【caffe源码研究】第三章:源码篇(3) :工厂模式
caffe里面无论solver还是layer都使用了工厂模式。
工厂模式
工厂模式的介绍 工厂方法模式(Factory Method Pattern)
工厂模式的UML的类图 :
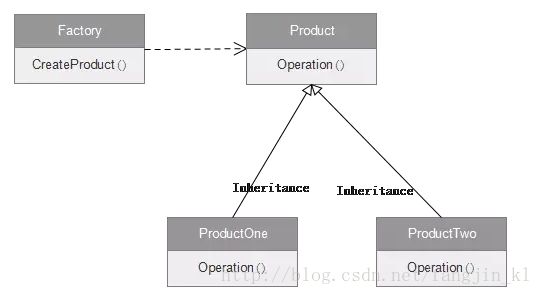
这里就用solver的工厂模式进行说明,具体代码在solver_factory.hpp中。
SolverRegistry
solver_factory.hpp中定义了一个SolverRegistry类。
template <typename Dtype> //模板类
class SolverRegistry {
public://定义了两个成员变量
//名为Creator的函数指针,参数为SolverParameter&类型的引用,返回值为一个Solver类型的指针
typedef Solver* (*Creator)(const SolverParameter&);
//将一个键值对为“字符串-函数指针”的容器命名为CreatorRegistry,将字符串和函数行成映射
//类似于typedef char* pchar的用法。
typedef std::map<string, Creator> CreatorRegistry;
//静态成员方法Registry(),为一个CreatorRegistry类型的变量分配内存,返回变量的指针
static CreatorRegistry& Registry() {
//定义指针变量g_registry,只想一块由CreatorRegistry()分配的内存
//建立CreatorRegistry对象
static CreatorRegistry* g_registry_ = new CreatorRegistry();
//返回变量的引用,所有的registry 只是引用了这个全局变量。
return *g_registry_;
}
// Adds a creator.向CreatorRegistry中增加键值对
static void AddCreator(const string& type, Creator creator) {
//生成一个键值对容器
CreatorRegistry& registry = Registry();
CHECK_EQ(registry.count(type), 0)
<< "Solver type " << type << " already registered.";
//根据type添加一个Creator
registry[type] = creator;
}
// Get a solver using a SolverParameter.根据参数param生成一个求解器Solver,返回指针
static Solver* CreateSolver(const SolverParameter& param) {
const string& type = param.type();
CreatorRegistry& registry = Registry();
CHECK_EQ(registry.count(type), 1) << "Unknown solver type: " << type
<< " (known types: " << SolverTypeListString() << ")";
//这里尤其值得注意,registry[type]代表一个函数指针,通过参数param,执行函数,返回函数执行的结果,应该是生成一个Solver
return registry[type](param);
}
//向一个vector变量中迭代插入求解器的名字,也就是type
static vector<string> SolverTypeList() {
CreatorRegistry& registry = Registry();
vector<string> solver_types;
for (typename CreatorRegistry::iterator iter = registry.begin();
iter != registry.end(); ++iter) {
solver_types.push_back(iter->first);
}
return solver_types;
}
private:
// Solver registry should never be instantiated - everything is done with its
// static variables.
// 将类的构造函数放在private里,可以避免被实例化。
SolverRegistry() {}
//作用是输出所有的求解器类型
static string SolverTypeListString() {
vector<string> solver_types = SolverTypeList();
string solver_types_str;
for (vector<string>::iterator iter = solver_types.begin();
iter != solver_types.end(); ++iter) {
if (iter != solver_types.begin()) {
solver_types_str += ", ";
}
solver_types_str += *iter;
}
return solver_types_str;
}
}; SolverRegisterer
然后定义了一个新类SolverRegisterer 。
template Dtype>
class SolverRegisterer {
public:
SolverRegisterer(const string& type,
Solver<Dtype>* (*creator)(const SolverParameter&)) {
// LOG(INFO) << "Registering solver type: " << type;
SolverRegistry<Dtype>::AddCreator(type, creator);
}
}; 这个类的构造函数中会运行AddCreator方法。
宏定义
然后是几个宏定义
// define 里的 ##是一个连接符号,用于把参数连在一起
// #是“字符串化”的意思。出现在宏定义中的#是把跟在后面的参数转换成一个字符串
// 给不同类型的type定义不同的creator
#define REGISTER_SOLVER_CREATOR(type, creator) \
static SolverRegisterer g_creator_f_##type(#type, creator<float>); \
static SolverRegisterer g_creator_d_##type(#type, creator<double>) \
#define REGISTER_SOLVER_CLASS(type) \
template \
Solver* Creator_##type##Solver( \
const SolverParameter& param) \
{ \
return new type##Solver<Dtype>(param); \
} \
REGISTER_SOLVER_CREATOR(type, Creator_##type##Solver) 举个例子说明就好懂了。例如我们定义一个Solver的子类SGDSolver,在这个类的最后加上
INSTANTIATE_CLASS(SGDSolver);
REGISTER_SOLVER_CLASS(SGD);其中INSTANTIATE_CLASS(SGDSolver);
// Instantiate a class with float and double specifications.
