用TensorFlow训练一个物体检测器(手把手教学版)
TensorFlow内包含了一个强大的物体检测API,我们可以利用这API来训练自己的数据集实现特殊的目标检测。
作者软硬件环境配置:
CPU: i7-6800k (不重要,主流的CPU均可)
OS: Ubuntu Linux 16.04 LTS 优麒麟版
内存:16G
硬盘:ssd
显卡:NVIDIA GEFORCE GTX 1080TI 11G (显存越大越好,cuda核心数越多越好,我在训练时,使用GPU,速度会比使用CPU快10-20倍)国外一位程序员分享了自己实现可爱的浣熊检测器的经历
原文地址(需要翻越那道墙):https://towardsdatascience.com/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9
原文作者的github:https://github.com/datitran/raccoon_dataset (作者的数据集可以在这里下载)
在文章中作者把检测器的训练流程进行了简要介绍,但过于粗略,初学者难以跟着实现。为了方便初学者,我把详细的步骤整理了一下,下面我们一起来学习一下吧!
为什么要做这件事?
方便面君不仅可爱,在国外很普遍的与人们平静地生活在一起。处于对它的喜爱和与浣熊为邻的情况,作者选择了它作为检测器的检测对象。完成后可以将摄像安装在房子周围,检测是否有浣熊闯入了你家,你就能及时知道是否来了不速之客了。看来浣熊还真多啊!

一、创建数据集
机器学习需要数据作为原料,那么我们首先需要做的就是建立起一个可供训练的数据集,同时我们需要利用符合Tensorflow的数据格式来保存这些数据及其标签。
1.在准备输入数据之前你需要考虑两件事情:其一,你需要一些浣熊的彩色图片;其二,你需要在图中浣熊的位置框坐标(xmin,ymin,xmax,ymax)来定位浣熊的位置并进行分类。对于只检测一种物体来说我们的任务十分简单,只需要定义一类就可以了;
2.哪里去找数据呢?互联网是最大的资源啦。包括各大搜索引擎的图片搜索和图像网站,寻找一些不同尺度、位姿、光照下的图片。作者找了大概两百张的浣熊图片来训练自己的检测器(数据量有点小,但是来练手还是可以的,其实imagenet上有浣熊的数据集的,有心的朋友可以去下载,注册imagenet是需要翻越高墙的,否则看不到验证码);

3.有了数据以后我们需要给他们打标签。分类很简单,都是浣熊,但是我们需要手动在每一张图中框出浣熊的位置。一个比较好的打标工具是LabelImg, 关于图片打标,请参考我的另一篇文章《手把手教你图片打标》
4、到目前为止,我们有了一些浣熊的图片以及这些图片的标注文件(annotation)(如果你比较懒,可以从原文作者的GITHUB里下载这些图片和标注文件https://github.com/datitran/raccoon_dataset, 这里我就直接下载原文作者的标注文件和图片)
 (点击Download ZIP即可下载整个工程)
(点击Download ZIP即可下载整个工程)
5、我们把下载好的ZIP包解压,如下,annotations目录就是标注文件,images目录就是图像文件,标注文件raccoon-1.xml里的filename节点就是它对应的图片文件的文件名,需要特别说明的是,raccoon这个数据集里面的标注文件xml里的filename是png后缀,而实际我们下载到的图片是是jpg格式的,估计是原作者转换了格式,因此,在后文中,我们需要对这个filename做一点小处理。解压出来的其他文件我们都不需要,全部删掉,后面我们会一步步自己写出那些文件的。
6.最后,将图片及图像的标签转换为TFRecord格式,并将起分为训练集和验证集就可以开始下一步的工作了!用LabelImg标注的文件是PASCAL VOC格式的,tensorflow提供了一个脚本将PASCAL VOC格式的标注文件和相应的图片转换为TFRecord,不过,要用这个脚本,我们需要先搭建TensorFlow环境以及安装TensorFlow object detection api ,关于这两个部分,请参阅我的系列文章《Ubuntu 16.04下搭建TensorFlow运行环境(用Anaconda)》《Ubuntu 16.04下安装TensorFlow Object Detection API(对象检测API)》,后文假设你已经按照这两篇文章搭建好了环境。
二、将图片和标注转换为TFRecord格式
2.1 在~/tensorflow/models/research/object_detection/dataset_tools目录下(~表示当前用户主目录,下同)找到create_pascal_tf_record.py 文件,这个就是tensorflow提供的将pascal voc格式转换为TFRecord格式的脚本,执行如下脚本,将其复制一份,只不过这个脚本是针对pascal voc数据集的目录结构编写的,所以我们需要编辑修改一下它:
(root) forest@forest-MS-7A20:~/tensorflow/models/research$ cp object_detection/dataset_tools/create_pascal_tf_record.py object_detection/dataset_tools/create_pascal_tf_record4raccoon.py
(root) forest@forest-MS-7A20:~/tensorflow/models/research$ gedit object_detection/dataset_tools/create_pascal_tf_record4raccoon.py具体修改的行太多,这里就不一一说明了,下面提供了完整的create_pascal_tf_record4raccoon.py文件代码。
# -*- coding:utf-8 -*-
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Convert raw PASCAL dataset to TFRecord for object_detection.
