哪种 Python 程序员最赚钱?


作者 | XksA
责编 | 郭芮
本文以Python爬虫、数据分析、后端、数据挖掘、全栈开发、运维开发、高级开发工程师、大数据、机器学习、架构师这10个岗位,从拉勾网上爬取了相应的职位信息和任职要求,并通过数据分析可视化,直观地展示了这10个职位的平均薪资和学历、工作经验要求。
![]()
爬虫准备
1、先获取薪资和学历、工作经验要求
由于拉勾网数据加载是动态加载的,需要我们分析。分析方法如下:
F12分析页面数据存储位置
我们发现网页内容是通过post请求得到的,返回数据是json格式,那我们直接拿到json数据即可。
我们只需要薪资和学历、工作经验还有单个招聘信息,返回json数据字典中对应的英文为:positionId,salary, education, workYear(positionId为单个招聘信息详情页面编号)。相关操作代码如下:
文件存储:
def file_do(list_info):
# 获取文件大小
file_size = os.path.getsize(r'G:\lagou_anv.csv')
if file_size == 0:
# 表头
name = ['ID','薪资', '学历要求', '工作经验']
# 建立DataFrame对象
file_test = pd.DataFrame(columns=name, data=list_info)
# 数据写入
file_test.to_csv(r'G:\lagou_anv.csv', encoding='gbk', index=False)
else:
with open(r'G:\lagou_anv.csv', 'a+', newline='') as file_test:
# 追加到文件后面
writer = csv.writer(file_test)
# 写入文件
writer.writerows(list_info)
基本数据获取:
# 1. post 请求 url
req_url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 2.请求头 headers
headers = {
'Accept': 'application/json,text/javascript,*/*;q=0.01',
'Connection': 'keep-alive',
'Cookie': '你的Cookie值,必须加上去',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=',
'User-Agent': str(UserAgent().random),
}
def get_info(headers):
# 3.for 循环请求(一共30页)
for i in range(1, 31):
# 翻页
data = {
'first': 'true',
'kd': 'Python爬虫',
'pn': i
}
# 3.1 requests 发送请求
req_result = requests.post(req_url, data=data, headers=headers)
req_result.encoding = 'utf-8'
print("第%d页:"%i+str(req_result.status_code))
# 3.2 获取数据
req_info = req_result.json()
# 定位到我们所需数据位置
req_info = req_info['content']['positionResult']['result']
print(len(req_info))
list_info = []
# 3.3 取出具体数据
for j in range(0, len(req_info)):
salary = req_info[j]['salary']
education = req_info[j]['education']
workYear = req_info[j]['workYear']
positionId = req_info[j]['positionId']
list_one = [positionId,salary, education, workYear]
list_info.append(list_one)
print(list_info)
# 存储文件
file_do(list_info)
time.sleep(1.5)
运行结果:
2、根据获取到的`positionId`来访问招聘信息详细页面
根据`positionId`还原访问链接:
position_url = []
def read_csv():
# 读取文件内容
with open(r'G:\lagou_anv.csv', 'r', newline='') as file_test:
# 读文件
reader = csv.reader(file_test)
i = 0
for row in reader:
if i != 0 :
# 根据positionID补全链接
url_single = "https://www.lagou.com/jobs/%s.html"%row[0]
position_url.append(url_single)
i = i + 1
print('一共有:'+str(i-1)+'个')
print(position_url)访问招聘信息详情页面,获取职位描述(岗位职责和岗位要求)并清理数据:
def get_info():
for position_url in position_urls:
work_duty = ''
work_requirement = ''
response00 = get_response(position_url,headers = headers)
time.sleep(1)
content = response00.xpath('//*[@id="job_detail"]/dd[2]/div/p/text()')
# 数据清理
j = 0
for i in range(len(content)):
content[i] = content[i].replace('\xa0',' ')
if content[i][0].isdigit():
if j == 0:
content[i] = content[i][2:].replace('、',' ')
content[i] = re.sub('[;;.0-9。]','', content[i])
work_duty = work_duty+content[i]+ '/'
j = j + 1
elif content[i][0] == '1' and not content[i][1].isdigit():
break
else:
content[i] = content[i][2:].replace('、', ' ')
content[i] = re.sub('[、;;.0-9。]','',content[i])
work_duty = work_duty + content[i]+ '/'
m = i
# 岗位职责
write_file(work_duty)
print(work_duty)
# 数据清理
j = 0
for i in range(m,len(content)):
content[i] = content[i].replace('\xa0',' ')
if content[i][0].isdigit():
if j == 0:
content[i] = content[i][2:].replace('、', ' ')
content[i] = re.sub('[、;;.0-9。]', '', content[i])
work_requirement = work_requirement + content[i] + '/'
j = j + 1
elif content[i][0] == '1' and not content[i][1].isdigit():
# 控制范围
break
else:
content[i] = content[i][2:].replace('、', ' ')
content[i] = re.sub('[、;;.0-9。]', '', content[i])
work_requirement = work_requirement + content[i] + '/'
# 岗位要求
write_file2(work_requirement)
print(work_requirement)
print("-----------------------------")
运行结果:

duty
require
3、四种图可视化数据+数据清理方式
矩形树图:
# 1.矩形树图可视化学历要求
from pyecharts import TreeMap
education_table = {}
for x in education:
education_table[x] = education.count(x)
key = []
values = []
for k,v in education_table.items():
key.append(k)
values.append(v)
data = []
for i in range(len(key)) :
dict_01 = {"value": 40, "name": "我是A"}
dict_01["value"] = values[i]
dict_01["name"] = key[i]
data.append(dict_01)
tree_map = TreeMap("矩形树图", width=1200, height=600)
tree_map.add("学历要求",data, is_label_show=True, label_pos='inside')
玫瑰饼图:
# 2.玫瑰饼图可视化薪资
import re
import math
'''
# 薪水分类
parameter : str_01--字符串原格式:20k-30k
returned value : (a0+b0)/2 --- 解析后变成数字求中间值:25.0
'''
def assort_salary(str_01):
reg_str01 = "(\d+)"
res_01 = re.findall(reg_str01, str_01)
if len(res_01) == 2:
a0 = int(res_01[0])
b0 = int(res_01[1])
else :
a0 = int(res_01[0])
b0 = int(res_01[0])
return (a0+b0)/2
from pyecharts import Pie
salary_table = {}
for x in salary:
salary_table[x] = salary.count(x)
key = ['5k以下','5k-10k','10k-20k','20k-30k','30k-40k','40k以上']
a0,b0,c0,d0,e0,f0=[0,0,0,0,0,0]
for k,v in salary_table.items():
ave_salary = math.ceil(assort_salary(k))
print(ave_salary)
if ave_salary < 5:
a0 = a0 + v
elif ave_salary in range(5,10):
b0 = b0 +v
elif ave_salary in range(10,20):
c0 = c0 +v
elif ave_salary in range(20,30):
d0 = d0 +v
elif ave_salary in range(30,40):
e0 = e0 +v
else :
f0 = f0 + v
values = [a0,b0,c0,d0,e0,f0]
pie = Pie("薪资玫瑰图", title_pos='center', width=900)
pie.add("salary",key,values,center=[40, 50],is_random=True,radius=[30, 75],rosetype="area",is_legend_show=False,is_label_show=True)
普通柱状图:
# 3.工作经验要求柱状图可视化
from pyecharts import Bar
workYear_table = {}
for x in workYear:
workYear_table[x] = workYear.count(x)
key = []
values = []
for k,v in workYear_table.items():
key.append(k)
values.append(v)
bar = Bar("柱状图")
bar.add("workYear", key, values, is_stack=True,center= (40,60))
词云图:
import jieba
from pyecharts import WordCloud
import pandas as pd
import re,numpy
stopwords_path = 'H:\PyCoding\Lagou_analysis\stopwords.txt'
def read_txt():
with open("G:\lagou\Content\\ywkf_requirement.txt",encoding='gbk') as file:
text = file.read()
content = text
# 去除所有评论里多余的字符
content = re.sub('[,,。. \r\n]', '', content)
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
# quoting=3 表示stopwords.txt里的内容全部不引用
stopwords = pd.read_csv(stopwords_path, index_col=False,quoting=3, sep="\t", names=['stopword'], encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
test = words_stat.head(200).values
codes = [test[i][0] for i in range(0, len(test))]
counts = [test[i][1] for i in range(0, len(test))]
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("必须技能", codes, counts, word_size_range=[20, 100])
wordcloud.render("H:\PyCoding\Lagou_analysis\cloud_pit\ywkf_bxjn.html")![]()
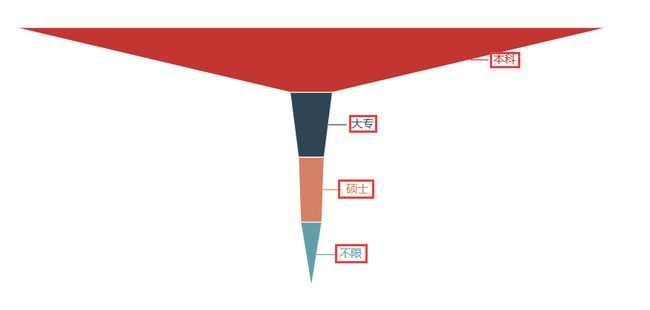
Python爬虫岗位
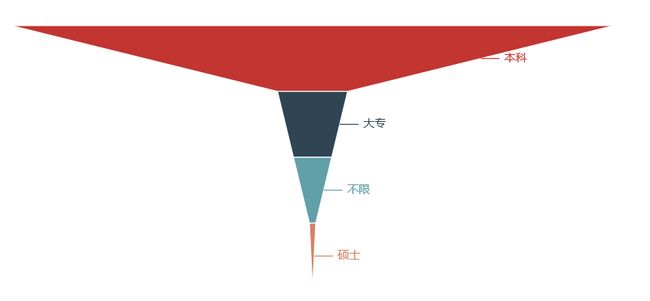
学历要求
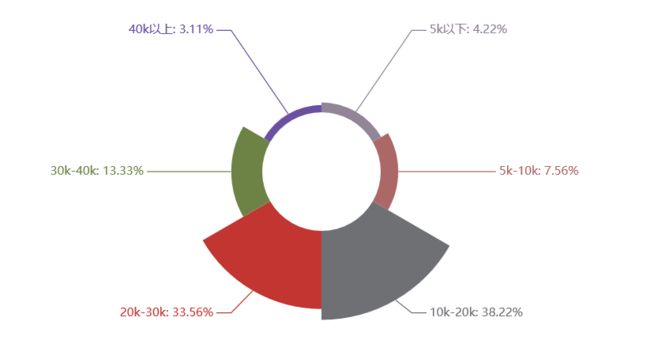
工作月薪
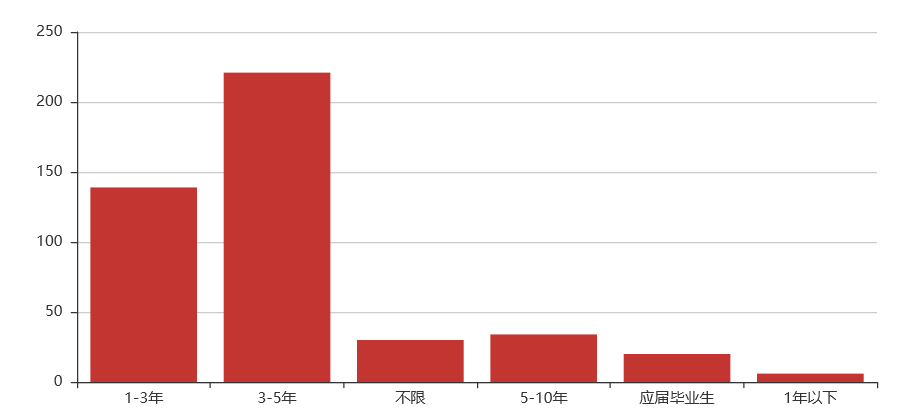
工作经验要求