#define INSTANTIATE_CLASS(classname) \
char gInstantiationGuard##classname; \
template class classname<float>; \
template class classname<double>相当于声明了
char gInstantiationGuardSGDSolver;
template class SGDSolver<float>;
template class SGDSolver<double>;而REGISTER_SOLVER_CLASS(SGD);展开就是
template <typename Dtype>
Solver* Creator_SGDSolver(const SolverParameter& param){
return new SGDSolver(param);
}
static SolverRegisterer<float> g_creator_f_SGD("SGD", Creator_SGDSolver<float>);
static SolverRegisterer<double> g_creator_d_SGD("SGD", Creator_SGDSolver<double>); 也就是声明了一个Creator_SGDSolver函数,在函数中新建一个SGDSolver类,并且返回。同时声明了两个SolverRegisterer类。执行构造函数,会运行SolverRegistry方法。
以g_creator_f_SGD("SGD", Creator_SGDSolver为例,执行AddCreator(”SGD", Creator_SGDSolver,则会将在std::map中存储
registry["SGD"] = Creator_SGDSolver<float>;当然,本质是存储在静态变量g_registry_中。
运行过程
下面看看工厂模式如何工作。
首先,定义了一个基类Solver,关于Solver本小节不介绍。其他的Solver都是继承自这个基类。在主函数的入口里, 声明一个Solver类的指针solver,而指针的构造函数是调用了CreateSolver方法。
shared_ptr<caffe::SolverCreateSolver会根据传入的参数solver_param的一个变量type,来return registry[type](param);
假设这个type值为SGD,那么函数返回registry[SGD](param)而registry是指向了g_registry_,根据前面的分析,g_registry_["SGD"]返回Creator_SGDSolver,然后参数是param。也就是运行函数Creator_SGDSolver,而这个函数上面也有提到,返回return new SGDSolver因此最终返回了一个SGDSolver对象.
layer的工厂模式
layer的工厂模式与solver基本一致,在代码layer_factory.hpp中,下面讲一下有区别的地方。主要区别在于多了一个layer_factory.cpp,而这个代码中会针对GPU和CPU的实现分类返回。
简单的对比,在solver类中,每一个子类的最后写上
INSTANTIATE_CLASS(SGDSolver);
REGISTER_SOLVER_CLASS(SGD);而对于layer,部分层的实现也是如此,也有部分层的实现有所区别。例如卷积层,针对是否使用GPU,是否使用CUDNN库,返回不同的ConvolutionLayer对象。
// Get convolution layer according to engine.
template <typename Dtype>
shared_ptr > GetConvolutionLayer(
const LayerParameter& param) {
ConvolutionParameter conv_param = param.convolution_param();
ConvolutionParameter_Engine engine = conv_param.engine();
#ifdef USE_CUDNN
bool use_dilation = false;
for (int i = 0; i < conv_param.dilation_size(); ++i) {
if (conv_param.dilation(i) > 1) {
use_dilation = true;
}
}
#endif
if (engine == ConvolutionParameter_Engine_DEFAULT) {
engine = ConvolutionParameter_Engine_CAFFE;
#ifdef USE_CUDNN
if (!use_dilation) {
engine = ConvolutionParameter_Engine_CUDNN;
}
#endif
}
if (engine == ConvolutionParameter_Engine_CAFFE) {
return shared_ptr >(new ConvolutionLayer(param));
#ifdef USE_CUDNN
} else if (engine == ConvolutionParameter_Engine_CUDNN) {
if (use_dilation) {
LOG(FATAL) << "CuDNN doesn't support the dilated convolution at Layer "
<< param.name();
}
return shared_ptr >(new CuDNNConvolutionLayer(param));
#endif
} else {
LOG(FATAL) << "Layer " << param.name() << " has unknown engine.";
}
}
REGISTER_LAYER_CREATOR(Convolution, GetConvolutionLayer);