Example usage:
python object_detection/dataset_tools/create_pascal_tf_record4raccoon.py \
--data_dir=/home/forest/dataset/raccoon_dataset-master/images \
--set=/home/forest/dataset/raccoon_dataset-master/train.txt \
--output_path=/home/forest/dataset/raccoon_dataset-master/train.record \
--label_map_path=/home/forest/dataset/raccoon_dataset-master/raccoon_label_map.pbtxt \
--annotations_dir=/home/forest/dataset/raccoon_dataset-master/annotations
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import hashlib
import io
import logging
import os
from lxml import etree
import PIL.Image
import tensorflow as tf
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '', 'Root directory to raw PASCAL VOC dataset.')
flags.DEFINE_string('set', 'train', 'Convert training set, validation set or '
'merged set.')
flags.DEFINE_string('annotations_dir', 'Annotations',
'(Relative) path to annotations directory.')
flags.DEFINE_string('year', 'VOC2007', 'Desired challenge year.')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
flags.DEFINE_string('label_map_path', 'data/pascal_label_map.pbtxt',
'Path to label map proto')
flags.DEFINE_boolean('ignore_difficult_instances', False, 'Whether to ignore '
'difficult instances')
FLAGS = flags.FLAGS
SETS = ['train', 'val', 'trainval', 'test']
YEARS = ['VOC2007', 'VOC2012', 'merged']
def dict_to_tf_example(data,
dataset_directory,
label_map_dict,
ignore_difficult_instances=False,
image_subdirectory='JPEGImages'):
"""Convert XML derived dict to tf.Example proto.
Notice that this function normalizes the bounding box coordinates provided
by the raw data.
Args:
data: dict holding PASCAL XML fields for a single image (obtained by
running dataset_util.recursive_parse_xml_to_dict)
dataset_directory: Path to root directory holding PASCAL dataset
label_map_dict: A map from string label names to integers ids.
ignore_difficult_instances: Whether to skip difficult instances in the
dataset (default: False).
image_subdirectory: String specifying subdirectory within the
PASCAL dataset directory holding the actual image data.
Returns:
example: The converted tf.Example.