爬虫技能
关键词解析:
学历:本科
工作月薪:10k-30k
工作经验:1-5年
技能:分布式、多线程、框架、Scrapy、算法、数据结构、数据库
综合:爬虫这个岗位在学历要求上比较放松,大多数为本科即可,比较适合想转业的老哥小姐姐,学起来也不会特别难。而且薪资待遇上也还算比较优厚,基本在10k以上。不过唯一对工作经验要求还是比较高的,有近一半的企业要求工作经验要达到3年以上。
![]()
Python数据分析岗位
学历要求
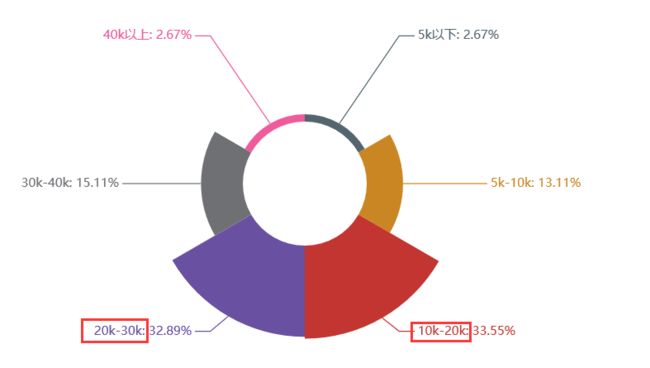
工作月薪
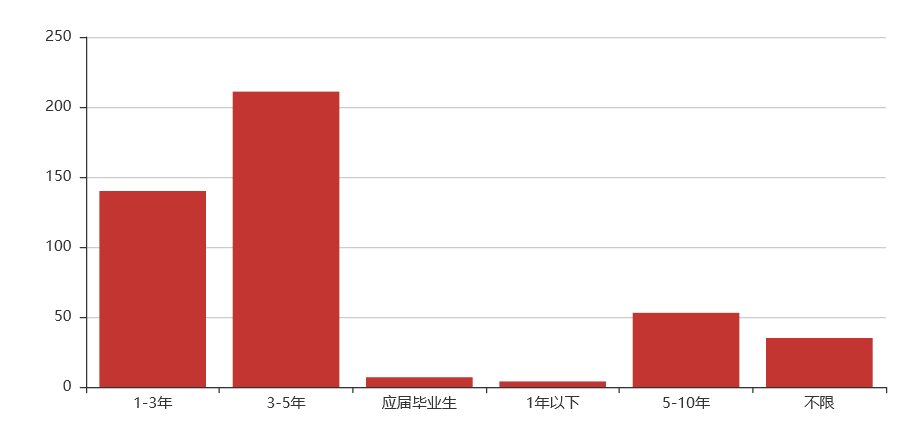
工作经验要求

