1, 需求分析
- 数据源/数据格式 : 某医院的hbase表–> 映射hive 外表–> 使用hive函数分析数据
person_name oper_code oper_time oper_group_num
person1 1 2018/9/3 12:23 person1_0001
person1 2 2018/9/3 12:30 person1_0001
NULL 3 NULL person1_0001
person1 4 2018/9/3 12:50 person1_0001
person2 1 2018/9/4 12:03 person2_0001
person2 2 NULL person2_0001
NULL 3 2018/9/4 12:30 person2_0001
person2 4 2018/9/4 12:55 person2_0001
- 业务需求: 使用hive分析函数,按月统计如下指标
- 特殊说明:oper_code=1的时间oper_time一定非空, 若oper_code!=1的时间oper_time为空则月份和oper_code=1的月份时间相同
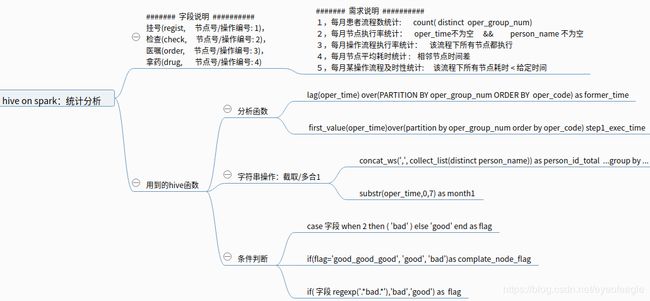
2, 代码实现
1, 每月患者流程数统计
//1, spark配置
val conf=new SparkConf()
conf.setAppName("loop_count")//.setMaster("local[*]")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val hiveContext = new HiveContext(sc)
//2, hiveql语句
val hbase_table_name = "patient_info"
val hive_tmp_table_name="spark_hive1" + "_" + hbase_table_name
val sql =
" select hbase_table_name,month," +
" count(distinct(oper_group_num))as group_count, "+
" count(rowkey) as node_count from ( " +
" select hbase_table_name, " +
" case when( month1 is null or month1 ='NULL' or month1='' ) then ( substr(step1_exec_time,0,7) ) else month1 end as month, " +
" rowkey,oper_group_num from (" +
" select '" + hbase_table_name + "' as hbase_table_name," +
" oper_group_num ," +
" rowkey ," +
" oper_code, " +
" ROW_NUMBER() OVER(PARTITION BY oper_group_num ORDER BY oper_code ) AS row_number," +
" oper_time, " +
" first_value(oper_time)over(partition by oper_group_num order by oper_code) step1_exec_time, " +
" substr(oper_time,0,7) as month1 " +
" from " + hive_tmp_table_name +
" )tmp " +
" )tmp2 group by hbase_table_name,month"
//3, 执行hive查询
println("\r\nsql===>" + sql)
val df = hiveContext.sql(sql)
df.show()
//4, 数据保存
val prop = new Properties()
val in = Thread.currentThread().getContextClassLoader().getResourceAsStream("spark_hive.properties") //配置关系型数据:连接参数
prop.load(in)
println(prop)
val jdbc_out_tablename="spark_group_count"
df.write.mode(SaveMode.Overwrite).jdbc(prop.getProperty("url"), jdbc_out_tablename, prop)
2, 每月节点执行率统计
//1, spark配置
//2, hiveql语句
val hbase_table_name = "patient_info"
val sql =
" select hbase_table_name,month,oper_code,complate_node_flag, count(complate_node_flag) as flag_count ," +
" concat_ws(',', collect_list(distinct person_name)) as person_name_total from (" +
" select hbase_table_name ,month, person_name, oper_code, " +
" if(flag='good_good_good', 'good', 'bad')as complate_node_flag from (" +
" select *, concat( flag1,'_',flag2,'_',flag3) as flag from (" +
"select *, " +
" case when( month1 is NULL or month1 ='NULL' or month1='' ) then ( substr(step1_exec_time,0,7) ) else month1 end as month, " +
" case person_name when 'NULL' then ( 'bad' ) when '' then ('bad') else 'good' end as flag1, " +
" case oper_time when 'NULL' then ( 'bad' ) when '' then ('bad') else 'good' end as flag2 " +
" from (" +
" select '" + hbase_table_name + "' as hbase_table_name," +
" person_name," +
" oper_time ," +
" oper_group_num ," +
" oper_code, " +
" ROW_NUMBER() OVER(PARTITION BY oper_group_num ORDER BY oper_code ) AS row_number," +
" oper_time, " +
" first_value(oper_time)over(partition by oper_group_num order by oper_code) step1_exec_time, " +
" substr(oper_time,0,7) as month1 " +
" from " + hive_tmp_table_name + " )tmp " +
" )tmp2" +
" )tmp3" +
")tmp4 group by hbase_table_name,month,oper_code,complate_node_flag "
//3, 执行hive查询
println("\r\nsql===>" + sql)
val df = hiveContext.sql(sql)
df.show()
//4, 数据保存
3, 每月操作流程执行率统计
//1, spark配置
//2, hiveql语句
val hbase_table_name = "patient_info"
val sql =
