深度学习 ShuffleNet V2
这是shuffleNet的一个改进版本。论文分析了影响运行速度的几个因素,然后提出了一些指导原则。总的来说,这是一篇很不错的论文,值得学习。
现在很多模型的速度评估都是用FLOPs这个指标,但这个指标用来评价速度是不直接的。因为影响模型速度的因素不仅仅是FLOPs,内存访问操作所消耗的计算(memory access cost,MAC),以及平台因素。
对于MAC这种情况,有很多操作会有非常高的MAC。比如分组卷积,因此我们应该尽量少用分组卷积。另一个情况是,低并行性,如inception系列的多尺度卷积核。
对于平台因素,以GPU的张量分解来说。在一些论文里,提出了FLOPs减少75%的张量分解,理论上应该是加速了很多的。但是在GPU中却慢了很多。论文认为,这是因为CUDNN是针对3*3的卷积进行优化的,我们不能想当然的认为3*3卷积会比1*1卷积慢9倍。我们可以进一步看看不同平台,在不同操作上消耗的计算: 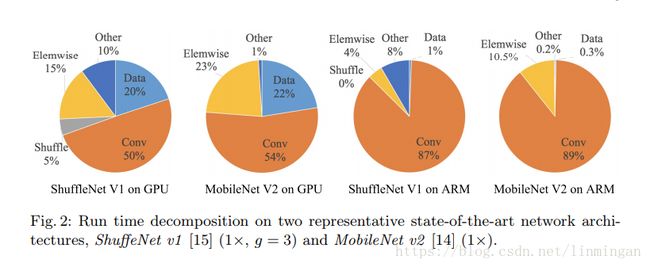
在GPU上,不管是shuffleNet V1还是MobileNet V2卷积和其他的一些消耗MAC的操作所消耗的计算是差不多的。但是在ARM上卷积消耗的计算比MAC消耗的计算更多。
Practical Guidelines for Efficient Network Design
论文提出了一些提高速度的网络结构设计原则,这些原则主要是针对GPU和ARM硬件。另外,论文中的FLOPs只考虑卷积操作,其他的一些操作如data I/O,data shuffle,element-wise 操作(add,relu等)也会用来评估计算速度。接下来介绍一下具体的指导原则:
G1、使用相同的通道数来最小化MAC
现在有很多模型都会使用可分离卷积,在可分离卷积中,1*1卷积的计算量最大。我们研究了不同的输入通道和输出通道对速度的影响。
对于输入通道为c1c1,输出通道为c2c2,特征图大小为wh,1*1卷积的FLOPs,B=hwc1c2B=hwc1c2。为了简单起见,我们假设cache能够容纳所有的特征图和卷积核参数。这样我们可以计算出MAC=hw(c1+c2)+c1c2MAC=hw(c1+c2)+c1c2(访问内存的次数,因为特征图大小为hw,在计算1*1卷积过程中我们需要将将所有的输入特征图和卷积核载入cache一次,这样需要hwc1+c1c2hwc1+c1c2次访存;然后需要将计算结果返回到内存,需要hwc2hwc2次访存。),根据高中学过的不等式原理,可以得到: 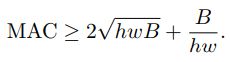
因此在给定FLOPs时MAC有一个下界,MAC等于这个下界的条件为输入通道和输出通道相等。
当然上面的结论是理想情况下的。在现实中很少有cache的大小能够非常大。为了验证上面的结论,论文设计了一个基准网络结构作为实验:由10个block构成,每个block包含两个卷积层,第一个的输入通道为c1c1,输出通道为c2c2,第二个卷积固定。 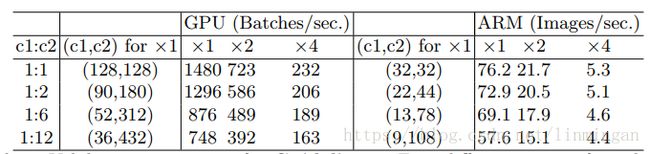
上面的表,给出了实验结果。每一行表示,总的FLOPs相同,但是输入通道数和输出通道数不一样的计算速度。可以发现通道数相等的时候,速度最快。
G2、过多的分组卷积会增加MAC
在shuffleNet V1中大量的使用了分组卷积来降低FLOPs,但事实上却增加了MAC。分组卷积的MAC为: 
其中B=hwc1c2/gB=hwc1c2/g,g为组数。在输入大小c1∗h∗wc1∗h∗w和B固定的情况下,随着g的增加MAC也会增加,见下表。 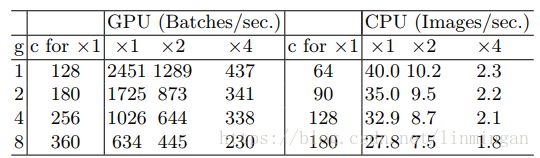
G3、网络分支会降低并行性
在inception系列中,大量使用了“多路”结构作为网络的基础block。很多小的操作集代替大的操作。比如在NASNET-A中的分支操作有13个,而ResNet只有2或者3个。