数据分析技能
关键词解析:
学历:本科(硕士比例有所增高)
工作月薪:10k-30k
工作经验:1-5年
技能:SAS、SPSS、Hadoop、Hive、数据库、Excel、统计学、算法
综合:数据分析这个岗位在学历要求上比爬虫要求稍微高一些,硕士比例有所提升,专业知识上有一定要求。薪资待遇上也还算比较优厚,基本在10k以上,同时薪资在30k-40k的比例也有所上升。对工作经验要求还是比较高,大部分的企业要求工作经验要达到3年以上。
![]()
Python后端岗位
学历要求
工作月薪
工作经验要求
后端技能
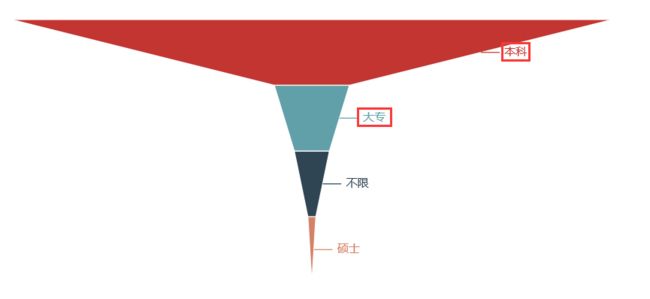
学历要求
工作月薪
工作经验要求

后端技能
关键词解析:
学历:本科
工作月薪:10k-30k
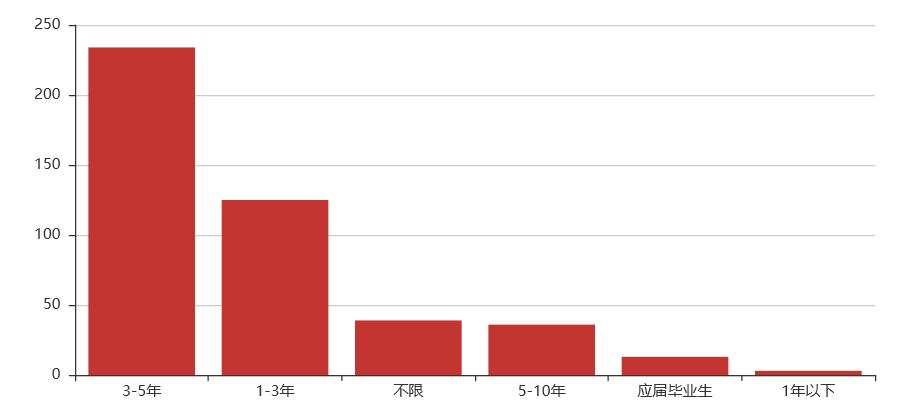
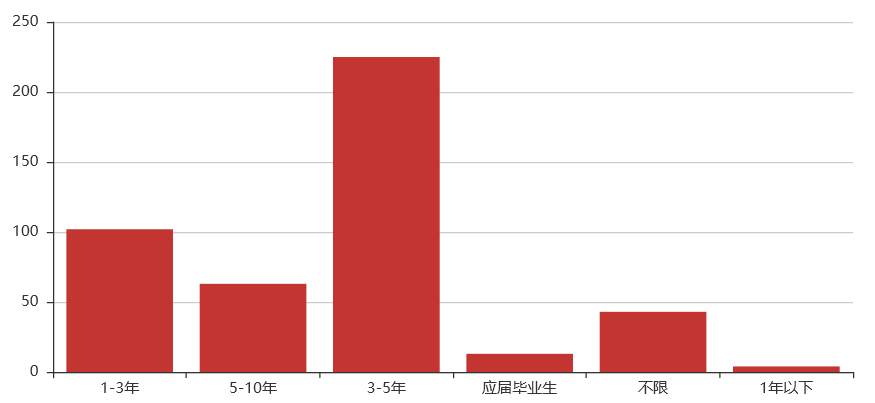
工作经验:3-5年
技能:Flask、Django、Tornado、Linux、MySql、Redis、MongoDB、TCP/IP、数学(哈哈)
综合:web后端这个岗位对学历要求不高,但专业知识上有很大要求,得会Linux操作系统基本操作、三大主流数据库的使用、以及三大基本web框架的使用等计算机相关知识,总体来说难道还是比较大。薪资待遇上也比较优厚,基本在10k以上,同时薪资在30k-40k的比例也有近20%。对工作经验要求还是比较高,大部分的企业要求工作经验要达到3年以上。
![]()
Python数据挖掘岗位
学历要求