Raises:
ValueError: if the image pointed to by data['filename'] is not a valid JPEG
"""
# 下面这句里的replace就是针对reccoon的标注文件里的filename标签后缀错误而特别添加的
img_path = os.path.join(dataset_directory, data['filename'].replace('.png','.jpg').replace('.PNG','.jpg'))
full_path = img_path
with tf.gfile.GFile(full_path, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
if image.format != 'JPEG':
raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
width = int(data['size']['width'])
height = int(data['size']['height'])
xmin = []
ymin = []
xmax = []
ymax = []
classes = []
classes_text = []
truncated = []
poses = []
difficult_obj = []
for obj in data['object']:
difficult = bool(int(obj['difficult']))
if ignore_difficult_instances and difficult:
continue
difficult_obj.append(int(difficult))
xmin.append(float(obj['bndbox']['xmin']) / width)
ymin.append(float(obj['bndbox']['ymin']) / height)
xmax.append(float(obj['bndbox']['xmax']) / width)
ymax.append(float(obj['bndbox']['ymax']) / height)
classes_text.append(obj['name'].encode('utf8'))
classes.append(label_map_dict[obj['name']])
truncated.append(int(obj['truncated']))
poses.append(obj['pose'].encode('utf8'))
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}))
return example
def main(_):
#if FLAGS.set not in SETS:
# raise ValueError('set must be in : {}'.format(SETS))
#if FLAGS.year not in YEARS:
# raise ValueError('year must be in : {}'.format(YEARS))
data_dir = FLAGS.data_dir
years = ['VOC2007', 'VOC2012']
if FLAGS.year != 'merged':
years = [FLAGS.year]
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
label_map_dict = label_map_util.get_label_map_dict(FLAGS.label_map_path)
for year in years:
logging.info('Reading from PASCAL %s dataset.', year)
examples_path = FLAGS.set
# 'aeroplane_' + FLAGS.set + '.txt')
annotations_dir = FLAGS.annotations_dir
examples_list = dataset_util.read_examples_list(examples_path)
for idx, example in enumerate(examples_list):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(examples_list))
path = os.path.join(annotations_dir, example + '.xml')
with tf.gfile.GFile(path, 'r') as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = dataset_util.recursive_parse_xml_to_dict(xml)['annotation']
tf_example = dict_to_tf_example(data, FLAGS.data_dir, label_map_dict,
FLAGS.ignore_difficult_instances)
writer.write(tf_example.SerializeToString())
writer.close()
if __name__ == '__main__':
tf.app.run()2.2 框架需要我们定义好我们的类别ID与类别名称的关系,通常用pbtxt格式文件保存,我们在~/dataset/raccoon_dataset-master/目录下新建一个名为raccoon_label_map.pbtxt的文本文件,内容如下:
item {
id: 1
name: 'raccoon'
}因为我们只有一个类别,所以这里就只需要定义1个item,若你有多个类别,就需要多个item,注意,id从1开始,name的值要和标注文件里的类别name相同,即你在图像打标的时候标记的是raccoon,这里就要写raccoon,不能写"浣熊".
2.3 我们需要用两个文本文件,来告诉转换脚本,哪些图片文件用来做训练集,哪些图片文件用来做验证集。在~/dataset/raccoon_dataset-master/目录下新建一个名为train.txt的文本文件,内容(这个清单是我用python脚本生成的,人工取前160张作为训练集,后40张作为验证集)如下:
raccoon-194
raccoon-101
raccoon-4
raccoon-105
raccoon-97
raccoon-113
raccoon-48
raccoon-108
raccoon-156
raccoon-55
raccoon-161
raccoon-2
raccoon-59
raccoon-18
raccoon-41
raccoon-126
raccoon-79
raccoon-23
raccoon-92
raccoon-58
raccoon-153
raccoon-165
raccoon-182
raccoon-122
raccoon-95
raccoon-86
raccoon-6
raccoon-99
raccoon-46
raccoon-130
raccoon-167
raccoon-186
raccoon-183
raccoon-177
raccoon-170
raccoon-179
raccoon-73
raccoon-82
raccoon-5
raccoon-10
raccoon-94
raccoon-30
raccoon-67
raccoon-85
raccoon-87
raccoon-112
raccoon-174
raccoon-196
raccoon-134
raccoon-133
raccoon-148
raccoon-13
raccoon-89
raccoon-16
raccoon-128
raccoon-150
raccoon-106
raccoon-120
raccoon-144
raccoon-137
raccoon-12
raccoon-140
raccoon-21
