDM不同,SSD、DSSD、MS-CNN和FPN均将候选区域分配到合适的特征层次用于推断。本论文采用了FPN为基准,并对FPN进行了大幅度的增强。
ION和Hypernet串联了来自不同层次的特征网格,以得到更好的预测结果。但是需要一系列复杂的归一化、串联和降维等操作,相比之下,本文提出的方法更加的简单。
针对每个候选区域,[10]融合了不同源的特征网格。但是这种方法是在不同尺度的输入上进行了特征提取,然后利用特征融合(最大池化操作)改善来自输入图片金字塔的特征选择。该论文使用的是在网络内部特征结构下的所有特征层次的信息,输入的数据为单尺度,支持端到端的训练。
C、Larger Context Region
[11] 使用foveal结构的对每个候选区域的特征进行池化,用于找到不同分辨率区域下的上下文信息。更大区域的特征池化可以提供更多的周围的上下文信息,例如,PSPNet、ParseNet在语义分割上使用全局池化,极高地提升了性能。该论文中的掩模预测分支同样支持获取全局的信息,但是技术完全不同。
4、Framework
PANet的网络架构如图4所示,图中从下而上的路径增强可以提高低层信息在整个网络架构的流动。该论文提出了自适应特征池化,使得每一个推荐区域可以接触到各个层次的信息,以得到更好的预测。论文添加了一个分支用于预测掩模,提高了预测的性能,与FPN架构相似,该方法可以独立CNN结构
4.1 自下而上的路径增强 (Bottom-up Path Augmentation)[3]
A、Motivation
[12]提到一个重要的观点:层次越高的神经元对整个物体的响应越强烈,其他的神经元则更容易被局部语义和图案所激活。这一观点表明,自上而下的路径增强对于传播语义信息丰富的特征具有重要意义,在FPN中这种方法使得所有的特征得到了合理的分类。
对于边界或实例部分的高级响应是精确定位实例的强有力的指标,基于这一点,该论文的结构通过提出一种将低层次的图案信息传到所有的特征层次,以获得更好的位置信息。具体来说,本文建立了一个简单的从低级到高级的横向连接。图4中绿色虚线显示了该思想,展现了这一不超过10层的捷径(shortcut)。相比之下,FPN中的卷积神经网络线路(CNN trunk,图4中红色虚线)从最低层到最高层需要经过100多层。
B、Augmented Bottom-up Structure
该论文第一个实现了自下而上的路径增强,论文遵循FPN的定义,产生相同尺寸大小的特征层处于网络的同一阶段。每个特征层次(feature level)对应一个阶段(stage)。
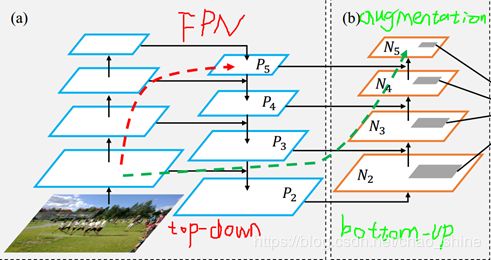 图5 自下而上的FPN(左)和自上而下的路径增强(右)
图5 自下而上的FPN(左)和自上而下的路径增强(右)
以ResNet为基础结构,如图5所示,用![]() 来表示通过FPN得到的特征层,从到
来表示通过FPN得到的特征层,从到![]() ,下采样系数均为2。同时定义
,下采样系数均为2。同时定义![]() 为对应
为对应![]() 生成的特征图,注意到
生成的特征图,注意到![]() 就是,没有增加任何的处理。
就是,没有增加任何的处理。
自下而上的路径增强的具体操作为:将每一个较高分辨率的(2倍关系)![]() 与一个低分辨率的通过一个横向连接进行融合,产生一个新的特征图
与一个低分辨率的通过一个横向连接进行融合,产生一个新的特征图![]() 。如下图所示:
。如下图所示:
 图6 自下而上的路径增强的结构图
图6 自下而上的路径增强的结构图
对上图的简单解释就是:
- 每一个
 先经过步长为2,卷积大小为
先经过步长为2,卷积大小为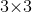 的卷积层,卷积得到的图像尺寸可以表示为
