分布式链路监控追踪分析与实践
转载声明:商业转载请联系作者获得授权,非商业转载请注明出处.原文来自 © 呆萌钟 分布式链路监控追踪系统调研分析
背景
随着互联网架构的扩张,分布式系统变得日趋复杂,越来越多的组件开始走向分布式化,如微服务、消息收发、分布式数据库、分布式缓存、分布式对象存储、跨域调用,这些组件共同构成了繁杂的分布式网络,那现在的问题是一个请求经过了这些服务后其中出现了一个调用失败的问题,只知道有异常,但具体的异常在哪个服务引起的就需要进入每一个服务里面看日志,这样的处理效率是非常低的。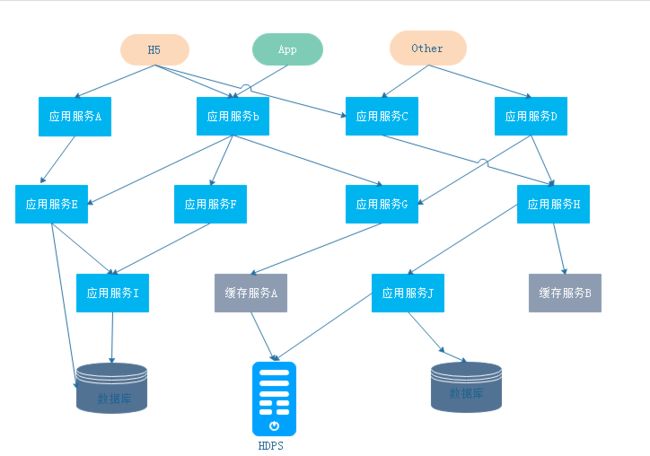
现实中的分布式服务之间的调用链比上图还要复杂,像一张大网,盘根错节。所以,我们急需一种能追踪其调用链的方案,以快速完成问题的定位。
那什么是分布式调用链呢?
分布式调用链其实就是将一次分布式请求还原成调用链路。显式的在后端查看一次分布式请求的调用情况,比如各个节点上的耗时、请求具体打到了哪台机器上、每个服务节点的请求状态等等。
链路追踪系统应该具备的功能
根据前面的分析,我们已经知道追踪分布式调用链是解决上述场景的一个可行方案,那分布式链路追踪应该具备哪些功能才能达到我们的要求呢?
故障快速定位
通过调用链跟踪,一次请求的逻辑轨迹可以用完整清晰的展示出来。开发中可以在业务日志中添加调用链ID,可以通过调用链结合业务日志快速定位错误信息。
各个调用环节的性能分析
在调用链的各个环节分别添加调用时延,可以分析系统的性能瓶颈,进行针对性的优化。通过分析各个环节的平均时延,QPS等信息,可以找到系统的薄弱环节,对一些模块做调整,如数据冗余等。
数据分析
调用链绑定业务后查看具体每条业务数据对应的链路问题,可以得到用户的行为路径,经过了哪些服务器上的哪个服务,汇总分析应用在很多业务场景。
生成服务调用拓扑图
通过可视化分布式系统的模块和他们之间的相互联系来理解系统拓扑。点击某个节点会展示这个模块的详情,比如它当前的状态和请求数量。
分布式调用跟踪系统的设计
我们前面已经说了链路追踪系统需要具备的功能,那从哪些方面考虑去设计它呢?