工作月薪
工作经验要求

数据挖掘技能
关键词解析:
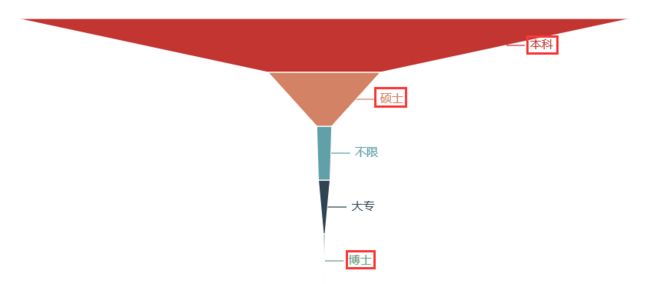
学历:本科(硕士)
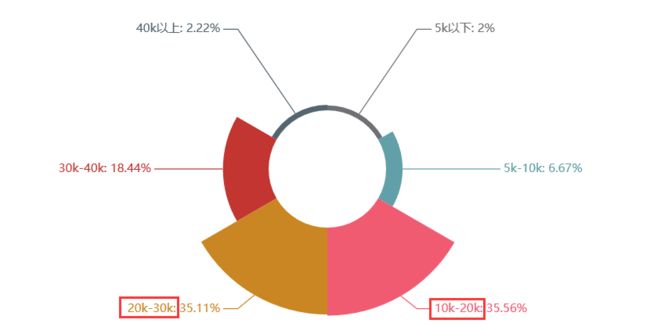
工作月薪:20k-40k
工作经验:3-5年
技能:学历(hhh)、Hadoop、Spark、MapReduce、Scala、Hive、聚类、决策树、GBDT、算法
综合:数据挖掘这个岗位,在学历要求是最高的,虽然还是本科居多,但硕士比例明显增加,还有公司要求博士学历。在专业知识上也有很大要求,得会Linux操作系统基本操作、大数据框架Hadoop、Spark以及数据仓库Hive的使用等计算机相关知识,总体来说难道还是比较大。薪资待遇上特别优厚,基本在20k以上,薪资在30k-40k的比例也有近40%,对工作经验要求还是比较高,大部分的企业要求工作经验要达到3年以上。
![]()
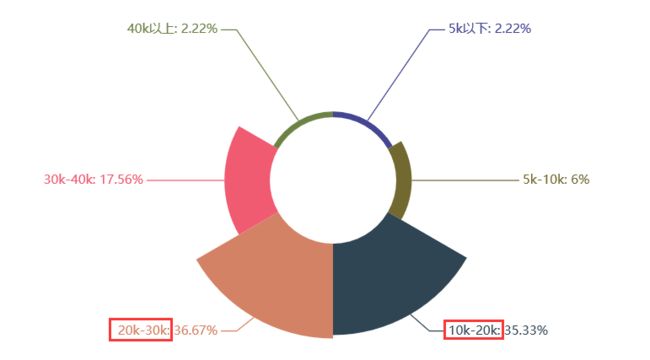
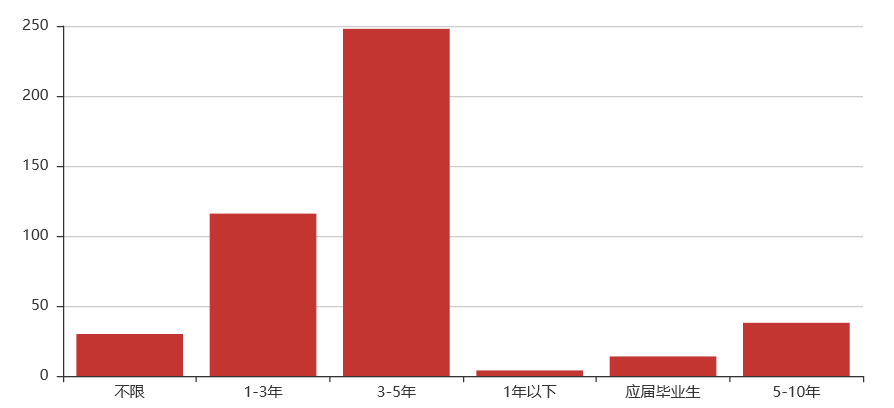
Python全栈开发岗位