的卷积层,卷积得到的图像尺寸可以表示为![\[{\text{(N-3+2}\times \text{P )}}/{\text{2}}\;\text{+1}\]](http://img.e-com-net.com/image/info8/665f78e356064281a3ddd4ff822c3720.gif) ,其中N表示
,其中N表示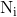 的图像大小,P表示卷积操作时的填零圈数;
的图像大小,P表示卷积操作时的填零圈数; - 将和对进行下采样得到的数据进行融合;
- 对
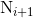 继续进行下采样,以便下一次的融合;
继续进行下采样,以便下一次的融合; - 以上迭代到产生为止。
论文中提到,以上迭代过程的都使用256通道,所有的卷积层后都接一个ReLU层,这样每一推荐区域对应的特征网格被池化为特征图,例如![]() 。
。
4.2 自适应特征池化(Adaptive Feature Pooling)
A、Motivation
在FPN中,依据候选区域的大小将候选区域分配到不同特征层次。这种做的结果是:小的候选区域分配到低层次,大的候选区域分配到高层中。这种做法虽然简单有效,但这可能会产生非最优结果。例如两个具有10个不同像素的候选区域可能分配到不同特征层次,然而,这两个候选区域可能是非常相似的。
换句话说,特征的重要性可能与他们所属的特征层次没有太大关系。高层次的特征具有较大的感受野,拥有丰富的上下文信息。假如让小型候选区域获取这些特征,可以更好的使用上下文信息做预测。同样的道理,低层次的特征拥有较多的细节和更准确的位置信息。假如让大型候选区域获取这些特征也是非常有用的。
基于以上的想法,自适应特征池化应运而生。
对自适应特征池化网络结构中来自不同层次的特征池化的因子进行分析,首先使用最大池化操作融合不同层次特征,这允许网络逐元素选择有用信息。依据FPN中将信息分配的层次,我们将候选区域聚类成四类。对于每组候选区域,我们计算来自不同层次的特征比例。 levels1-4表示从低到高的特征,如下图所示:
 图7 自适应特征池化层后各层的比例系数
图7 自适应特征池化层后各层的比例系数
蓝线表示FPN将小型候选区域分配给了level1,可以看到有近70%的特征来源于其他高层;黄线则表示FPN中将大型候选区域分配给level4,有超过50%的特征从都是从其他低级层次来的。所以,特征来自多个层次有助于提高精度,这也是对设计自下而上增强路径强有力的支持。(这些系数是咋来的?)
B、Adaptive Feature Pooling Structure
自适应特征池化实际上很容易实现,具体如下图中(c)所示。
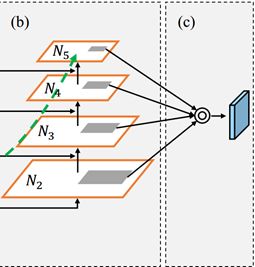 图8 自适应特征池化层
图8 自适应特征池化层
对于上图简单解释如下:
- 对于每个候选区域,将其映射到不同特征层次,如上图(b)深灰色区域;
- 使用ROIAlign池化来自不同层次的特征网格;
- 再使用融合操作(逐像素相加或取最大值)融合不同层次的特征网格;
在随后的网络中,池化后的特征网格分别进入一个参数层,然后再接融合操作,让网络适应特征。例如,在FPN中,预测B-Box的支路有两个全连接层,可以在第一层后进行融合操作。结合Mask R-CNN,其中有四个连续的卷积层用于掩模检测,论文中将融合操作放在了第一层卷积和第二层卷积之间。
候选区域对应融合后的特征网格用于的进一步预测,即分类、框回归和掩模预测,下图是自适应特征池化的详细示意图:
 图9 自适应特征池化示意图
图9 自适应特征池化示意图
从图中可以看到融合操作处于和之间, 融合操作的位置在实验部分是有对比实验的。该设计侧重于融合来自内部网络特征层次结构的信息,而不是来自输入图像金字塔的不同特征图的信息。(??)
