hive学习--查询语法
基本查询
select * from 表名;
select count(1) from 表名; -- 计数 单行函数
select max(ip) from 表名;----------使用max函数 聚合函数
select uid(字段名)from 表名 limit 10(数量);----------------------查询表中uid字段的头10条记录
条件查询
select 字段名 from 表名 where 条件字段>(大于)<(小于)=(等于)'值';
select 字段名 from 表名 where 条件 and 另一个条件;
关联查询
join 关联查询:on子句不支持非等值连接,不支持or连接多个条件,但是支持and;对每一对连接启动一次MR。
优化:将小表放前面,查询优化器自动优化。
使用hive的优化标识/*streamtable(a)*/,查询优化器自动优化,将a指向的emp表当做驱动表
select /*streamtable(a)*/ a.ename,b.dname from emp a join dept b on a.deptno=b.dno;
内连接:
不添加条件,会出现笛卡尔积。(select a.*,b.* from table_a a(table_a别名) join table_b b(table_b的别名))
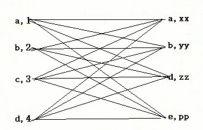 笛卡尔积
笛卡尔积
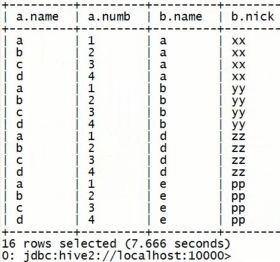
指定连接条件:用on(select a.*,b.* from table_a a join table_b b on a.name=b.name;不符合条件的均不显示)

外连接:
左外连接(也叫左连接):select a.*,b.* from table_a a left [outer] join table_b b;
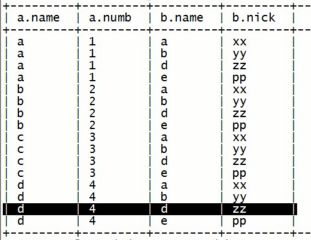
select a.*,b.* from table_a a left [outer] join table_b b on a.name=b.name; 左侧表为主表,内容全部显示

右外连接(也称右连接):select a.*,b.* from table_a a right [outer] join table_b b on a.name=b.name; 与左连接相反理解即可
全外连接:select a.*,b.* from table_a a full [outer] join table_b b;
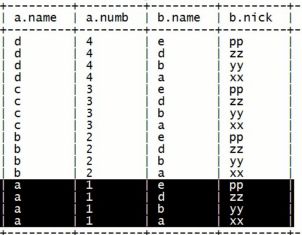
加入条件后:select a.*,b.* from table_a a full [outer] join table_b b on a.name=b.name;

左半连接:
select a.* from table_a a left semi join table_b b on a.name=b.name;只返回符合条件的左表数据,select子句中也不可以出现右表的字段

group by分组聚合查询-----与函数有关,select子句中只能出现group的字段与函数(其它字段)

针对一行运算的函数(upper 变成大写输出)select upper("abccc"); 输出后 ABCCC
select ip,uppper(url),access_time from 表名;----针对表达式逐行计算
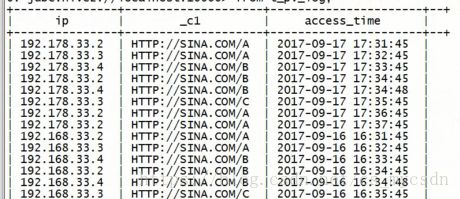
求每条URL的访问次数(针对多行的聚合函数)
select * from t_pv_log group by url;
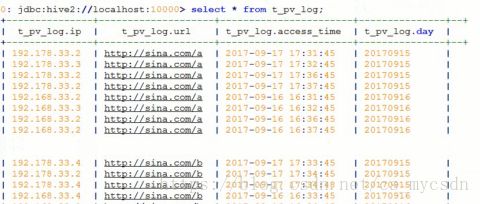
select url from t_pv_log group by url;
 说明有三种URL
说明有三种URL
select url,count(1) from t_pv_log group by url; ------count(1) 每有一个增加1。对分组后的数据逐组计算
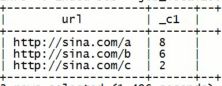
查询每一个用户访问同一个页面的所有记录中,时间最晚的一条
select ip,url,max(access_time) from t_pv_log group by url,ip;
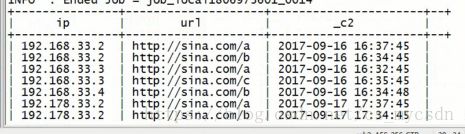
练习:
-- 求8月4号以后,每天http://www.edu360.cn/job的总访问次数,及访问者中ip地址中最大的
select dt,'http://www.edu360.cn/job',count(1),max(ip)
from t_access
where url='http://www.edu360.cn/job'
group by dt having dt>'2017-08-04';
select dt,max(url),count(1),max(ip)
from t_access
where url='http://www.edu360.cn/job'
group by dt having dt>'2017-08-04';
select dt,url,count(1),max(ip)
from t_access
where url='http://www.edu360.cn/job'
group by dt,url having dt>'2017-08-04';
select dt,url,count(1),max(ip)
from t_access
where url='http://www.edu360.cn/job' and dt>'2017-08-04'
group by dt,url;
子查询
-- 求8月4号以后,每天每个页面的总访问次数,及访问者中ip地址中最大的,且,只查询出总访问次数>2 的记录
-- 方式1:
select dt,url,count(1) as cnts,max(ip)
from t_access
where dt>'2017-08-04'
group by dt,url having cnts>2;
-- 方式2:用子查询
select dt,url,cnts,max_ip
from
(select dt,url,count(1) as cnts,max(ip) as max_ip
from t_access
where dt>'2017-08-04'
group by dt,url) tmp
where cnts>2;
ps:当同事使用where,group by,having,order by,语句的执行顺序为:
(1)首先执行where的条件,进行数据过滤;
(2)对过滤后的结果集按照group by选定的字段进行分组;
(3)对每个分组进行select查询,提取对应的列,有几组就执行几次;
(4)再进行having筛选每组数据;
(5)最后整体进行order by排序。