决策树应用实例③——银行借贷模型
决策树①——信息熵&信息增益&基尼系数
决策树②——决策树算法原理(ID3,C4.5,CART)
决策树③——决策树参数介绍(分类和回归)
决策树④——决策树Sklearn调参(GridSearchCV调参及过程做图)
决策树⑤——Python代码实现决策树
决策树应用实例①——泰坦尼克号分类
决策树应用实例②——用户流失预测模型
银行借贷是基于分析历史按时还款、逾期或不还的用户群体的各自特征建立模型,未来借款用户只要符合符合借款要求,就给予借贷,如果不符合,则拒绝。
本文将根据自建的一份包含借款人信息及银行是否借贷的数据集,创建一棵决策树,并进行预测。
一、数据集
下载:https://pan.baidu.com/s/1AtFKXSMYdD_G3M5UhTC1-w 提取码: oygj
二、字段介绍
① name_id: 姓名
② profession: 职业,1-企业工作者,2-个体经营户,3-自由工作者,4-事业单位,5-体力劳动者
③ education: 教育程度,1-博士及以上,2-硕士,3-本科,4-专科,5-高中及以下
④ house_loan: 是否有房贷,1-有,0-没有
⑤ car_loan:是否有车贷,1-有,0-没有
⑥ married: 是否结婚,1-是,0-否
⑦ child:是否有小孩,1-有,0-没有
⑧ revenue:月收入
⑨ approve:是否予以贷款,1-贷款,2-不贷款
三、导入数据
# 导入库
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
from IPython.display import Image
import pydotplus
from sklearn import tree
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV
# 导入数据
data = pd.read_csv('loan_data.txt',sep='\s+',encoding='utf-8',index_col='nameid')
print(data)
x = data.drop(['approve'],axis=1).values
print(x)
y = data['approve'].values
print(x.shape,y.shape)
四、划分训练集、验证集和测试集
# 划分训练集和测试集
x1 = x[:900]
y1 = y[:900]
x2 = x[900:]
y2 = y[900:]
# 在训练集中再划分出训练集和验证集
x_train,x_test,y_train,y_test = train_test_split(x1,y1,test_size=0.2)
五、建立模型
# 生成决策树
clf = DecisionTreeClassifier()
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print('训练集评分:', clf.score(x_train,y_train))
print('验证集评分:', clf.score(x_test,y_test))
print('测试集评分', clf.score(x2,y2))
print("查准率:", metrics.precision_score(y_test,y_pred))
print('召回率:',metrics.recall_score(y_test,y_pred))
print('f1分数:', metrics.f1_score(y_test,y_pred))
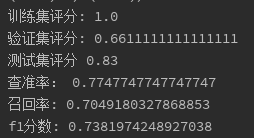
训练集评分为1,验证集和测试集均偏低,说明模型已经过拟合了,再通过混淆矩阵及分类报告查看更细节的信息
# 混淆矩阵查看分类结果
print(confusion_matrix(y_true=y_test,y_pred=y_pred,labels=list(set(y))))
# 分类报告查看各类的评分
print(metrics.classification_report(y_test,y_pred,labels=list(set(y))))
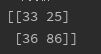
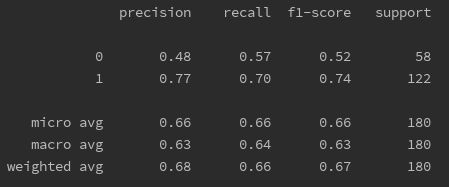
可以看到FP和FN都非常高,三项评分也都较低。此时可以通过GridSearchCV进行调参,减少过拟合
param = {'max_depth': [5,10,20],'min_samples_leaf': np.arange(3,10,1),'min_impurity_split':np.linspace(0.1,0.6,10),}
clf = GridSearchCV(DecisionTreeClassifier(),param_grid=param,cv=8)
clf.fit(x_train,y_train)
print(clf.best_params_,clf.best_score_)
![]()
通过上述调参,获得最佳的参数为 max_depth=5,min_impurity_split=0.378,min_sample_leaf=3 ,带入模型拟合可得
clf = DecisionTreeClassifier(max_depth=5,min_samples_split=5,min_impurity_split=0.37)
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
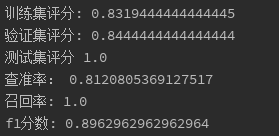
print('训练集评分:', clf.score(x_train,y_train))
print('验证集评分:', clf.score(x_test,y_test))
print('测试集评分', clf.score(x2,y2))
print("查准率:", metrics.precision_score(y_test,y_pred))
print('召回率:',metrics.recall_score(y_test,y_pred))
print('f1分数:', metrics.f1_score(y_test,y_pred))
print(confusion_matrix(y_true=y_test,y_pred=y_pred,labels=list(set(y))))
print(metrics.classification_report(y_test,y_pred,labels=list(set(y))))
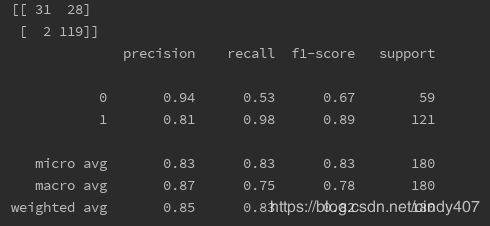
各项评分有了很大的提升,说明调参后确实在一定程度上减少了过拟合,提高了模型的泛化能力,对决策树进行可视化
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=data.columns[:-1],
class_names=data.columns[-1],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("银行借贷模型.pdf")
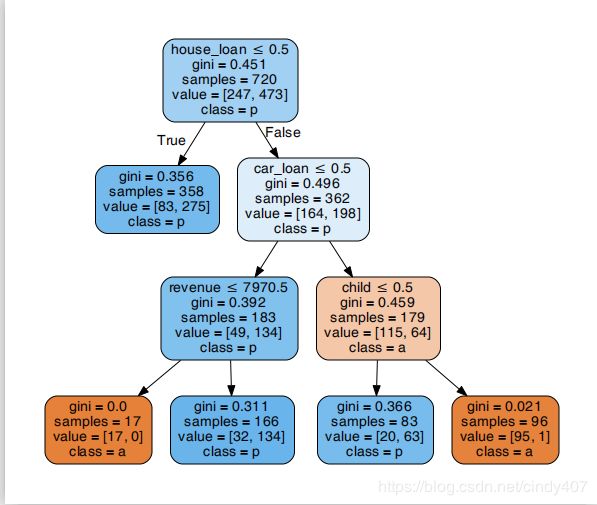
可以看出,经过剪枝后决策树变得非常简单,逻辑很清晰
① 如果用户没有房贷,则给予贷款
② 如果用户有房贷,但没有车贷,且月收入在7970元以上,就给予贷款
③ 如果用户有房贷也有车贷,但是没有孩子,也给予贷款