" select hbase_table_name ,month,complate_loop_flag,count(oper_group_num) as flag_count," +
" concat_ws(',', collect_list(distinct person_name_list)) as person_name_total from (" + //tmp6
" select * ,if( complate_flag_loop regexp('.*bad.*'),'bad','good') as complate_loop_flag from ( " + //tmp5
" select hbase_table_name ,month,oper_group_num," +
" concat_ws('_', collect_list(complate_flag)) as complate_flag_loop," +
" concat_ws(',', collect_list(distinct person_name)) as person_name_list from (" + //tmp4
" select hbase_table_name, month, person_name, oper_code, oper_group_num, " +
" if(flag='good_good_good', 'good', 'bad')as complate_flag from (" + //tmp3
" select *, concat( flag1,'_',flag2) as flag from (" +
"select *, " +
" case when( month1 is NULL or month1 ='NULL' or month1='' ) then ( substr(step1_exec_time,0,7) ) else month1 end as month, " +
" case person_name when 'NULL' then ( 'bad' ) when '' then ('bad') else 'good' end as flag1, " +
" case oper_time when 'NULL' then ( 'bad' ) when '' then ('bad') else 'good' end as flag2 from (" +
" select '" + hbase_table_name + "' as hbase_table_name," +
" oper_group_num ," +
" oper_code, " +
" person_name," +
" ROW_NUMBER() OVER(PARTITION BY oper_group_num ORDER BY oper_code ) AS row_number," +
" oper_time, " +
" first_value(oper_time)over(partition by oper_group_num order by oper_code) step1_exec_time, " +
" substr(oper_time,0,7) as month1 " +
" from " + hive_tmp_table_name +
" )tmp " +
" )tmp2" +
" )tmp3" +
" )tmp4 group by hbase_table_name ,month,oper_group_num " +
" )tmp5" +
" )tmp6 group by hbase_table_name ,month,complate_loop_flag"
//3, 执行hive查询
println("\r\nsql===>" + sql)
val df = hiveContext.sql(sql)
df.show()
//4, 数据保存
4, 每月节点平均耗时统计
//1, spark配置
//2, hiveql语句
val hbase_table_name = "patient_info"
val sql =
" select hbase_table_name, month, oper_code ," +
" sum(node_time_diff) as sum_time_diff," +
" count(node_time_diff) as node_count," +
" concat_ws(',', collect_list(distinct person_name)) as person_name_total from ( " +
" select *, case when node_time_diff1 is NULL then 0 else node_time_diff1 end as node_time_diff from ("+
" select *, case when( month1 is NULL or month1 ='NULL' or month1='' ) then ( substr(step1_exec_time,0,7) ) else month1 end as month ," +
" (unix_timestamp(oper_time,'yyyy-MM-dd HH:mm:ss')- unix_timestamp(former_time,'yyyy-MM-dd HH:mm:ss')) as node_time_diff1 " +
" from (" +
" select '" + hbase_table_name + "' as hbase_table_name," +
" substr(oper_time,0,7)as month1," +
" first_value(oper_time)over(partition by oper_group_num order by oper_code) step1_exec_time, " +
" person_name, " +
" oper_group_num ," +
" oper_code, " +
" lag(oper_code) over(PARTITION BY oper_group_num ORDER BY oper_code) as former_step_code, " +
" ROW_NUMBER() OVER(PARTITION BY oper_group_num ORDER BY oper_code ) AS row_number," +
" oper_time ," +
" lag(oper_time) over(PARTITION BY oper_group_num ORDER BY oper_code) as former_time " +
" from " + hive_tmp_table_name +
" ) tmp where STEPSTATUSNAME='已执行' and (oper_code - former_step_code)=1 "+ //STEPSTATUSNAME='已执行' and
" )tmp2 "+
" )tmp3 group by hbase_table_name, month, oper_code "
//3, 执行hive查询
println("\r\nsql===>" + sql)
val df = hiveContext.sql(sql)
df.show()
//4, 数据保存
5, 每月某流程及时性统计
//1, 获取任务参数:Array(("patient_info1",2,4,100),("patient_info2",4,6,100))
val time_param_df = JdbcUtil.get_ruleparam(hiveContext)
val rowArr=time_param_df.collect.filter(row=>{
val hbase_table = row.getAs[String]("hbase_table_name")
val rule_code = row.getAs[String]("rule_code")
hbase_table_name== hbase_table && rule_code=="node_timediff_good"
})
