详解Tensorflow数据读取Dataset与Iterator
目录
tf.data的结构介绍(Dataset 与 Iterator)
Dataset的使用详解
(1)Dataset的属性
(2)从内存中读取数据
(3)从文件中读取数据
(4)单元素及多元素处理(变换)
(5)数据集处理
(6)模型训练的相关数据设置
Iterator的使用详解
(1)单次迭代
(2)可初始化的迭代
(3)可重新初始化的迭代
(4)可馈送的迭代
参考
tf.data的结构介绍(Dataset 与 Iterator)
Tensorflow 1.8提供了tf.data API对数据进行处理和访问,其具有大量处理数据的实用方法,且语法更加简洁易懂。同时,tf.data方法可与eager Execution 及 tf.Kerase联合使用,可方便的进行模型建立及训练,非常方便。
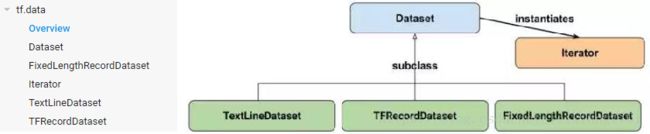
tf.data API的结构如下图所示,其中左侧为tensorflow官方文档中类目录,右侧为Dataset、FixedLengthRecordDataset、Iterator、TextLineDataset以及TFRecordDataset之间的关系视图。TextLineDataset(处理文本)、TFRecordDataset(处理存储于硬盘的大量数据,不适合进行内存读取)、FixedLengthRecordDataset(二进制数据的处理)继承自Dataset,这几个类的方法大体一致,主要包括数据读取、元素变换、过滤,数据集拼接、交叉等。Iterator是Dataset中迭代方法的实例化,主要对数据进行访问,包括四种迭代方法,单次、可初始化、可重新初始化、可馈送等,可实现对数据集中元素的快速迭代,供模型训练使用。因此,只要掌握Dataset以及Iterator的方法,即可清楚tensorflow的数据读取方法。
Dataset的使用详解
一个数据集包含多个元素,每个元素的结构都相同。一个元素包含一个或多个 tf.Tensor 对象,这些对象称为组件。每个组件都有一个 tf.DType,表示张量中元素的类型;以及一个 tf.TensorShape,表示每个元素(可能部分指定)的静态形状。
(1)Dataset的属性
Dataset的属性主要有三个:output_classes(返回单元的数据类,tf.Tensor或tf.SparseTensor),output_shapes(dataset数据单元的shape),output_types(dataset数据单元的数据类型)。
data_numpy=np.array([[1,2,3,4,5],[1,2,3,4,5]])
dataset=tf.data.Dataset.from_tensors(data_numpy)
print(dataset.output_classes)#
print(dataset.output_shapes)#(2, 5)
print(dataset.output_types)# (2)从内存中读取数据
Dataset从内存中读取数据适用于数据较少,可直接存储于内存中的情况,其方法主要包括:from_generator(从生成器读取)、from_sparse_tensor_slices(从sparsetensor切边读取)、from_tensor_slices(从tensor切片读取)、from_tensors(从tensor读取)、range(按要求生成区间范围内的数据)。下面给出from_tensor_slices(根据tensorflow API中的说明,from_sparse_tensor_slices功能将被from_tensor_slices取代)以及from_generator的用法。
其中,使用from_generator方法,需要提供三个参数(generator、output_types、output_shapes),其中generator参数必须支持iter()协议(e.g. a generator function),也就是需要具有迭代功能,推荐使用python yield。
#从切片读入数据
data_numpy=np.array([[1,2,3,4,5],[1,2,3,4,5]])
dataset=tf.data.Dataset.from_tensors(data_numpy)
#从生成器中读入数据
"""
@staticmethod
from_generator(
generator,#生成器
output_types,#单元数据类型
output_shapes=None#单元数据shape
)
"""
import itertools
sess=tf.Session()
def gen():
for i in itertools.count(1):
yield (i, [1] * i)
ds = tf.data.Dataset.from_generator(
gen, (tf.int64, tf.int64), (tf.TensorShape([]), tf.TensorShape([None])))
value = ds.make_one_shot_iterator().get_next()
print(sess.run(value)) # (1, array([1]))
print(sess.run(value)) # (2, array([1, 1]))(3)从文件中读取数据
Dataset可从硬盘文件中读取数据,并配合相应的解码函数,实现对文本、图像等数据的处理。以下代码分别为实现对图像的读取、对文本文件的处理,以及使用list_files获取目标文件的文件名数据集。
读取图像文件,并修改图像的尺寸。
#读入图片数据并进行解码
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def _parse_function(filename, label):
image_string = tf.read_file(filename)
#image_decoded = tf.image.decode_image(image_string),建议使用对应的解码文件,使用
#decode_image的时候出错
image_decoded=tf.image.decode_jpg(image_string)
#选用method,使用最邻近插值,返回的结果仍为图像数据,使用其他方法则返回float数据
image_resized = tf.image.resize_images(image_decoded, [28, 28],method=1)
