自学python Day2-python爬虫1 - 2018.4.29
前言:没办法。。刚装完python和django就要学爬虫了,打算一边照猫画虎写爬虫,一边回头补python语言。
搜了一圈知乎,觉得有一篇文章比较全面,开整!
学习根据资料:Python3.x爬虫学习资料整理 https://zhuanlan.zhihu.com/p/24358829
同时又要到了公司的爬虫产品的几句技术栈描述,打算结合知乎这篇文章和公司技术栈来写
第一章 用Python 3开发网络爬虫(一)
1.1 代码实现(一): 用Python抓取指定页面
#encoding:UTF-8
import urllib.request
url = "http://www.baidu.com"
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)打开IDLE,将上诉代码复制进去,回车后出错
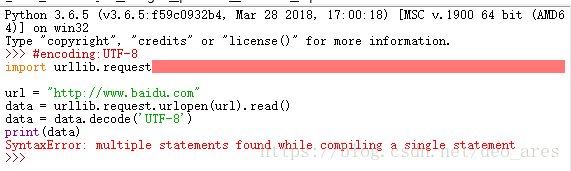
上百度搜索错误代码,发现不能直接复制,
原因:“直接在IDLE中编译,是每行都要回车的。如果是单独的语句,只能是一行一行的编辑。”
解决方法:1. 要CTRL+N新建一个IDLE,复制到新的中,就可以执行了 。2.或者一行一行复制
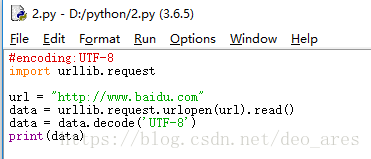
点击F5运行,然后保存文件为2.py,在原有的IDLE中显示出爬去的网页
http.client.HTTPResponse 对象
然后把我们代码中用到的urlopen()函数部分阅读完.
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False)
重点部分是返回值, 这个函数返回一个 http.client.HTTPResponse 对象, 这个对象又有各种方法, 比如我们用到的read()方法, 这些方法都可以根据官方文档的链接链过去. 根据官方文档所写, 我用控制台运行完毕上面这个程序后, 又继续运行如下代码, 以更熟悉这些乱七八糟的方法是干什么的.
(要把帖子中的a = urllib.request.urlopen(full_url) 的full_url 换成网址)
>>> a = urllib.request.urlopen("http://www.baidu.com")
>>> type(a)
>>> a.geturl()
'http://www.baidu.com'
>>> a.info()
>>> a.getcode()
200 P.S.: 把网址的http改成https 会显示如下:
========================== RESTART: D:\python\2.py ==========================
1.2 代码实现(二): 用Python简单处理URL
如果要抓取百度上面搜索关键词为Jecvay Notes的网页, 则代码如下import urllib
import urllib.request
data={}
data['word']='Jecvay Notes'
url_values=urllib.parse.urlencode(data)
url="http://www.baidu.com/s?"
full_url=url+url_values
data=urllib.request.urlopen(full_url).read()
data=data.decode('UTF-8')
print(data)data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 'word=Jecvay+Notes'的字符串, 最后和url合并为full_url, 其余和上面那个最简单的例子相同. 关于urlencode(), 同样通过官方文档学习一下他是干什么的. 通过查看
- urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None)
- urllib.parse.quote_plus(string, safe='', encoding=None, errors=None)
大概知道他是把一个通俗的字符串, 转化为url格式的字符串.
————————————————————————————————————————————————————
第二章 Python 3开发网络爬虫(二): 用到的数据结构简介以及爬虫Ver1.0 alpha
2.1 Python的队列
在爬虫程序中, 用到了广度优先搜索(BFS)算法. 这个算法用到的数据结构就是队列.
Python的List功能已经足够完成队列的功能, 可以用 append() 来向队尾添加元素, 可以用类似数组的方式来获取队首元素, 可以用 pop(0) 来弹出队首元素. 但是List用来完成队列功能其实是低效率的, 因为List在队首使用 pop(0) 和 insert() 都是效率比较低的, Python官方建议使用collection.deque来高效的完成队列任务.
from collections import deque
queue = deque(["Eric", "John", "Michael"])
queue.append("Terry") # Terry 入队
queue.append("Graham") # Graham 入队
queue.popleft() # 队首元素出队
#输出: 'Eric'
queue.popleft() # 队首元素出队
#输出: 'John'
queue # 队列中剩下的元素
#输出: deque(['Michael', 'Terry', 'Graham'])2.2 Python的集合
在爬虫程序中, 为了不重复爬那些已经爬过的网站, 我们需要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先看看集合里面是否已经存在. 如果已经存在, 我们就跳过这个url; 如果不存在, 我们先把url放入集合中, 然后再去爬这个页面.