val node_tmp_tablenameArr = rowArr.map(row=>{
val node_start = row.getAs[Int]("step_start_code")
val node_end = row.getAs[Int]("step_end_code")
node_end+"_"+node_start
})
//2, 遍历所有业务表
rowArr.foreach(row=>{
val node_start = row.getAs[Int]("step_start_code")
val node_end = row.getAs[Int]("step_end_code")
val time_diff = row.getAs[Int]("time_param")//单位:秒
val node_tmp_tablename=node_end+"_"+node_start
println("time-param-df: ----------> ",row)
//a, 一个节点过滤条件===> 一个临时表
" select hbase_table_name,month,person_name,oper_group_num," +
" concat(oper_code,'_', former_step_code) step, node_time_diff," +
" if( node_time_diff >=0 and node_time_diff<=" +time_diff +",'good','bad' ) as complete_flag "+
" from (" +
" select *, case when( month1 is NULL or month1 ='NULL' or month1='' ) then ( substr(step1_exec_time,0,7) ) else month1 end as month ," +
" (unix_timestamp(oper_time,'yyyy-MM-dd HH:mm:ss')- unix_timestamp(former_time,'yyyy-MM-dd HH:mm:ss')) as node_time_diff from (" +
" select '" + hbase_table_name + "' as hbase_table_name," +
" substr(oper_time,0,7)as month1, " +
" first_value(oper_time)over(partition by oper_group_num order by oper_code) step1_exec_time, " +
" person_name, " +
" oper_group_num ," +
" oper_code, " +
" lag(oper_code,"+ (node_end- node_start)+") over(PARTITION BY oper_group_num ORDER BY oper_code) as former_step_code, " +
" ROW_NUMBER() OVER(PARTITION BY oper_group_num ORDER BY oper_code ) AS row_number," +
" oper_time ," +
" lag(oper_time,"+ (node_end- node_start)+") over(PARTITION BY oper_group_num ORDER BY oper_code) as former_time " +
" from " + hive_tmp_table_name +
" ) tmp where oper_code=" + node_end + " and former_step_code= " + node_start +
" )tmp2 "
//b, 创建多个小表: 节点临时表
println("\r\nsql===>"+sql)
val df = hiveContext.sql(sql)
df.registerTempTable(node_tmp_tablename)
df.show()
// +--------------------+-------+---------------+------------+----+-------------+
// | hbase_table_name| month| person_name|oper_group_num|step|complete_flag|
// +--------------------+-------+---------------+------------+----+-------------+
// |patient_info...|2018-01| person1| person1_0001| 3_2| good|
// |patient_info...|2018-01| person1| person1_0001| 3_2| bad|
// |patient_info...|2018-01| person1| person1_0001| 3_2| bad|
// |patient_info...|2018-01| person2| person2_0001| 3_2| good|
//c, 取消缓存
df.unpersist()
})//遍历:多节点参数
//3, 多表查询: 节点临时表
val sql_all = SqlUtil.getsql(node_tmp_tablenameArr) //select t1.*, t2.step, t2.complete_flag .... inner join t2 on.....
val df1 = hiveContext.sql(sql_all)
println(" -------------- tmp1 ------------")
df1.show()
df1.registerTempTable("tmp1")
hiveContext.sql("select hbase_table_name, month, person_name, oper_group_num, concat(*) as flag1 from tmp1").registerTempTable("tmp2")
////////////
val df3 = hiveContext.sql("select 'tmp3', hbase_table_name, month, person_name, oper_group_num," +
" if( flag1 regexp('.*bad.*'),'bad','good') as flag from tmp2")
df3.show()
df3.registerTempTable("tmp3")
//+----+--------------------+-------+---------------+------------+----+
// | _c0| hbase_table_name| month| person_name|oper_group_num|flag|
// +----+--------------------+-------+---------------+------------+----+
// |tmp3|patient_info...|2018-01| person1| person1_0001|good|
//取消缓存
df1.unpersist()
df3.unpersist()
//4, 聚合,保存结果到sqlserver
val df=hiveContext.sql("select hbase_table_name, month, flag, " +
" count(oper_group_num) as flag_count," +
" concat_ws(',', collect_list(distinct person_name)) as person_name_total " +
" from tmp3 where flag='good' " +
" group by hbase_table_name, month, flag")
df.show()