FoveaBox:目标检测新纪元,无Anchor时代来临 | 技术头条

作者 | CV君
转载自我爱计算机视觉(ID:aicvml)
目标检测的任务是“分类”并从图像中“定位”出物体,但长久以来,该领域的工作大多是这样:生成可能包含目标的区域,然后在该区域提取特征并分类。
显然,人眼并不是这样工作的。
人眼可以直接定位出物体,也就是对人眼来说发现目标的过程,定位和分类是一体的。
现代深度学习的方法,代表性的包括二阶段的Faster R-CNN和一阶段的SSD、RetinaNet等,使用在特定尺度图像中预先定义大量的目标框(Anchors)的方法,降低了计算量。但这也带来了超参数增加、人为调参过拟合评测数据集、前后景目标类别不平衡等问题。
但很有意思的是,近半年来,尤其以CornerNet的出现为代表,越来越多的工作开始尝试摆脱Anchors的设计。
CV君相信,无Anchor的目标检测已经悄然成为该领域的重要发展方向。
今天跟大家分享的FoveaBox则是该方向最新的成果(昨天刚刚传到arXiv),针对的是通用目标检测领域,算法方案简单,结果达到state-of-the-art,代码亦将开源,方便后续其他学者跟进,发展空间极大。
深度神经网络可以自己回归出目标包围框,Anchor并非必要,目标检测“可能”要就此进入新纪元了!
下面是论文《FoveaBox: Beyond Anchor-based Object Detector》的作者信息:

作者分类来自清华大学、北京国家信息科技研究中心、字节跳动AI实验室、宾夕法尼亚大学。
感谢~
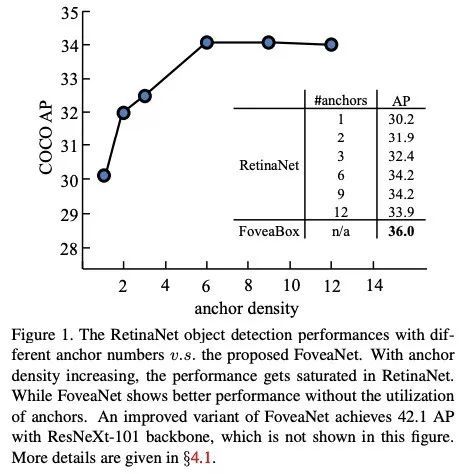
下图为无Anchor的FoveaBox算法与RetinaNet在COCO数据集上的结果比较,RetinaNet通过改变anchors个数,精度有变化,但FoveaBox更胜一筹。
算法思想
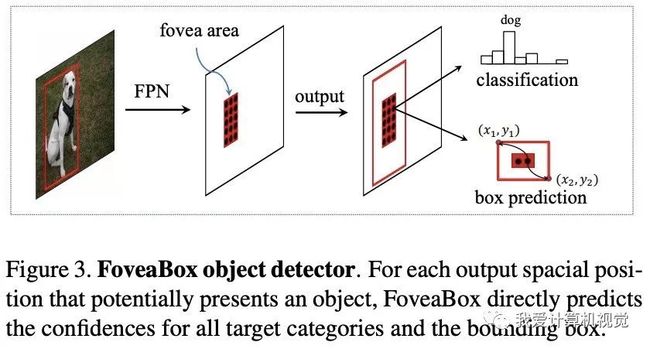
FoveaBox的动机来自人眼的中央凹:视野中心(物体)具有最高的视力。
(物体的位置信息能够从中心反应出来——CV君的理解)
下图展示了FoveaBox目标检测的基本思想,对于可能存在目标的每个输出空间位置,FoveaBox直接预测所有目标类别存在的置信度和边界框。
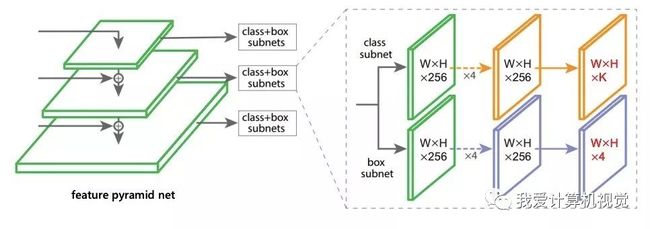
FoveaBox是在RetinaNet目标检测网络基础上做的改进,我们先来看看RetinaNet的网络架构。
如下图,RetinaNet利用了特征金字塔网络检测目标,对于金字塔的每一层,都后接class + box 子网络。最右侧上半部分为class子网络,下半部分为box子网络。

下图是FoveaBox网络的改进,class 子网络计算的是每个输出位置分别存在不同类别目标的置信度,box子网络则是直接计算每个输出位置的与类别无关的目标包围框(左上和右下顶点坐标)。
在论文第三部分从骨干网、训练时目标的尺度分配、训练时目标位置信息内陷、box 预测、网络优化和推断等详细说明了训练和推断的细节。
实验结果
作者首先研究了,FoveaBox算法与RetinaNet在变化anchor密度、目标宽高比后的精度结果,如下图(a)(b),FoveaBox比RetinaNet的最好结果还好。
因为FoveaBox具有自己生成候选目标区域的能力,作者将其与RPN网络相比较,下图(c),发现其生成的目标候选框比RPN的质量更高!


下面表格展示了,FoveaBox与目前两阶段和一阶段state-of-the-art目标检测算法在COCO数据集上检测结果比较,FoveaBox取得了几乎最好的结果,仅三个指标略低于Cascade R-CNN,但作者称许多高级目标检测技巧,FoveaBox还没有使用,后续还有提高的潜力。

下图为FoveaBox与RetinaNet的检测结果示例,可见在宽高比变化较大的目标上,FoveaBox取得了更好的结果。

论文地址:
https://arxiv.org/pdf/1904.03797v1.pdf
作者称代码将开源,地址暂未公布。
(本文为AI科技大本营转载文章,转载请联系原作者)
◆
实习生招募
◆

推荐阅读:
详解爱奇艺ZoomAI视频增强技术的应用 | 公开课笔记
DOTA2人机决战:2:0!OpenAI击败世界冠军OG
Python的10个“秘籍”,这些技术专家全都告诉你了
从头构建恶性肿瘤检测网络 | 100行Python代码理解深度学习关键概念
马云再谈 996:真正的 996 与被剥削无关
漫画:图的 “最短路径” 问题 | 技术头条
从 0 到管理 200 人,这位程序员是如何做到的? | 程序员有话说
4000万假币流入波场, 发生在凌晨的BTT假币攻击事件始末及细节披露
程序员为什么都爱穿冲锋衣?(最全总结)
![]()
❤点击“阅读原文”,查看更多精彩文章。