Python提供了set这种数据结构. set是一种无序的, 不包含重复元素的结构. 一般用来测试是否已经包含了某元素, 或者用来对众多元素们去重. 与数学中的集合论同样, 他支持的运算有交, 并, 差, 对称差.
创建一个set可以用 set() 函数或者花括号 {} . 但是创建一个空集是不能使用一个花括号的, 只能用 set() 函数. 因为一个空的花括号创建的是一个字典数据结构. 以下同样是Python官网提供的示例.
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False
>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}2.3 Python的正则表达式
在爬虫程序中, 爬回来的数据是一个字符串, 字符串的内容是页面的html代码. 我们要从字符串中, 提取出页面提到过的所有url. 这就要求爬虫程序要有简单的字符串处理能力, 而正则表达式可以很轻松的完成这一任务.
- 正则表达式30分钟入门教程
- w3cschool 的Python正则表达式部分
- Python正则表达式指南
2.4 Python网络爬虫Ver 1.0 alpha
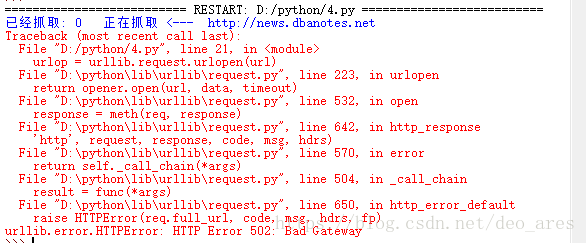
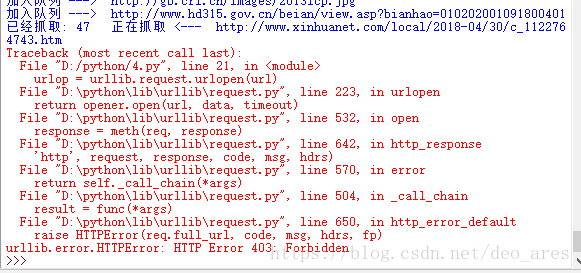
这个爬虫虽然可以勉强运行起来, 但是由于缺乏 异常处理, 只能爬些静态页面, 也不会分辨什么是静态什么是动态, 碰到什么情况应该跳过, 所以工作一会儿就要败下阵来import re #引入为了正则表达式
import urllib.request #引入为了抓取指定url的页面
import urllib #引入为了用urllib.parse库对普通字符串转符合url的字符串
from collections import deque #引入deque函数来创建队列
queue = deque() #创建空队列
visited = set() #创建空集合
url = 'http://news.dbanotes.net' # 入口页面, 可以换成别的
queue.append(url) #在队列理加入url,防止第一次循环时队首元素为空
cnt = 0 #计数
while queue: #开始循环
url = queue.popleft() # 队首元素出队 #即第一个元素从队列中取出来,队列后续元素向前补位
visited |= {url} # 标记为已访问 #类似于visited.add(url),类似于a += b
print('已经抓取: ' + str(cnt) + ' 正在抓取 <--- ' + url)
cnt += 1 #计数+1
urlop = urllib.request.urlopen(url)
if 'html' not in urlop.getheader('Content-Type'):
continue #continue跳出本次循环
# 避免程序异常中止, 用try..catch处理异常
try:a
data = urlop.read().decode('utf-8')
except:
continue #如果有异常,则跳出本次循环,进行下次循环
# 正则表达式提取页面中所有队列, 并判断是否已经访问过, 然后加入待爬队列
linkre = re.compile('href="(.+?)"')
for x in linkre.findall(data):
if 'http' in x and x not in visited:
queue.append(x)
print('加入队列 ---> ' + x)这个版本的爬虫使用的正则表达式是
'href="(.+?)"'所以会把那些.ico或者.jpg的链接都爬下来. 这样read()了之后碰上decode('utf-8')就要抛出异常. 因此我们用getheader()函数来获取抓取到的文件类型, 是html再继续分析其中的链接.
if 'html' not in urlop.getheader('Content-Type'):
continue但是即使是这样, 依然有些网站运行decode()会异常. 因此我们把decode()函数用try..catch语句包围住, 这样他就不会导致程序中止.
运行后接入过下