Python机器学习及实践——进阶篇4(模型正则化之L1正则&L2正则)
正则化的目的在于提高模型在未知测试数据上的泛化力,避免参数过拟合。由上一篇的例子可以看出,2次多项式回归是相对较好的模型假设。之所以出现如4次多项式那样的过拟合情景,是由于4次方项对于的系数过大,或者不为0导致。
因此正则化的常见方法都是在原模型优化目标的基础上,增加对参数的惩罚项。以我们之前在线性回归器一节中介绍过的最小二乘优化目标为例,如果加入对模型的L1范数正则化,那么新的线性回归目标如下式所示:

也就是在原优化目标的基础上,增加了参数向量的L1范数。这样在新目标优化的过程中同时需要考量L1惩罚项的影响。为了使目标最小化,这种正则化方法的结果会让参数向量中许多元素趋向于0,使得大部分特征失去对优化目标的贡献。这种让有效特征变得稀疏的L1正则化模型,通常被称为Lasso。
接下来我们用下述代码在上一篇例子的基础上,继续使用4次多项式特征,但是换成Lasso模型检验L1范数正则化后的性能和参数。
# 从sklearn.linear_model中导入Lasso。
from sklearn.linear_model import Lasso
# 从使用默认配置初始化Lasso。
lasso_poly4 = Lasso()
# 从使用Lasso对4次多项式特征进行拟合。
lasso_poly4.fit(X_train_poly4, y_train)
# 对Lasso模型在测试样本上的回归性能进行评估。
print lasso_poly4.score(X_test_poly4, y_test)0.83889268736
# 输出Lasso模型的参数列表。
print lasso_poly4.coef_[ 0.00000000e+00 0.00000000e+00 1.17900534e-01 5.42646770e-05
-2.23027128e-04]
# 回顾普通4次多项式回归模型过拟合之后的性能。
print regressor_poly4.score(X_test_poly4, y_test)0.809588079578
# 回顾普通4次多项式回归模型的参数列表。
print regressor_poly4.coef_[[ 0.00000000e+00 -2.51739583e+01 3.68906250e+00 -2.12760417e-01
4.29687500e-03]
通过对代码一系列输出的观察,验证了我们所介绍的Lasso模型的特点:
- 相比于普通4次多项式回归模型在测试集上的表现,默认配置的Lasso模型性能提高了大约3%;
- 相较之下,Lasso模型拟合后的参数列表中,4次与3次特征的参数均为0.0,使得特征更加稀疏。
L2范数正则化
与L1范数正则化略有不同的是,L2范数正则化则在原优化目标的基础上,增加了参数向量的L2范数的惩罚项,如下述公式所示。为了使新优化目标最小化,这种正则化方法的结果会让参数向量中的大部分元素都变得很小,压制了参数之间的差异性。这种正则化模型通常被称为Ridge。
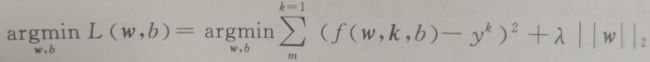
我们同样使用代码,继续对4次多项式特征换成Ridge模型检验L2范数正则化后的性能和参数。
# 输出普通4次多项式回归模型的参数列表。
print regressor_poly4.coef_[[ 0.00000000e+00 -2.51739583e+01 3.68906250e+00 -2.12760417e-01
4.29687500e-03]]
# 输出上述这些参数的平方和,验证参数之间的巨大差异。
print np.sum(regressor_poly4.coef_ ** 2)647.382645692
# 从sklearn.linear_model导入Ridge。
from sklearn.linear_model import Ridge
# 使用默认配置初始化Riedge。
ridge_poly4 = Ridge()
# 使用Ridge模型对4次多项式特征进行拟合。
ridge_poly4.fit(X_train_poly4, y_train)
# 输出Ridge模型在测试样本上的回归性能。
print ridge_poly4.score(X_test_poly4, y_test)0.837420175937
# 输出Ridge模型的参数列表,观察参数差异。
print ridge_poly4.coef_[[ 0. -0.00492536 0.12439632 -0.00046471 -0.00021205]]
# 计算Ridge模型拟合后参数的平方和。
print np.sum(ridge_poly4.coef_ ** 2)0.0154989652036
通过对上述输出的观察,可以验证Ridge模型的特点:
- 相比于普通4次多项式回归模型在测试集上的表现,默认配置的Ridge模型性能提高了近3%;
- 与普通4次多项式回归模型不同的是,Ridge模型拟合后的参数之间差异非常小。
这里需要指出的是,上面两个公式中的惩罚项,都有一个因子λ进行调节。尽管λ不属于需要拟合的参数,却在模型优化中扮演非常重要的角色。具体对λ的解读,会留在后续。