4.3 全连接融合(Fully-connected Fusion)
A、Motivation
全连接层和MLP广泛应用于实例分割中,用于预测掩模和生成掩模候选区域。有论文的结果表明FPN同样也能够逐像素的预测掩模。 Mask R-CNN使用了一个小型的FPN应用于池化后特征网格,用于预测对应的掩模,从而减少了类间竞争(??)。
全连接层(![]() )和全卷积网络(FCN)具有不同的特性:
)和全卷积网络(FCN)具有不同的特性:
⑴ FCN基于局部感受野和不同空间位置进行参数的共享,给出了像素级的预测;
⑵ 全连接层对位置信息敏感,因为对于不同空间位置的预测都是通过一组可变参数实现的,故认为全连接层具有适应不同空间位置的能力。
鉴于两者特性 的不同,该论文将两者混合起来使用。
B、Mask Prediction Structure
论文中负责预测掩模的是一个轻量级、易实现的分支,这个预测掩模分支的输入是每个候选区域融合后的池化特征网格,如下图所示:
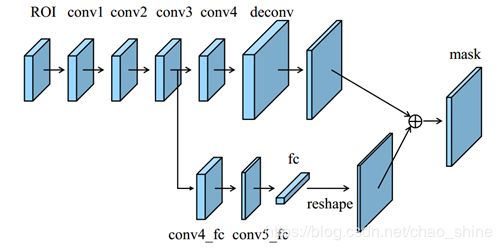 图10 全连接融合的掩模预测分支
图10 全连接融合的掩模预测分支
对上图的一个简单的介绍:
- 主干路线是一个小的FCN,包含了4个连续的卷积层和一个反卷积层。每一个卷积层包括了256个的卷积核,同时将反卷积的上采样因素设为2。这个分支的作用和Mask R-CNN一样,对每一个类分别给出一个二进制的掩模,以解耦分割和分类任务。
- 使用一个短路径从连接到层,中间过两个卷积层
 ,
,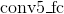 ,其中卷积层通道数减半以减少计算量。
,其中卷积层通道数减半以减少计算量。 - 掩模大小设置为
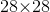 ,所以全连接层产生
,所以全连接层产生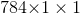 大小的向量,故需要重采样成和FPN预测的掩模同样的空间尺寸,再和FPN的输出相加得到最终预测。
大小的向量,故需要重采样成和FPN预测的掩模同样的空间尺寸,再和FPN的输出相加得到最终预测。
运用一个全连接层就可以预测一个未知类的前景或者背景的掩模,不仅效率高,而且参数易训练,从而可以方便归一化。仅使用一个全连接层进行最后的预测,可以防止隐藏层的空间特征信息被映射成一个短的特征向量,从而丢失空间信息。
5、Experiments
该论文在COCO、Cityscapes和MVD数据集上进行了实验,均得到了最佳的效果。
5.1 实验细节(Implementation Details)
该论文基于Caffe实现了Mask R-CNN和FPN的效果,在实验中所使用到的预训练模型都是公开可用的。对于实验的每一张图片,以正负样例比3:1为前提选出512个ROI。Weight decay设置为0.0001,momentum设置为0.9,其他的相关参数的设置根据不同的数据集和实验进行设置。
候选区域来自独立的RPN,目标检测和实例分割的网络主干不共享。
5.2 在COCO上的实验 (Experiments on COCO)
A、数据集简单介绍和评价标准
COCO数据集的数据的复杂性足以为实例分割和物体检测使用,包括了115k张训练图片和5k张验证图片。评价指标采用常用的评价指标,例如![]() 、
、![]() 、
、![]() 、
、![]() 、和
、和![]() ,后面三项用于衡量不同尺度物体对象。
,后面三项用于衡量不同尺度物体对象。
B、参数的说明
训练的时候,如非特殊说明,16张图片为一个批,图像的分辨率为。在进行实例分割的时候,将前120k次的迭代学习率设置为0.02,后40k次迭代的学习率设置为0.002。在进行物体检测的时候,除了掩模生成的支路不被运行,其他的一样运行。物体检测的前60k次迭代的学习率设置为0.02,后来的20k次迭代学习率设置为0.0002。以上的参数均来自Mask R-CNN和FPN,没有经过微调。
C、实例分割的结果
表1 PANet在COCO数据集上实例分割的结果

以ResNet-50的PANet,在单尺度和多尺度的测试上均超过了2016年的冠军作品,并且比它训练起来更加的方便,不需要额外的技巧。
D、物体检测的结果
表2 PANet在COCO数据集上物体检测的结果
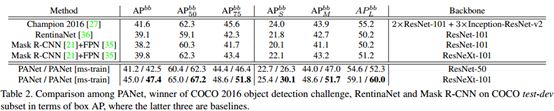
同样的可以看到该算法的优越性,从单尺度和多尺度上来看,均优于Mask R-CNN的现有的结果。
E、对比实验
这部分主要是来说明论文提出的每一项工作的优越性,除了分析自适应特征池化、自下而上的路径增强和全连接融合,论文还分析了多尺度训练、多GPU同步batch normalization和Heavier Head。具体的实验结果见表3,