(1)分布式调用跟踪系统的设计目标
- 低侵入性,应用透明:作为非业务组件,应当尽可能少侵入或者无侵入其他业务系统,对于使用方透明,减少开发人员的负担
- 低损耗:服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径
- 大范围部署,扩展性:作为分布式系统的组件之一,一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性
(2)埋点和生成日志
- 埋点即系统在当前节点的上下文信息,可以分为客户端埋点、服务端埋点,以及客户端和服务端双向型埋点。埋点日志通常要包含以下内容:
- TraceId、RPCId、调用的开始时间,调用类型,协议类型,调用方ip和端口,请求的服务名等信息;
- 调用耗时,调用结果,异常信息,消息报文等;
- 预留可扩展字段,为下一步扩展做准备;
(3)抓取和存储日志
日志的采集和存储有许多开源的工具可以选择,一般来说,会使用离线+实时的方式去存储日志,主要是分布式日志采集的方式。典型的解决方案如Flume结合Kafka等MQ。
(4)分析和统计调用链数据
一条调用链的日志散落在调用经过的各个服务器上,首先需要按 TraceId 汇总日志,然后按照RpcId 对调用链进行顺序整理。用链数据不要求百分之百准确,可以允许中间的部分日志丢失。
(5)计算和展示
汇总得到各个应用节点的调用链日志后,可以针对性的对各个业务线进行分析。需要对具体日志进行整理,进一步储存在HBase或者关系型数据库中,可以进行可视化的查询。
链路追踪Trace模型分析
目前,几乎所有的分布式链路追踪都是来自于谷歌的一篇论文而设计开发而成的,论文名称:Dapper,大规模分布式系统的跟踪系统
Trace调用模型,主要有以下概念:
- Trace:一次完整的分布式调用跟踪链路。
- Span: 追踪服务调基本结构,表示跨服务的一次调用; 多span形成树形结构,组合成一次Trace追踪记录。
- Annotation:在span中的标注点,记录整个span时间段内发生的事件。
- BinaryAnnotation:可以认为是特殊的Annotation,用户自定义事件。
- Annotation类型:保留类型
- Cs CLIENT_SEND,客户端发起请求
- Cr CLIENT_RECIEVE,客户端收到响应
- Sr SERVER_RECIEVE,服务端收到请求
- Ss SERVER_SEND,服务端发送结果
- 用户自定义类型:
- Event 记录普通事件
- Exception 记录异常事件
- Client && Server:对于跨服务的一次调用,请求发起方为client,服务提供方为server
各术语在一次分布式调用中,关系如下图所示:
调用跟踪系统对比
当下互联网环境,大的互联网公司都有自己的分布式跟踪系统,比如Google的Dapper,Twitter的zipkin,淘宝的鹰眼,新浪的Watchman,京东的Hydra等,下面来简单分析。
Google的Drapper(闭源)
Dapper是Google生产环境下的分布式跟踪系统,Dapper有三个设计目标:
- 低消耗:跟踪系统对在线服务的影响应该做到足够小。
- 应用级的透明:对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统显然是侵入性太强的。
- 延展性:Google至少在未来几年的服务和集群的规模,监控系统都应该能完全把控住。
处理分为3个阶段:
①各个服务将span数据写到本机日志上;
②dapper守护进程进行拉取,将数据读到dapper收集器里;
③dapper收集器将结果写到bigtable中,一次跟踪被记录为一行。
大众点评——CAT
架构简单。可以实现一个Trace系统的所有功能。架构如下图所示: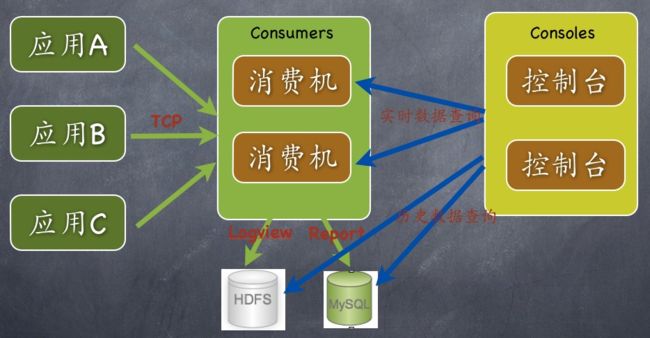
跟踪模型
Transaction是最重要的事件消息类型,适合记录跨越系统边界的程序访问行为,比如远程调用,数据库调用,也适合执行时间较长的业务逻辑监控,记录次数与时间开销。Transaction可嵌套。