raccoon-141
raccoon-107
raccoon-47
raccoon-29
raccoon-115
raccoon-25
raccoon-124
raccoon-3
raccoon-1
raccoon-131
raccoon-50
raccoon-103
raccoon-80
raccoon-71
raccoon-42
raccoon-142
raccoon-176
raccoon-149
raccoon-33
raccoon-132
raccoon-118
raccoon-26
raccoon-65
raccoon-43
raccoon-200
raccoon-135
raccoon-154
raccoon-93
raccoon-22
raccoon-36
raccoon-69
raccoon-96
raccoon-114
raccoon-181
raccoon-84
raccoon-193
raccoon-68
raccoon-192
raccoon-70
raccoon-74
raccoon-88
raccoon-8
raccoon-34
raccoon-139
raccoon-91
raccoon-109
raccoon-27
raccoon-54
raccoon-52
raccoon-185
raccoon-136
raccoon-61
raccoon-127
raccoon-98
raccoon-155
raccoon-75
raccoon-28
raccoon-173
raccoon-57
raccoon-56
raccoon-187
raccoon-160
raccoon-35
raccoon-151
raccoon-175
raccoon-129
raccoon-20
raccoon-116
raccoon-66
raccoon-37
raccoon-180
raccoon-143
raccoon-40
raccoon-76
raccoon-111
raccoon-64
raccoon-24
raccoon-60
raccoon-168
raccoon-17
raccoon-32
raccoon-147
raccoon-117
raccoon-172
raccoon-189
raccoon-45
raccoon-81
raccoon-7
raccoon-63
raccoon-110
raccoon-198
raccoon-100
raccoon-39
raccoon-9
raccoon-19
raccoon-195
raccoon-197在~/dataset/raccoon_dataset-master/目录下新建一个名为val.txt的文本文件,内容如下:
raccoon-138
raccoon-90
raccoon-44
raccoon-152
raccoon-162
raccoon-190
raccoon-191
raccoon-51
raccoon-62
raccoon-102
raccoon-119
raccoon-178
raccoon-49
raccoon-184
raccoon-72
raccoon-157
raccoon-14
raccoon-163
raccoon-53
raccoon-188
raccoon-104
raccoon-169
raccoon-146
raccoon-164
raccoon-31
raccoon-166
raccoon-171
raccoon-78
raccoon-77
raccoon-145
raccoon-199
raccoon-123
raccoon-11
raccoon-83
raccoon-158
raccoon-125
raccoon-15
raccoon-159
raccoon-38
raccoon-121这个list可以用如下python脚本生成:
import os
import random
pt="/home/forest/dataset/raccoon_dataset-master/images/"
image_name=os.listdir(pt)
for temp in image_name:
if temp.endswith(".jpg"):
print temp.replace('.jpg','')2.4 运行我们编写的脚本,生成TFRecord文件
#from ~/tensorflow/models/research
python object_detection/dataset_tools/create_pascal_tf_record4raccoon.py \
--data_dir=/home/forest/dataset/raccoon_dataset-master/images \
--set=/home/forest/dataset/raccoon_dataset-master/train.txt \
--output_path=/home/forest/dataset/raccoon_dataset-master/train.record \
--label_map_path=/home/forest/dataset/raccoon_dataset-master/raccoon_label_map.pbtxt \
--annotations_dir=/home/forest/dataset/raccoon_dataset-master/annotations
如果输出 if not xml,说明执行成功,~/dataset/raccoon_dataset-master/train.record 就是我们需要训练集文件
接着执行如下脚本,生成验证集TFRecord文件:
python object_detection/dataset_tools/create_pascal_tf_record4raccoon.py \
--data_dir=/home/forest/dataset/raccoon_dataset-master/images \
--set=/home/forest/dataset/raccoon_dataset-master/val.txt \
--output_path=/home/forest/dataset/raccoon_dataset-master/val.record \
--label_map_path=/home/forest/dataset/raccoon_dataset-master/raccoon_label_map.pbtxt \
--annotations_dir=/home/forest/dataset/raccoon_dataset-master/annotations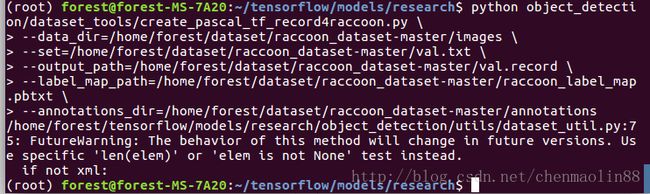
如果输出 if not xml,说明执行成功,~/dataset/raccoon_dataset-master/val.record 就是我们需要验证集文件
三、下载预训练模型

四、修改训练配置文件
4.1 复制object_detection/samples/configs下的ssd_mobilenet_v1_coco.config 到 ~/dataset/raccoon_dataset-master/下,重命名为ssd_mobilenet_v1_raccoon.config,并做如下修改:
# SSD with Mobilenet v1 configuration for MSCOCO Dataset.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
ssd {
num_classes: 1
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
。。。
train_config: {
batch_size: 24
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
fine_tune_checkpoint: "/home/forest/tensorflow/models/research/object_detection/ssd_mobilenet_v1_coco_2017_11_17/model.ckpt"
