本次以51Job上在东莞地区爬取的以Java为关键词的招聘数据
包括salary company time job_name address字段
当我把招聘网站上的数据爬下来的时候,内心是很开心的
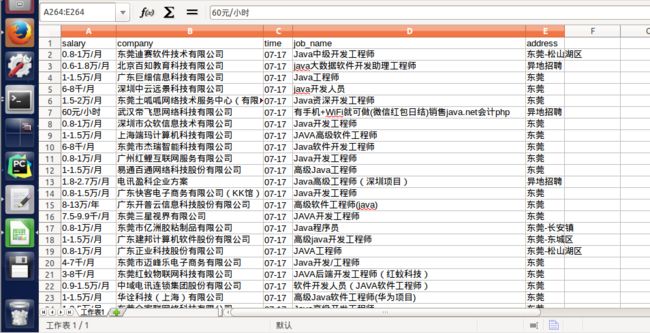
爬下来的原始数据
但是!
What?!
这是什么数据?
而且还不止一条!!!

待清洗数据

待清洗数据
第一次数据清洗
根据上述截图可以发现,脏数据都包含了xx元/小时以及xx元/天。一般我们IT行业很少以小时或者以天计算工资(如果担心清洗了正确的数据,可以后面再做检验)
思路
首先寻找合适的Pandas函数
清理数据相关的函数有
drop()
duplicated()
drop_duplicates()
dropna()
我们并不是要去重, 而是要删掉这部分数据
但是在网络上搜索清洗数据, 我找半天找不到对应的答案, 大部分都是去重, 替换, 去除空数据等等. 我决定跟着自己的思路, 利用drop函数来实现数据清洗
先help一下
drop(self, labels, axis=0, level=None, inplace=False, errors='raise') method of pandas.core.frame.DataFrame instance
Return new object with labels in requested axis removed.
Parameters
----------
labels : single label or list-like
axis : int or axis name
level : int or level name, default None
For MultiIndex
inplace : bool, default False
If True, do operation inplace and return None.
errors : {'ignore', 'raise'}, default 'raise'
If 'ignore', suppress error and existing labels are dropped.
.. versionadded:: 0.16.1
Returns
-------
dropped : type of caller
可以看到, labels是必选参数, 支持单个或者列表
找出脏数据
从drop函数的帮助文档,我们可以想到这样的思路.
先找到对应的脏数据, 再把这些脏数据的index列表找到, 通过drop函数把index对应的所有数据删除
根据上面的思路, 找pandas函数
一开始我找的是query(), where, loc等,但发现不知道怎么模糊查询, 用like报错了
最后查找到
# 这样将得到true or false
df['字段'].str.contains(r'正则表达式')
# 这样才能得到DataFrame
df[df['字段'].str.contains(r'正则表达式')]
# 具体代码
df_dirty = df[df['salary'].str.contains(r'(小时|天)+')]
确认无误并删除
# df.index返回一个index列表
df_clean = df.drop(df_dirty.index)
检验是否删除成功
df.info()
df_dirty.info()
df_clean.info()
RangeIndex: 354 entries, 0 to 353
Data columns (total 5 columns):
salary 354 non-null object
company 354 non-null object
time 354 non-null object
job_name 354 non-null object
address 354 non-null object
dtypes: object(5)
memory usage: 13.9+ KB
Int64Index: 28 entries, 5 to 321
Data columns (total 5 columns):
salary 28 non-null object
company 28 non-null object
time 28 non-null object
job_name 28 non-null object
address 28 non-null object
dtypes: object(5)
memory usage: 1.3+ KB
Int64Index: 326 entries, 0 to 353
Data columns (total 5 columns):
salary 326 non-null object
company 326 non-null object
time 326 non-null object
job_name 326 non-null object
address 326 non-null object
dtypes: object(5)
memory usage: 15.3+ KB
可以看到,脏数据已经被删除
完整代码
import pandas as pd
import numpy as np
df = pd.read_csv(r'PycharmProjects/JobCrawler/job.csv')
df_dirty = df[df['salary'].str.contains(r'(小时|天)+')]
df_clean = df.drop(df_dirty.index)
几行代码就搞定, 再一次感受到Python的简洁, 时间花在思考上更多
第二次数据清洗
这次针对的是job_name字段, 方式和第一次清洗的方式相同

待清洗数据-job_name
可以发现为了躲避清理, 这些招聘信息搞出来的各种名字, 连*号都出现了
# 加上这一行就可以找出job_name字段的脏数据啦
df_dirty = df[df['job_name'].str.contains(r'(\*|在家|试用|体验)+')]
完整代码
import numpy as np
import pandas as pd
df = pd.read_csv(r'PycharmProjects/JobCrawler/job.csv')
df_dirty_salary = df[df['salary'].str.contains(r'(小时|天)+')]
df_dirty_job_name = df[df['job_name'].str.contains(r'(\*|在家|试用|体验|无需|无须|试玩|红包)+')]
df_dirty = pd.concat([df_dirty_salary, df_dirty_job_name])
df.drop(df_dirty.index)
df_clean = df.drop(df_dirty.index)
df_clean
参考文献
使用python进行数据清洗
http://bluewhale.cc/2016-08-21/python-data-cleaning.html
正则表达式 - 语法
http://www.runoob.com/regexp/regexp-syntax.html
Pandas合并数据集
http://blog.csdn.net/u010414589/article/details/51135840