跨服务的跟踪功能与点评内部的RPC框架集成,这部分未开源。
客户端接入方式
对于方法调用、sql、url请求等粒度较小的兴趣点,需要业务人员手写代码实现。
日志收集方式
直接向日志收集器发异步请求(有本地内存缓存),一台客户端会连向几个服务端,当一个服务端出问题,数据不会丢失。
当所有服务端都挂掉,消息会存入queue,当queue满了,就丢弃了,没有做数据存储本地等工作。
全量采样,系统繁忙的时候对性能影响较大(可能达到10%的影响)
最后一个稳定版本是2014年1月,之后已经失去维护。
阿里-鹰眼(闭源)
- 埋点和生成日志
- 基于中间件、TraceId/RpcId、异步写、采样
- 抓取和存储日志
- 实时抓日志,实时+离线结合的存储
- 汇总和重组调用链
- 按TraceId汇总、按RpcId重组
- 分析和统计调用链
- 入口标准化、带上下文的调用统计
京东-hydra
与dubbo框架集成。对于服务级别的跟踪统计,现有业务可以无缝接入。对于细粒度的兴趣点,需要业务人员手动添加。架构如下: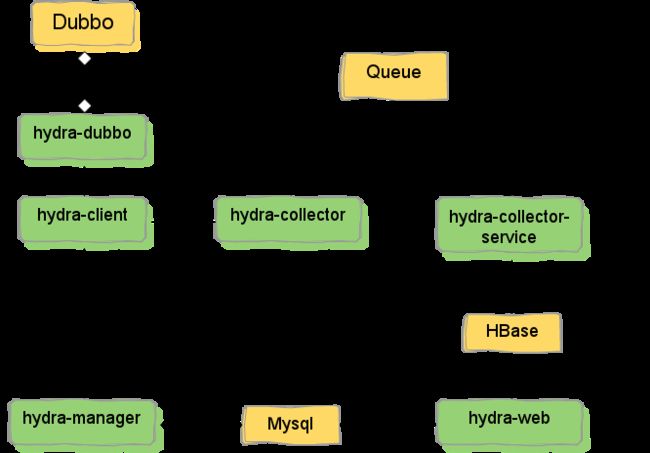
Hydra中跟踪数据模型
Trace: 一次服务调用追踪链路。
Span: 追踪服务调基本结构,多span形成树形结构组合成一次Trace追踪记录。
Annotation: 在span中的标注点,记录整个span时间段内发生的事件。
BinaryAnnotation: 属于Annotation一种类型和普通Annotation区别,这键值对形式标注在span中发生的事件,和一些其他相关的信息。
日志收集方式
与CAT类似。支持自适应采样,规则粗暴简单,对于每秒钟的请求次数进行统计,如果超过100,就按照10%的比率进行采样。
开源项目已于2013年6月停止维护
Twitter—Zipkin
功能、数据跟踪模型与hydra类似。Zipkin本身不开源,开源社区的是另外一套scala实现,依托于finagle这个RPC框架。架构如下:
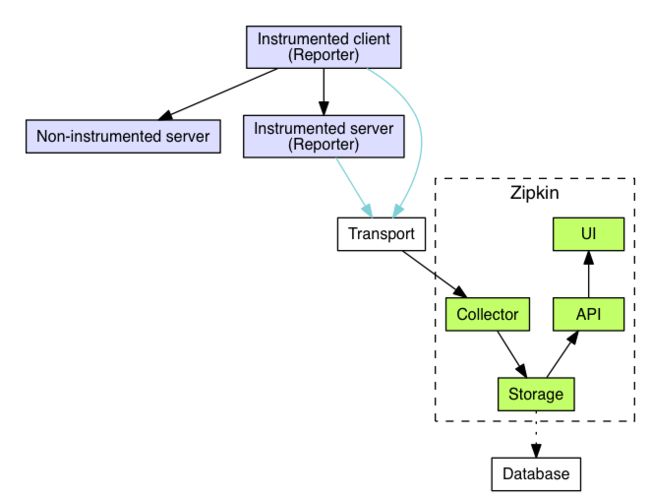
Zipkin与其他Trace系统的不同之处
Zipkin中针对 HttpClient、jax-rs2、jersey/jersey2等HTTP客户端封装了拦截器。可以在较小的代码侵入条件下实现URl请求的拦截、时间统计和日志记录等操作。
日志收集
- Cat是直接将日志发往消费集群;
- hydra是发给日志收集器,日志收集器推到消息队列;
- Zipkin的client将统计日志发往消息队列,日志收集器读取后落地存储;
- Dapper和Eagle eye是记录本地文件,后台进程定期扫描。
Trace系统现状分析
以上几款链路跟踪系统都各自满足了请求链路追踪的功能,但落实到我们自己的生产环境中时,这些Trace系统存在诸多问题:
- Google和alibaba的Trace系统不开源,但现阶段来说阿里是做得最好的,如果用的是阿里的服务器,可考虑直接用阿里的追踪系统以节省开发代价;
- 京东和点评的虽然开源,但是已经多年没有维护,项目依赖的jdk版本以及第三方框架过于陈旧等等,不适合用在生产环境中;
- Twitter的OpenZipkin使用scala开发,而且其实现基于twitter内部的RPC框架finagle,第三方依赖比较多,接入和运维的成本比较高。
如果不是用阿里的服务,我们可以借鉴这些开源实现的思想, 自行开发Trace系统。那是自己从0开始开发还是基于开源方案二次开发? 这里面也要考虑到跨平台,如NET和java环境,尽量减少原系统的侵入性或只需要更改少量的代码即可接入,在这里可以基于zipkin和pinpoint进行二次开发,功能可参考阿里的系统。
参考文章:
https://www.cnblogs.com/zhangs1986/p/8879744.html
https://www.cnblogs.com/yeahwell/p/cat.html