爬虫之MySQL存储上
一 点睛
在Python 2中,连接MySQL的库大多是使用MySQLdb,但是此库的官方并不支持Python 3,这里推荐使用的库是PyMySQL。
二 安装
(venv) E:\WebSpider>pip install pymysql三 连接数据库
1 点睛
首先尝试连接一下数据库。假设当前的MySQL运行在本地,用户名为root,密码为123456,运行端口为3306。这里利用PyMySQL先连接MySQL,然后创建一个新的数据库,名字叫作spiders。
2 代码
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306)
cursor = db.cursor()
cursor.execute('SELECT VERSION()')
data = cursor.fetchone()
print('Database version:', data)
cursor.execute("CREATE DATABASE spiders DEFAULT CHARACTER SET utf8")
db.close()3 结果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/5_2_1.py
Database version: ('5.7.22',)4 说明
这里通过PyMySQL的connect()方法声明一个MySQL连接对象db,此时需要传入MySQL运行的host(即IP)。由于MySQL在本地运行,所以传入的是localhost。如果MySQL在远程运行,则传入其公网IP地址。后续的参数user即用户名,password即密码,port即端口(默认为3306)。
连接成功后,需要再调用cursor()方法获得MySQL的操作游标,利用游标来执行SQL语句。这里我们执行了两句SQL,直接用execute()方法执行即可。第一句SQL用于获得MySQL的当前版本,然后调用fetchone()方法获得第一条数据,也就得到了版本号。第二句SQL执行创建数据库的操作,数据库名叫作spiders,默认编码为UTF-8。由于该语句不是查询语句,所以直接执行后就成功创建了数据库spiders。接着,再利用这个数据库进行后续的操作。
四 创建表
1 点睛
一般来说,创建数据库的操作只需要执行一次就好了。当然,我们也可以手动创建数据库。以后,我们的操作都在spiders数据库上执行。
创建数据库后,在连接时需要额外指定一个参数db。
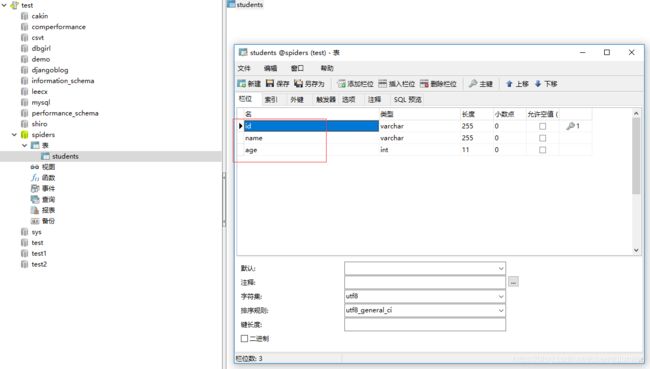
接下来,新创建一个数据表students,此时执行创建表的SQL语句即可。这里指定3个字段。
| 字段名 |
含义 |
类型 |
| id |
学号 |
varchar |
| name |
姓名 |
varchar |
| age |
年龄 |
int |
2 代码
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS students (id VARCHAR(255) NOT NULL, name VARCHAR(255) NOT NULL, age INT NOT NULL, PRIMARY KEY (id))'
cursor.execute(sql)
db.close()3 结果
五 插入数据
1 基本方法
1.1 需求
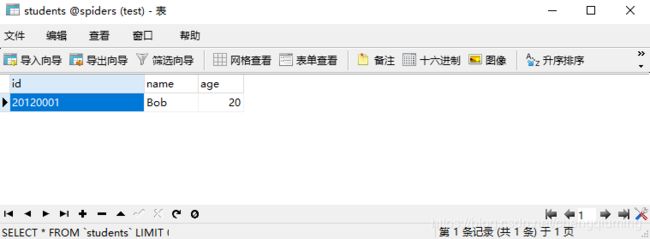
这里爬取了一个学生信息,学号为20120001,名字为Bob,年龄为20,现在需要将该条数据插入数据库。
1.2 代码
import pymysql
id = '20120001'
user = 'Bob'
age = 20
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO students(id, name, age) values(%s, %s, %s)'
try:
cursor.execute(sql, (id, user, age))
db.commit()
except:
db.rollback()
db.close()1.3 结果
1.4 说明
我们这里选择直接用格式化符%s来实现。有几个Value写几个%s,我们只需要在execute()方法的第一个参数传入该SQL语句,Value值用统一的元组传过来就好了。这样的写法既可以避免字符串拼接的麻烦,又可以避免引号冲突的问题。
之后值得注意的是,需要执行db对象的commit()方法才可实现数据插入,这个方法才是真正将语句提交到数据库执行的方法。对于数据插入、更新、删除操作,都需要调用该方法才能生效。
接下来,我们加了一层异常处理。如果执行失败,则调用rollback()执行数据回滚,相当于什么都没有发生过。
这里涉及事务的问题。事务机制可以确保数据的一致性,也就是这件事要么发生了,要么没有发生。比如插入一条数据,不会存在插入一半的情况,要么全部插入,要么都不插入,这就是事务的原子性。另外,事务还有3个属性——一致性、隔离性和持久性。
这4个属性通常称为ACID特性。
| 属性 |
解释 |
| 原子性(atomicity) |
事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做 |
| 一致性(consistency) |
事务必须使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的 |
| 隔离性(isolation) |
一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰 |
| 持久性(durability) |
持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响 |
插入、更新和删除操作都是对数据库进行更改的操作,而更改操作都必须为一个事务,所以这些操作的标准写法就是:
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()2 优化后的插入语句——动态插入
1 点睛
SQL语句会根据字典动态构造,元组也动态构造,这样才能实现通用的插入方法。
2 代码
import pymysql
data = {
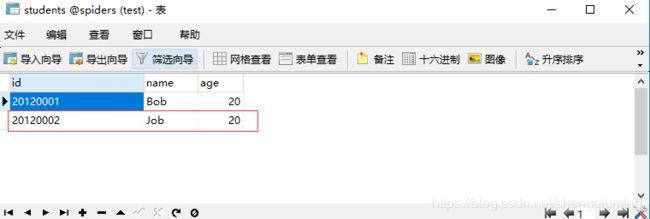
'id': '20120002',
'name': 'Job',
'age': 20
}
table = 'students'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
try:
if cursor.execute(sql, tuple(data.values())):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()3 结果
4 说明
这里我们传入的数据是字典,并将其定义为data变量。表名也定义成变量table。接下来,就需要构造一个动态的SQL语句了。
首先,需要构造插入的字段id、name和age。这里只需要将data的键名拿过来,然后用逗号分隔即可。所以', '.join(data.keys())的结果就是id, name, age,然后需要构造多个%s当作占位符,有几个字段构造几个即可。比如,这里有三个字段,就需要构造%s, %s, %s。这里首先定义了长度为1的数组['%s'],然后用乘法将其扩充为['%s', '%s', '%s'],再调用join()方法,最终变成%s, %s, %s。最后,我们再利用字符串的format()方法将表名、字段名和占位符构造出来。最终的SQL语句就被动态构造成了:
INSERT INTO students(id, name, age) VALUES (%s, %s, %s)最后,为execute()方法的第一个参数传入sql变量,第二个参数传入data的键值构造的元组,就可以成功插入数据了。
如此以来,我们便实现了传入一个字典来插入数据的方法,不需要再去修改SQL语句和插入操作了。