表3 对比实验结果

⑴ Re-implemented Baseline:复现了Mask R-CNN的结果,相比之下本文的结果更好;
⑵ 多尺度训练和多GPU同步BN:实验表明这两个方法使得实验更快的收敛,泛化能力更好;
⑶ 自下而上的路径增强:在不用自适应特征池化的前提下,掩模的AP和框的分别达到了0.6和0.9;
⑷ 自适应特征池化:同上,不管有没有路径增强,在不同的尺度下,所有的结果都得到了提升;
⑸ 全连接融合:为掩模的生成提高了0.7的AP;
⑹ Heavier Head:多任务下可以很好的提升了回归框的框定,但是对于生成掩模和训练物体检测器作用比较的小。
F、针对自适应特征池化的对比研究
目的是为了找到融合的最佳位置,用![]() 表示融合的位置在ROIAlign和
表示融合的位置在ROIAlign和![]() 之间,用
之间,用![]() 表示融合的位置在
表示融合的位置在![]() 和之间。同时还测试了融合技术是采用最大化还是取和操作比较好,最终的结果如表4所示:
和之间。同时还测试了融合技术是采用最大化还是取和操作比较好,最终的结果如表4所示:
表4 自适应特征池化的对比图
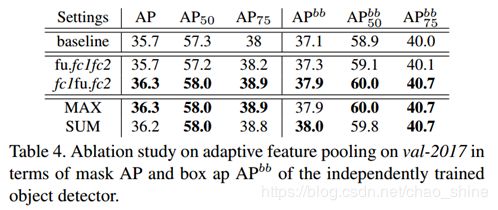
从上表中可以看出融合的位置应该在![]() 和之间,对于使用SUM还是MAX操作并不是很敏感,所以PANet采用了MAX操作。
和之间,对于使用SUM还是MAX操作并不是很敏感,所以PANet采用了MAX操作。
G、针对全连接融合的对比研究
这个对比试验主要是为了找增强全连接层的方法,论文从两方面考虑:
- 层的起始点,分别测试了从
 、
、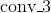 和
和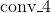 开始;
开始; - 和FCN融合技术,包括最大值、取和、乘积三种方法;
表5 全连接融合的对比实验
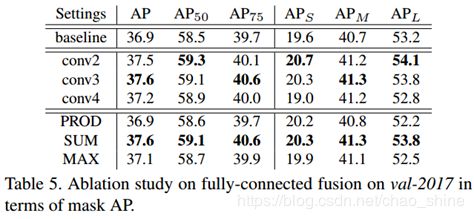
从图中可以看到,选择![]() 和
和![]() (取和)效果比较好。
(取和)效果比较好。
5.3 在Cityscapes上的实验 (Experiments on Cityscapes)
A、数据集简单介绍和评价标准
Cityscapes数据集包括了2975张训练图片,500张验证图片和1525张被细化后的测试图片。其他的20k张图片,除了用于训练的,都是粗化的。使用的评价标准是![]() 和
和![]() 。
。
B、参数设计
使用和Mask R-CNN一样的参数,需要说的是,训练时短边在![]() 之间随机采样,测试时使用1024。具体操作中没有使用DCN或者其他的技巧。以ResNet50作为基础层,0.01的学习率迭代了18K, 0.001的学习率迭代了6K,每个batch设置8张图片。
之间随机采样,测试时使用1024。具体操作中没有使用DCN或者其他的技巧。以ResNet50作为基础层,0.01的学习率迭代了18K, 0.001的学习率迭代了6K,每个batch设置8张图片。
如下表所示,对比了PANet与其他网络的效果:
表6 实验对比表
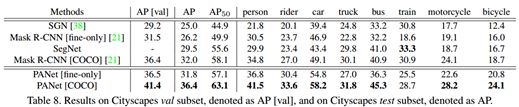
可以看到论文提出的方法很好的超过了顶尖的方法的结果。
5.3 在MVD上的实验 (Experiments on MVD)
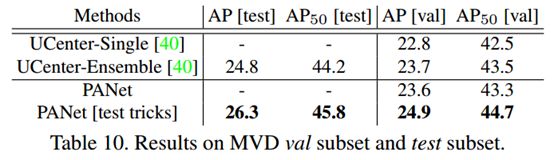
主要对比了UCenter效果:
表7 与UCenter的对比
5.4实验效果
具体实现的分割效果如图:
 图11 在COCO、Cityscapes和MVD上的测试效果
图11 在COCO、Cityscapes和MVD上的测试效果
未来的方向
使用在RGBD或者视频的数据集上。
论文贡献点
⑴ 使得各个层次的信息得到了充分的应用,路径增强;
⑵ 论文的结构安排比较的清楚;
⑶ GPU的使用细节给了简单的介绍;
论文前提知识:
⑴ FPN(参考1和参考2)
⑵ 进阶ROI Align
⑶ DenseNet
产生的问题
在上面的结构写了,Ratio of features pooled from different feature levels with adaptive feature pooling中的Ratio怎么来的?没介绍,没找到。
参考文献
- He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. international conference on computer vision, 2017: 2980-2988.