学历要求
工作月薪
工作经验要求

全栈开发技能
关键词解析:
学历:本科
工作月薪:10k-30k
工作经验:3-5年
技能:测试、运维、管理、开发、数据结构、算法、接口、虚拟化、前端
综合:全栈开发这个岗位什么都要懂些,什么都要学些,在学历要求上并不太高,本科学历即可,在专业知识上就不用说了,各个方面都得懂,还得理解运用。薪资待遇上也还可以,基本在10k以上,薪资在30k-40k的比例也有近20%。对工作经验要求还是比较高,大部分的企业要求工作经验要达到3年以上。总体来说,就我个人而言会觉得全栈是个吃力多薪水少的岗位。
![]()
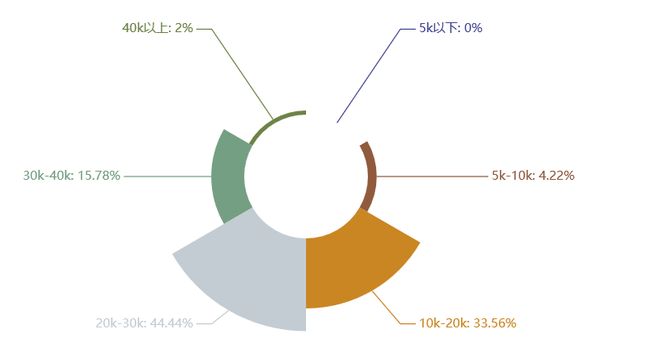
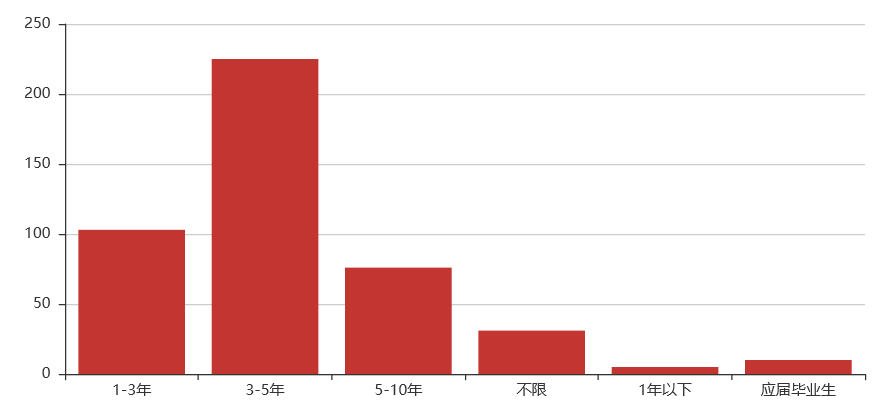
Python运维开发岗位

学历要求
工作月薪
工作经验要求

运维开发技能
关键词解析:
学历:本科
工作月薪:10k-30k
工作经验:3-5年
技能:SVN、Git、Linux、框架、shell编程、mysql,redis,ansible、前端框架
综合:运维开发这个岗位在学历要求上不高,除开占一大半的本科,就是专科了。工作经验上还是有一些要求,大多数要求有3-5年工作经验。从工资上看的话,不高也不低,20k以上也占有62%左右。要学习的东西也比较多,前端、后端、数据库、操作系统等等。
![]()
Python高级开发工程师岗位

学历要求
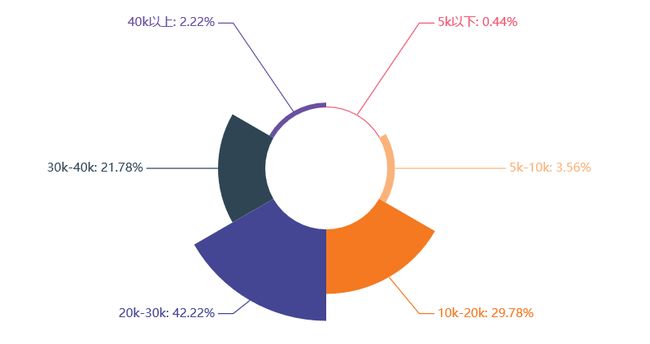
工作月薪
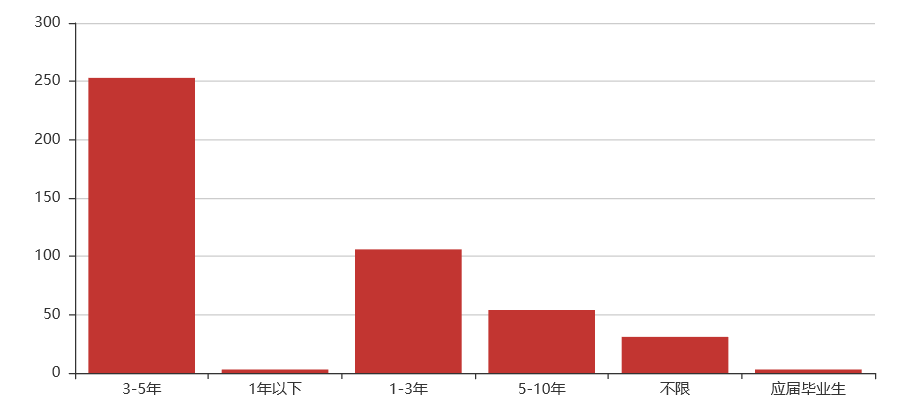
工作经验要求

高级开发工程师技能
关键词解析:
学历:本科
工作月薪:20k左右
工作经验:3-5年
技能:WEB后端、MySQL、MongoDB、Redis、Linux系统(CentOS)、CI/CD 工具、GitHub
综合:高级开发工程师这个岗位在学历要求上与运维开发差不多,薪资也相差不大,22%以上的企业开出了30k以上的薪资,65%左右企业给出20k以上的薪资。当然,对工作经验上还是要求较高,有近一半的企业要求工作经验要达到3年以上。
![]()
Python大数据岗位