return image_resized, label
# A vector of filenames.
filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...])
# `labels[i]` is the label for the image in `filenames[i].
labels = tf.constant([0, 37, ...])
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
dataset = dataset.map(_parse_function)
sess=tf.InteractiveSession()
tf.global_variables_initializer().run()
iterator=dataset.make_one_shot_iterator()
next_element = iterator.get_next()
features,label=sess.run(next_element)
plt.figure(0)
plt.imshow(features)
plt.show()文本文件的读取及处理,改程序为鸷尾花数据的处理,从“*.csv”文件中读取文本数据,并跳过首行,然后按照
#读取文本文件,并进行解码,该程序需要在eager execution下运行
from __future__ import absolute_import, division, print_function
import os
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.contrib.eager as tfe
tf.enable_eager_execution()
print("TensorFlow version: {}".format(tf.VERSION))
print("Eager execution: {}".format(tf.executing_eagerly()))
train_dataset_fp='/home/gczx_gpu/.keras/datasets/iris_training.csv'
def parse_csv(line):
example_defaults=[[0.],[0.],[0.],[0.],[0]]
parsed_line=tf.decode_csv(line,example_defaults)
features=tf.reshape(parsed_line[:-1],shape=(4,))
label=tf.reshape(parsed_line[-1],shape=())
return features,label
train_dataset = tf.data.TextLineDataset(train_dataset_fp)
train_dataset = train_dataset.skip(1) # skip the first header row
train_dataset = train_dataset.map(parse_csv) # parse each row
train_dataset = train_dataset.shuffle(buffer_size=1000) # randomize
train_dataset = train_dataset.batch(32)
# View a single example entry from a batch
features, label = iter(train_dataset).next()
print("example features:", features[0])
print("example label:", label[0])获取文件名数据集,主要通过定义要处理的文件夹下的文件名称模板,如‘/path/*.py’。同时,该方法可对获取的文件名进行随机排序。
#获取文件名集合
'''
list_files(
file_pattern,
shuffle=None
)
Args:
file_pattern: A string or scalar string tf.Tensor, representing the filename pattern that will be matched.
shuffle: (Optional.) If True, the file names will be shuffled randomly. Defaults to True.
Returns:
Dataset: A Dataset of strings corresponding to file names.
'''
file_pattern='/path/to/dir/*.py'
file_lists=tf.data.Dataset(file_pattern,shuffle=True)(4)单元素及多元素处理(变换)
Dataset具有丰富的方法,其中一些方法针对数据集中的元素进行处理,另外一些方法在数据集层面进行处理,上面使用的Dataset.map( )就是针对数据集中的每一个元素进行处理。这块主要记录一下Dataset.map()、Dataset.filter()(对数据集的元素按照一定的条件逐一过滤,函数的返回值为bool值)、Dataset.flat_map()、Dataset.interleave()、Dataset.apply()(参数为转化函数,实现对单个或多个元素的处理)、Dataset.skip()(参数为整数,跳过n个元素,若n为-1跳过所有的元素)。其中,flat_map、interleav虽然是对Dataset中的每一个元素进行处理,但其处理的的元素必须是dataset的实例,也就是要从dataset元素中生成新的dataset,这个需要注意。
#Dataset.map()用法
import numpy as np
data_numpy=np.array([1,2,3,4,5])
dataset=tf.data.Dataset.from_tensor_slices(data_numpy)
dataset=dataset.map(lambda x:x+2)
features = iter(dataset).next()#在eager Execution下使用
print(features) #3#Dataset.filter()的使用
data=np.array([1,2,3,4,5,6,7,8,9])
dataset_1=tf.data.Dataset.from_tensor_slices(data)
dataset_1=dataset_1.filter(lambda x:tf.equal(x,5))
features = iter(dataset_1).next()
print(features) #tf.Tensor(5, shape=(), dtype=int64)
#flat_map的使用
filenames = ["/var/data/file1.txt", "/var/data/file2.txt"]
dataset = tf.data.Dataset.from_tensor_slices(filenames)