- Girshick R B. Fast R-CNN[J]. international conference on computer vision, 2015: 1440-1448.
- Ren S, He K, Girshick R B, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
- Lin T, Dollar P, Girshick R B, et al. Feature Pyramid Networks for Object Detection[J]. computer vision and pattern recognition, 2017: 936-944.
- Lin T, Maire M, Belongie S J, et al. Microsoft COCO: Common Objects in Context[J]. european conference on computer vision, 2014: 740-755.
- Cordts M, Omran M, Ramos S, et al. The Cityscapes Dataset for Semantic Urban Scene Understanding[J]. computer vision and pattern recognition, 2016: 3213-3223.
- Neuhold G, Ollmann T, Bulo S R, et al. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes[C]. international conference on computer vision, 2017: 5000-5009.
- Girshick R B, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. computer vision and pattern recognition, 2014: 580-587.
- He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[C]. european conference on computer vision, 2014: 346-361.
- Ren S, He K, Girshick R B, et al. Object Detection Networks on Convolutional Feature Maps[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(7): 1476-1481.
- Gidaris S, Komodakis N. Object Detection via a Multi-region and Semantic Segmentation-Aware CNN Model[J]. international conference on computer vision, 2015: 1134-1142.
- Zeiler M D, Fergus R. Visualizing and Understanding Convolutional Networks[J]. european conference on computer vision, 2014: 818-833.
附录
附录一:
术语对照表
| 英语表达 |
中文翻译 |
| Lateral Connection |
横向连接 |
| Dimension Reduction |
降维 |
| Information Propagate |
信息传播 |
| Adaptive Feature Pooling |
自适应特征池化 |
| Bottom-Up / Top-Down |
自下而上/自上而下 |
| Feature Grid |
特征网格 |
| Dense Connection |
密集连接 |
| MCG(Multiscale Combinatorial Grouping) |
多尺度组合分组 |
| Fully-connected Fusion |
全连接融合 |
| Synchronized batch normalization |
同步批归一化 |
[1] http://cocodataset.org/
[2] https://www.cityscapes-dataset.com/
[3] https://blog.csdn.net/u011974639/article/details/79595179