ELK日志检索系统--FileBeat配置说明
0. FileBeat使用说明
FileBeat是一个日志收集器,基于Logstash-Forwarder的源代码。FileBeat一般以代理的身份运行在服务器中,并监视用户指定的目录、文件,同时把日志文件更新部分推送给Logstash解析或者直接推送给ES索引。
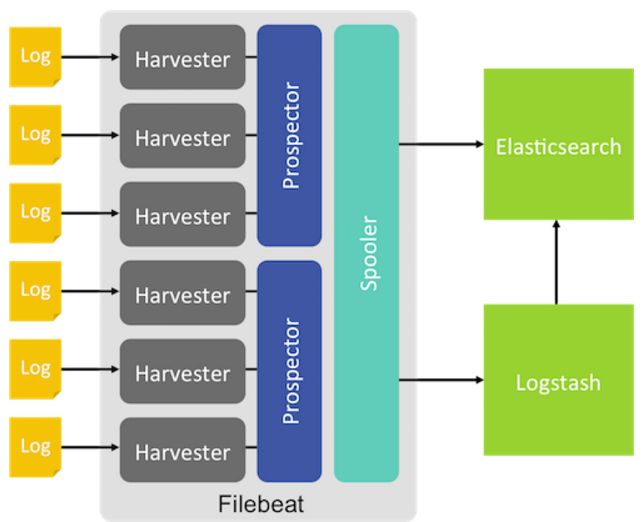
FileBeat的工作方式:
当FileBeat在服务器上启动后,它同时启动一个或者多个prospectors来监视用户指定的日志文件目录。
prospectors然后针对每个日志文件,都启动一个harvester,每一个harvester监视一个文件的新增内容,并把新增内容送到spooler中。然后spooler来汇总这些events事件。然后把这些事件传送给logstash或者es。
1. FileBeat的安装
FileBeat的使用与ES、Logstash基本一样,从官方网站下载*.tar.gz文件,然后解压。添加配置文件,然后就可以运行了。
deb:
curl -L -O https://download.elastic.co/beats/filebeat/filebeat_1.3.1_amd64.deb
sudo dpkg -i filebeat_1.3.1_amd64.debrpm:
curl -L -O https://download.elastic.co/beats/filebeat/filebeat-1.3.1-x86_64.rpm
sudo rpm -vi filebeat-1.3.1-x86_64.rpm如果用rpm或者deb的安装包,配置文件的位置在:
/etc/filebeat/filebeat.yml,下面是一个默认的配置文件:
filebeat:
# List of prospectors to fetch data.
prospectors:
# Each - is a prospector. Below are the prospector specific configurations
-
# Paths that should be crawled and fetched. Glob based paths.
# For each file found under this path, a harvester is started.
paths:
- "/var/log/*.log"
#- c:\programdata\elasticsearch\logs\*
# Type of the files. Based on this the way the file is read is decided.
# The different types cannot be mixed in one prospector
#
# Possible options are:
# * log: Reads every line of the log file (default)
# * stdin: Reads the standard in
input_type: log
......2. FileBeat文件路径配置、ES输出
设置日志文件的路径,每一个prospector监视一个路径(目录)。
/var/log/*/*.log这个路径代表log的所有子目录中的后缀为log的日志文件。但是不会监视log目录中的日志文件。
设置FileBeat的输出对象
如果output为ES,那么配置文件:
# Configure what outputs to use when sending the data collected by the beat.
# Multiple outputs may be used.
output:
### Elasticsearch as output
elasticsearch:
# Array of hosts to connect to.
hosts: ["192.168.1.42:9200"]参考链接:Configuring Filebeat
3. 设置Logstash为output对象
可以设置FileBeat的输出对象为Logstash,把FileBeat收集的数据推送到Logstash进行解析。
注释掉第二步骤中的ES的输出配置,添加下面的内容:
output:
logstash:
hosts: ["127.0.0.1:5044"]其中hosts指定了Logstash的IP地址和Logstash在其自己的配置文件中指定的监听端口。
如果把Logstash设置为输出对象,必须手动载入ES的索引模板。
通过./filebeat -configtest -e测试配置的FileBeat脚本
参考链接: Configuring Filebeat to Use Logstash
4. 在FileBeat中为ES设置索引模板
有了FileBeat以后,收集器是FileBeat,也只有FileBeat自己清楚其所监视的日志是什么格式。所以它可以为ES的索引定制模板。
推荐模板在FileBeat安装包里有默认的配置。
如果FileBeat的output是ES,那么可以在FileBeat的配置文件中设置ES索引模板。
如果FileBeat的output是logstash,那么必须手动载入ES索引模板。
FileBeat通过配置文件自动为ES载入索引模板(输出对象必须为ES):
output:
elasticsearch:
hosts: ["localhost:9200"]
# A template is used to set the mapping in Elasticsearch
# By default template loading is disabled and no template is loaded.
# These settings can be adjusted to load your own template or overwrite existing ones
template:
# Template name. By default the template name is filebeat.
#name: "filebeat"
# Path to template file
path: "filebeat.template.json"
# Overwrite existing template
#overwrite: false在启动FileBeat的时候,自动加载索引模板到ES中。如果索引模板已经存在于ES中,默认不会覆盖。如果把overwrite设置为true就可以覆盖存在的模板了。
手动载入ES索引模板的方法(输出对象为Logstash):
curl -XPUT 'http://localhost:9200/_template/filebeat' -d@/etc/filebeat/filebeat.template.jsonIf you’ve already used Filebeat to index data into Elasticsearch, the index may contain old documents. After you load the index template, you can delete the old documents from filebeat-* to force Kibana to look at the newest documents. Use this command。
curl -XDELETE 'http://localhost:9200/filebeat-*'
参考链接:Loading the Index Template in Elasticsearch
5. 启动FileBeat
deb:
sudo /etc/init.d/filebeat startrpm:
sudo /etc/init.d/filebeat start直接tar.gz压缩包:
sudo ./filebeat -e -c filebeat.yml -d "publish"
-d参数指定了调试的selectors,例如-d publish显示所有与publish相关的信息。不同的selectors用逗号分隔,-d "*"表示调试所有的信息。
之后FileBeat就按照设置的输入、输出传送数据了。
参考链接:Starting Filebeat
6. Loading the Kibana Index Pattern
参考链接:Loading the Kibana Index Pattern
7. Command Line Options
参考链接:Command Line Options