# Use `Dataset.flat_map()` to transform each file as a separate nested dataset,
# and then concatenate their contents sequentially into a single "flat" dataset.
# * Skip the first line (header row).
# * Filter out lines beginning with "#" (comments).
dataset = dataset.flat_map(
lambda filename: (
tf.data.TextLineDataset(filename)
.skip(1)
.filter(lambda line: tf.not_equal(tf.substr(line, 0, 1), "#"))))
#interleave的使用
a = np.array([1, 2, 3, 4, 5])
a=tf.data.Dataset.from_tensor_slices(a)
a=a.interleave(lambda x: tf.data.Dataset.from_tensors(x).repeat(6),
cycle_length=2, block_length=4)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
iterator =a.make_one_shot_iterator()
next_element = iterator.get_next()
for i in range(20):
features=sess.run(next_element)
print(features)#1,1,,1,1,2,2,2,2,1,1,3,3,3,3,4,4,3,3(5)数据集处理
这里所说的对数据集进行处理是指Dataset这些方法的参数输入为数据集,其主要包括Dataset.concatenate()、Dataset.zip()、Dataset.prefetch()等操作。concatenate()实现两个数据集的拼接,zip()实现对给定的数据集元素层面的数据集整合并生成新的数据集,prefetch()(参数为tf.int64)实现从数据集中取出一部分生成新的数据集。
#concatenate用法
a = { 1, 2, 3 }
b = { 4, 5, 6, 7 }
a.concatenate(b) == { 1, 2, 3, 4, 5, 6, 7 }
#zip用法
a = { 1, 2, 3 }
b = { 4, 5, 6 }
c = { (7, 8), (9, 10), (11, 12) }
Dataset.zip((a, b, c)) == { (1, 4, (7, 8)),
(2, 5, (9, 10)),
(3, 6, (11, 12)) }
(6)模型训练的相关数据设置
在深度学习的模型训练过程中,经常对数据进行随机打乱,并采用小批量数据进行每一步的训练,Dataset集成了这些功能,使用起来非常方便。Dataset.batch()(参数为tf.int64,代表小批量数据的数量,根据内存决定。若最后一个batch的N数量不够,则batch中的元素为N%batch)、Dataset.padded_batch()(同batch功能相同,但加入了数据补全功能,适用与文本数据的处理)、Dataset.repeat()(参数为tf.int64,数据集元素重复的次数,若无参数,代表无限重复)、Dataset.shared()(进行分布式计算)、Dataset.shuffle()(参数)
"""
方法使用一个固定大小的缓冲区,在条目经过时随机化处理条目。在这种情况下,buffer_size 大于 Dataset 中样本的数量,
确保数据完全被随机化处理。
"""
shuffle(
buffer_size,#tf.int64
seed=None,
reshuffle_each_iteration=None
)
Iterator的使用详解
Iterator实现对数据集中元素的访问,其有四中方式(以下为tensorflow编程指导的原文)。
(1)单次迭代
单次迭代器是最简单的迭代器形式,仅支持对数据集进行一次迭代,不需要显式初始化。单次迭代器可以处理基于队列的现有输入管道支持的几乎所有情况,但它们不支持参数化。以 Dataset.range() 为例:
dataset = tf.data.Dataset.range(100)
iterator = dataset.make_one_shot_iterator()
next_element = iterator.get_next()
for i in range(100):
value = sess.run(next_element)
assert i == value
(2)可初始化的迭代
您需要先运行显式 iterator.initializer 操作,然后才能使用可初始化迭代器。虽然有些不便,但它允许您使用一个或多个 tf.placeholder() 张量(可在初始化迭代器时馈送)参数化数据集的定义。继续以 Dataset.range() 为例:
#对数据集传入参数max_value
max_value = tf.placeholder(tf.int64, shape=[])
dataset = tf.data.Dataset.range(max_value)
iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
# Initialize an iterator over a dataset with 10 elements.
sess.run(iterator.initializer, feed_dict={max_value: 10})
for i in range(10):
value = sess.run(next_element)
assert i == value
# Initialize the same iterator over a dataset with 100 elements.
sess.run(iterator.initializer, feed_dict={max_value: 100})
for i in range(100):
value = sess.run(next_element)
assert i == value
(3)可重新初始化的迭代
可重新初始化迭代器可以通过多个不同的 Dataset 对象进行初始化。例如,您可能有一个训练输入管道,它会对输入图片进行随机扰动来改善泛化;还有一个验证输入管道,它会评估对未修改数据的预测。这些管道通常会使用不同的 Dataset 对象,这些对象具有相同的结构(即每个组件具有相同类型和兼容形状)。
# Define training and validation datasets with the same structure.
training_dataset = tf.data.Dataset.range(100).map(
lambda x: x + tf.random_uniform([], -10, 10, tf.int64))
validation_dataset = tf.data.Dataset.range(50)
# A reinitializable iterator is defined by its structure. We could use the
# `output_types` and `output_shapes` properties of either `training_dataset`
# or `validation_dataset` here, because they are compatible.
iterator = tf.data.Iterator.from_structure(training_dataset.output_types,
training_dataset.output_shapes)
next_element = iterator.get_next()
training_init_op = iterator.make_initializer(training_dataset)
validation_init_op = iterator.make_initializer(validation_dataset)
# Run 20 epochs in which the training dataset is traversed, followed by the
# validation dataset.
for _ in range(20):
# Initialize an iterator over the training dataset.
sess.run(training_init_op)
for _ in range(100):
sess.run(next_element)
# Initialize an iterator over the validation dataset.
sess.run(validation_init_op)
for _ in range(50):
sess.run(next_element)
(4)可馈送的迭代
可馈送迭代器可以与 tf.placeholder 一起使用,通过熟悉的 feed_dict 机制选择每次调用 tf.Session.run 时所使用的 Iterator。它提供的功能与可重新初始化迭代器的相同,但在迭代器之间切换时不需要从数据集的开头初始化迭代器。例如,以上面的同一训练和验证数据集为例,您可以使用 tf.data.Iterator.from_string_handle 定义一个可让您在两个数据集之间切换的可馈送迭代器:
# Define training and validation datasets with the same structure.
training_dataset = tf.data.Dataset.range(100).map(
lambda x: x + tf.random_uniform([], -10, 10, tf.int64)).repeat()
validation_dataset = tf.data.Dataset.range(50)
# A feedable iterator is defined by a handle placeholder and its structure. We
# could use the `output_types` and `output_shapes` properties of either
# `training_dataset` or `validation_dataset` here, because they have
# identical structure.
handle = tf.placeholder(tf.string, shape=[])
iterator = tf.data.Iterator.from_string_handle(
handle, training_dataset.output_types, training_dataset.output_shapes)
next_element = iterator.get_next()
# You can use feedable iterators with a variety of different kinds of iterator
# (such as one-shot and initializable iterators).
training_iterator = training_dataset.make_one_shot_iterator()
validation_iterator = validation_dataset.make_initializable_iterator()
# The `Iterator.string_handle()` method returns a tensor that can be evaluated
# and used to feed the `handle` placeholder.
training_handle = sess.run(training_iterator.string_handle())
validation_handle = sess.run(validation_iterator.string_handle())
# Loop forever, alternating between training and validation.
while True:
# Run 200 steps using the training dataset. Note that the training dataset is
# infinite, and we resume from where we left off in the previous `while` loop
# iteration.
for _ in range(200):
sess.run(next_element, feed_dict={handle: training_handle})
# Run one pass over the validation dataset.
sess.run(validation_iterator.initializer)
for _ in range(50):
sess.run(next_element, feed_dict={handle: validation_handle})
参考
https://blog.csdn.net/kwame211/article/details/78579035/
https://tensorflow.google.cn/versions/r1.8/api_docs/python/tf/data
https://tensorflow.google.cn/programmers_guide/datasets