学历要求
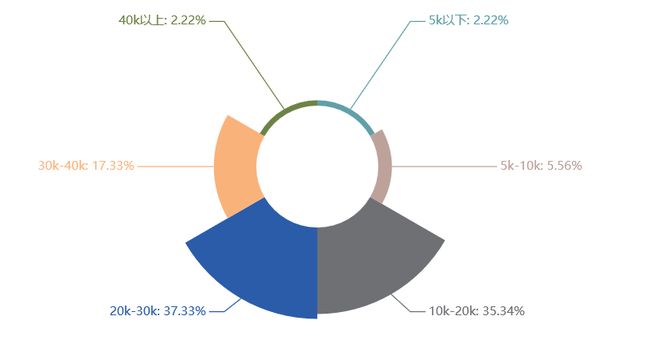
工作月薪
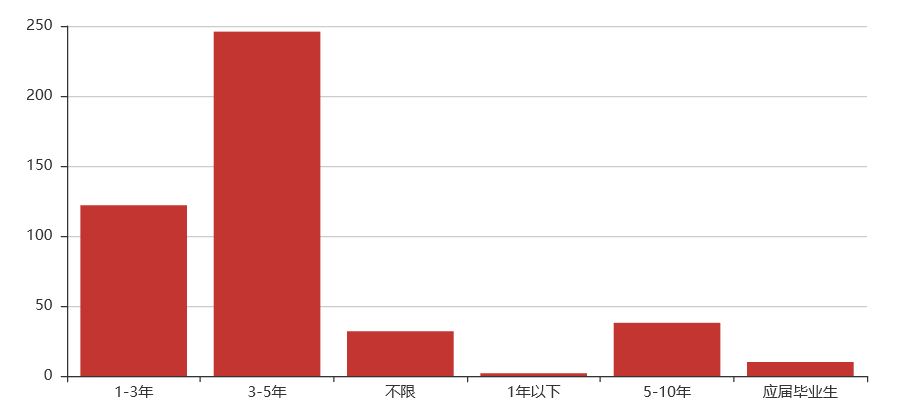
工作经验要求

大数据技能
关键词解析:
学历:本科(硕士也占比很大)
工作月薪:30k以上
工作经验:3-5年
技能:前端开发、 MySQL、Mongo、Redis、Git 、Flask、Celery、Hadoop/HBase/Spark/Hive、Nginx
综合:现在是大数据时代,大数据这个岗位也是相当火热,在学历要求上几乎与运维开发一模一样。当然,可能数据上出现了巧合,本科居多,工作经验上1-5年占据一大半,薪资上也基本上在20k以上,该岗位薪资在20k以上的企业占了55%左右。
![]()
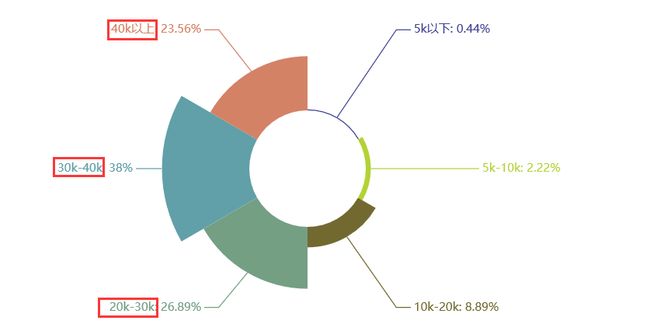
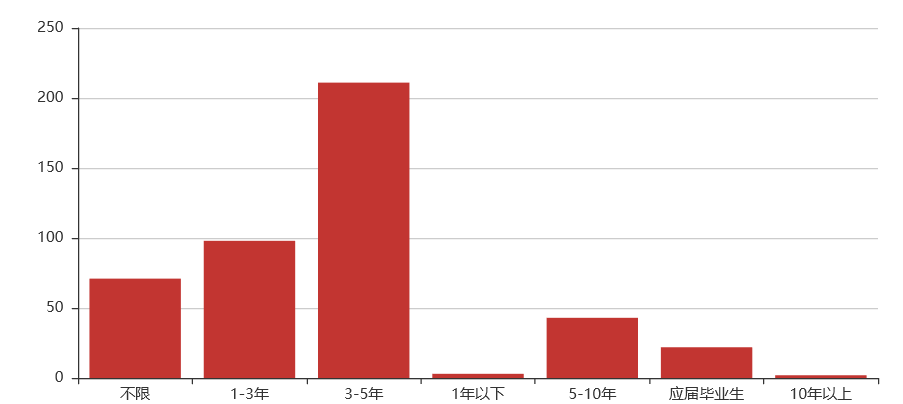
Python机器学习岗位