尽管这样的分支能够提升精度,但是对像GPU这种高并行设备的并行性却很不友好。因为这引入了其他的操作,比如kernel的启动和同步。
论文使用了1到4个1*1的卷积构造一个block,构造方法有串联和并行两种: 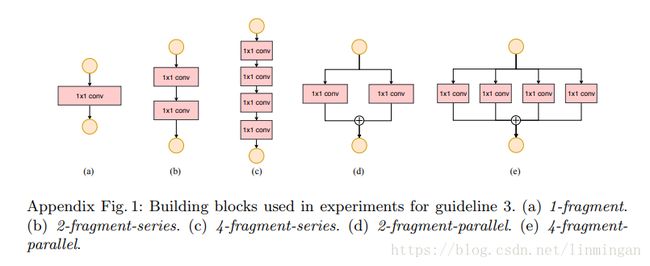
对应的实验结果: 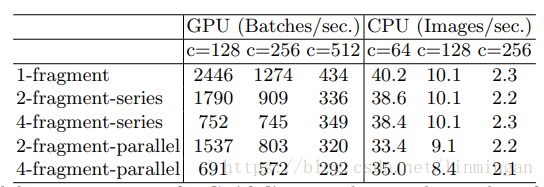
在GPU上,4分支会比1分支慢3倍,但是在ARM中则差不多。
G4、Element-wise操作不可忽视
element-wise操作,比如ReLU,ADD,尽管他们的FLOPs都很小,但是MAC却很大。特别的,depthwise convolution也是一个高MAC/FLOPs率的element-wise操作(这就是为什么depthwise卷积很难达到理论上的加速)。
论文利用ResNet中的block进行实验,对比了有ReLU和shortcut操作,和没有ReLU和shortcut操作的速度。结果显示去掉这两个操作后GPU和ARM上都有20%的速度提升。具体看表: 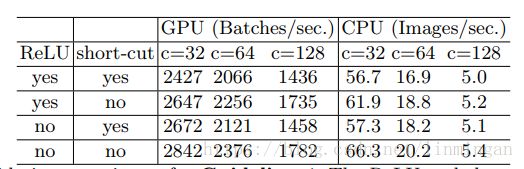
总结与讨论
基于上面的那些指导和经验,论文认为一个高效的网络结构应该包含一下几个要点:
1、使用平衡的卷积,即通道数一样
2、意识到分组卷积所带来的计算消耗
3、减少网络分支
4、减少element-wise操作
在shuffleNet V1中使用了大量的分组卷积,这违反了G2;bottleneck-like的block,这违反了G1。在mobileNet V2中使用了inverted bottleneck,这违反了G1;在稠密的特征图上使用了depthwise卷积和ReLU,这违反了G4。而在自动生成的网络中,其分支数太高,这违反了G3。
ShuffleNet V2
论文为了达到上面的高效网络结构设计原则。使用了一个叫channel split操作,该操作很简单。如下图所示: 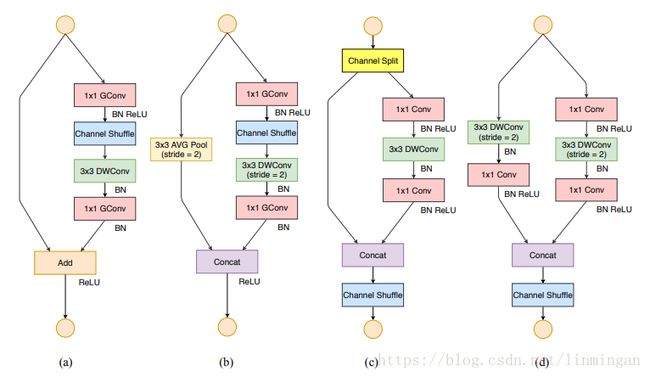
图中的(a)和(b)都是shuffleNet V1里面的block。(c),(d)则为shuffleNet V2的block。在(c)中我们可以看到channel split操作,该操作将输入通道为c的特征图分为个分支,每个分支分别有c−c′c−c′和c′c′(在论文中为c/2)个通道的特征图。在(c)中,利用channel split分出两个分支后(满足G3),左边的分支不做任何操作,右边的分支包含了3个卷积操作,并且其通道数都一样(满足G1)。相比shuffleNet V1两个1*1卷积不再是分组卷积(channe split已经进行了通道分组了),这满足了G2。
两个分支用concat操作进行合并,这样使得block的输入通道数和输出通道数一样,这满足了G1。合并后,紧接这使用了channel shuffle操作。
需要注意的是,这样的block,已经没有了shuffleNet V1中的Add和ReLU操作了。同时depthwise卷积只在一个分支里面。并且concat,channe shuffle以及channel split这三个element-wise操作,可以合并到一个单独的element-wise操作,这满足了G4。
由于(d)中没有了channel split,因此该block的输出通道是输入通道的两倍。
整个shuffleNet V2结构如下: 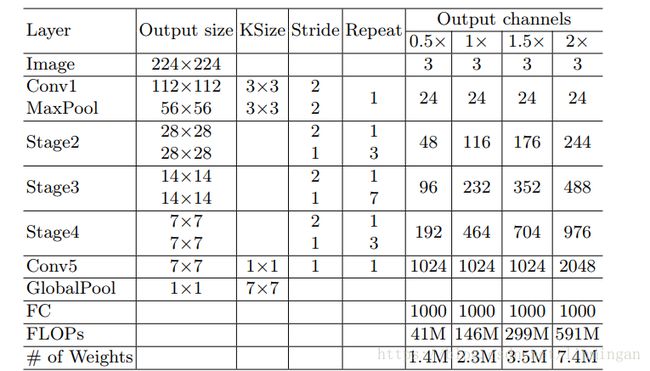
实验结果
论文做了不少实验,并进行了讨论。我们只看看最终的实验比较。从下表,可以看出shuffleNet V2在ARM平台上都是最快的。在GPU上还是mobileNet V1快一些。 