from_detection_checkpoint: true
# Note: The below line limits the training process to 200K steps, which we
# empirically found to be sufficient enough to train the pets dataset. This
# effectively bypasses the learning rate schedule (the learning rate will
# never decay). Remove the below line to train indefinitely.
num_steps: 200000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "/home/forest/dataset/raccoon_dataset-master/train.record"
}
label_map_path: "/home/forest/dataset/raccoon_dataset-master/raccoon_label_map.pbtxt"
}
eval_config: {
num_examples: 40
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
metrics_set:"pascal_voc_metrics"
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "/home/forest/dataset/raccoon_dataset-master/val.record"
}
label_map_path: "/home/forest/dataset/raccoon_dataset-master/raccoon_label_map.pbtxt"
shuffle: false
num_readers: 1
}
五、开始训练
在object_detection路径下,执行下面的命令,开始训练,:
# 从 ~/tensorflow/models/research/object_detection 目录下运行如下命令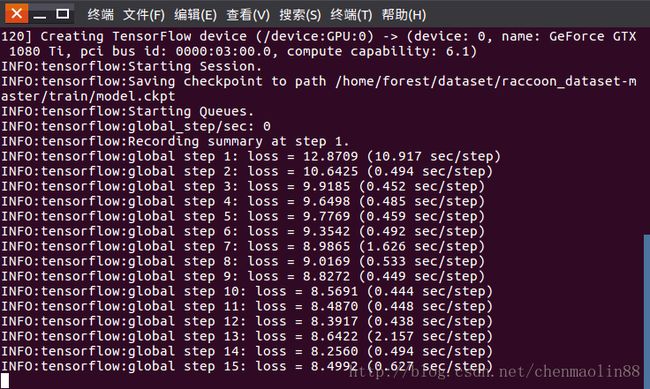
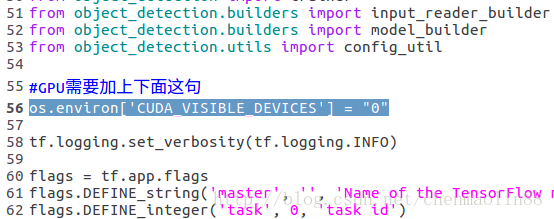
若是GPU,则需要在train.py文件的第55行,加入下面这句:
#GPU需要加上下面这句,0表示第1块GPU设备
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
你可以随时在终端里按ctrl+c,终止训练,那么我们什么时候结束训练呢?请看下面。
六、用验证集评估训练效果(可选)
在~/dataset/raccoon_dataset-master/目录下新建一个eval目录,用于保存eval的文件。另开终端,执行如下命令
(root) forest@forest-MS-7A20:~/tensorflow/models/research/object_detection$ python eval.py \
--logtostderr \
--pipeline_config_path=/home/forest/dataset/raccoon_dataset-master/ssd_mobilenet_v1_raccoon.config \
--checkpoint_dir=/home/forest/dataset/raccoon_dataset-master/train \