学历要求
工作月薪
工作经验要求

机器学习技能
关键词解析:
学历:本科(硕士也占比很大)
工作月薪:30k以上
工作经验:3-5年
技能:Machine Learning,Data Mining,Algorithm 研发,算法,Linux,决策树,TF,Spark+MLlib,Cafe
综合:机器学习这个岗位在学历要求上比较严格,虽然看起来是本科居多,但对于刚毕业或毕业不久的同学,如果只是个本科,应聘还是很有难度的。当然机器学习岗位薪资特高,60%在30k以上,近90%在20k以上,97%在10k以上。除开对学历要求比较高外,对工作经验要求也比较高,有近一半的企业要求工作经验要达到3年以上。
![]()
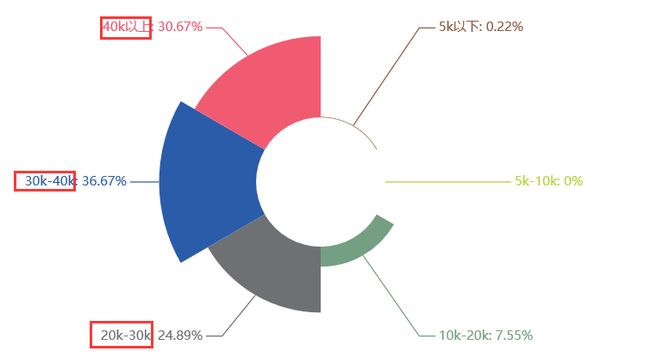
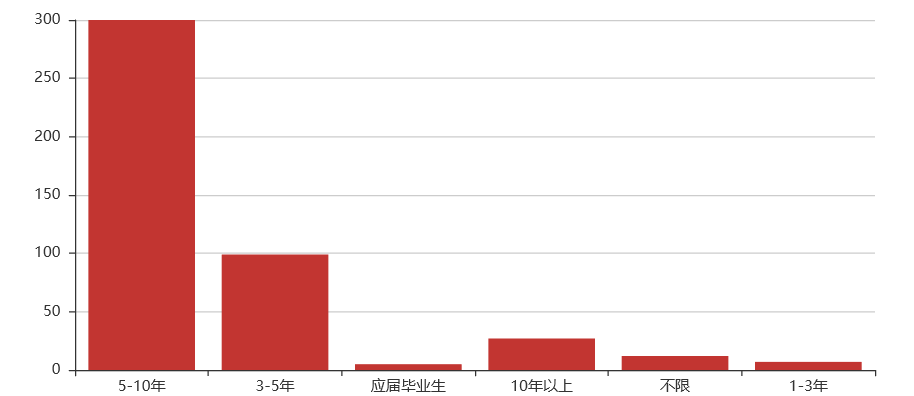
Python架构师岗位

学历要求
工作月薪
工作经验要求

架构师技能
关键词解析:
学历:本科
工作月薪:30k以上
工作经验:5-10年
技能:Flask,Django,MySQL,Redis,MongoDB,Hadoop,Hive,Spark,ElasticSearch,Pandas,Spark/MR,Kafka/rabitmq
综合:架构师这个岗位单从学历上看不出什么来,但在薪资上几乎与机器学习一样,甚至比机器学习还要高,机器学习中月薪40k以上的占23.56%,架构师中月薪40k以上的占30.67%。在学历要求上比机器学习要略低,本科居多,但在工作经验上一半以上的企业要求工作经验在5-10年。在必要技能上也要求特别严格,比之前说过的全栈开发师有过之而无不及。
看着这月薪,我是超级想去了,你呢?
![]()
写在最后
从上文可以看出,Python相关的各个岗位薪资还是不错的,基本上所有岗位在10k以上的占90%,20k以上的也基本都能占60%左右。而且学历上普遍来看,本科学历占70%以上。唯一的是需要工作经验,一般得有个3-5年工作经验,也就是如果24岁本科毕业,27岁就有很大机会拿到月薪20k以上。有没有很心动?
整个系列下来,词云分析虽不完全正确,但大家不难发现,有两个词在每个岗位要求的词云图中都有出现,那就是——经验和熟悉。的确,不论我们做什么,都必须认认真真的去做、去学,在不断的实践中积累经验。
到这里,本系列就结束了,本系列一共爬取了拉钩网10个不同Python相关岗位,每个岗位450条招聘信息,共计4500条。爬取拉钩网其实是个挺简单的事情,只要知道了怎么去分析页面加载即可,获取到数据也不过就是直接返回的json数据,或者正则匹配。我觉得比较有趣也是比较难的是数据清理和可视化分析。后面我会继续学习,也希望大家一起学习,多多交流。
作者:XksA,大三在读的师范技术生,主要学习Python web、数据分析、可视化方面,个人公众号 极简XksA 长期分享学习笔记,学习资料,欢迎交流学习。
声明:本文为作者投稿,版权归对方所有。
“ 征稿啦 ”
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱([email protected])。
————— 推荐阅读 —————




![]()