--eval_dir=/home/forest/dataset/raccoon_dataset-master/eval保持这个终端一直运行,在训练结束时,再CTRL+C结束eval
七、用TensorBoard查看训练进程
为了更方便 TensorFlow 程序的理解、调试与优化,谷歌发布了一套叫做 TensorBoard 的可视化工具。你可以用 TensorBoard 来展现你的 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据。TensorBoard 通过读取 TensorFlow 的事件文件来运行。TensorFlow 的事件文件包括了你会在 TensorFlow 运行中涉及到的主要数据。
新打开一个终端,运行如下指令:
(root) forest@forest-MS-7A20:~$ source activate root
(root) forest@forest-MS-7A20:~$ tensorboard --logdir=/home/forest/dataset/raccoon_dataset-master/

在浏览器中打开上图中出来的http地址,即可看到TensorBoard的主界面,可以看出来,在20k step之前,loss下降很快,之后就波动很小了,经过一夜的训练,目前接近80k step了, mAP平均精确率为67%(由于我是训练完之后再做的eval,所以这里是一条直线,在train时就一直开着eval的话,这里就应该是一条曲线了),我们几乎可以停止训练了。在训练的那个终端里按CTRL+C停止训练吧。
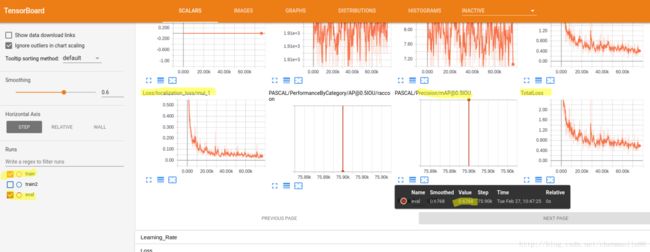

若你在train后,就开始跑了eval的话,你还可以像下面一样拖动滑动条来查看随着时间推移,识别效果的直观变化。
八、将检查点文件导出为冻结的模型文件
TensorFlow网络中含有大量的需要训练的变量,当训练结束时,这些变量的值就确定了,我们可以用下面的方法将训练的检查点文件里的变量替换为常量,导出成用于推断的模型文件。注意75895 部分根据你自己的最后一个检查点的编号来调整。
(root) forest@forest-MS-7A20:~/tensorflow/models-master/research/object_detection$ python export_inference_graph.py \
--pipeline_config_path=/home/forest/dataset/raccoon_dataset-master/ssd_mobilenet_v1_raccoon.config \
--trained_checkpoint_prefix=/home/forest/dataset/raccoon_dataset-master/train/model.ckpt-75895 \
--output_directory=/home/forest/dataset/raccoon_dataset-master/train
/home/forest/dataset/raccoon_dataset-master/train下的frozen_inference_graph.pb 文件就是我们宝贵的,最终要的模型文件。
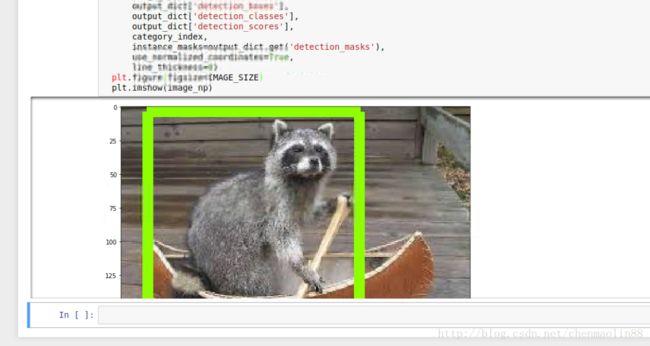
九、用模型进行浣熊的识别
打开《Ubuntu 16.04下安装TensorFlow Object Detection API(对象检测API)》里最后一步提到的DEMO,做如下修改:
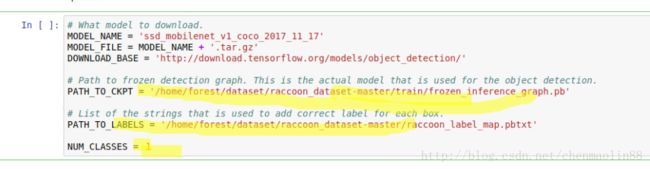
.....

单步运行每一行
最终结果如下