使用python网络爬虫爬取新浪新闻(二)
在这我把我学习的视频说明下:
我是在网易云课堂中的Python网络爬虫实战学的,大家感兴趣的可以自己去看看。
在第一部分中,我们已经能够从一个网页中找到自己所需要的内容。那么接下来,我们要做的就是从一则新闻的内容中获得我们所需要的内容,包括标题、内容、时间、作者、来源和评论数。
那就开始吧!
在第一部分的介绍中,我介绍了通过BeautifulSoup4的套件来处理html文档的方法,然后通过该套件获取了在class为blk12中标签为里面的内容。其实取得新闻的标题、内容、时间、作者、来源,都是使用的该方法
还是直接看代码和截图吧,简介明了
这里我打开了一则新闻,通过开发者工具找到了文章标题所对应的html内容,这里我们发现这则新闻的标题放在class=”main-title”的标签中
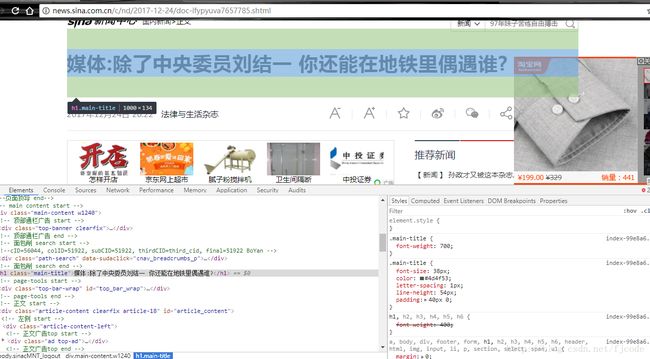
因此我们就可以使用BeautifulSoup获取标题
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/c/nd/2017-12-24/doc-ifypyuva7657785.shtml')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
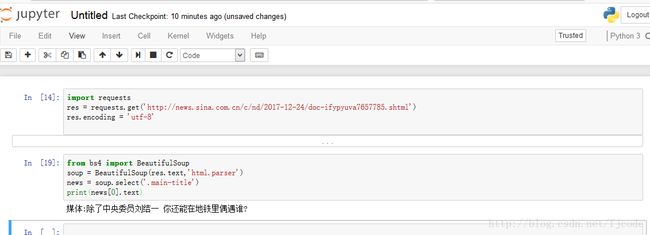
news = soup.select('.main-title')
print(news[0].text)结果如下:
因此内容、时间、作者、来源的获取就很简单了,和上面一样
articles = soup.select('.article p')
for article in articles:
print(article.text)结果如下:

我们发现有一个小问题,那就是文章的编辑是直接放在文章内容的末尾的,那么我们可以在这样读取
articles = soup.select('.article p')
for article in articles[:-1]:
print(article.text)看结果,没有了吧!

但是我们发现还有一个小问题,就是这些文字中间还有很多空格,那么我们可以这样做:
articles = soup.select('.article p')
art = []
for article in articles[:-1]:
#将列表中每项的空白部分去掉,然后加入到新的列表中
art.append(article.text.strip())
#将新的列表中的每项以空格的形式结合在一起
' '.join(art)结果如下,这就算完成了

接下来获取时间、作者、来源我就不解释了
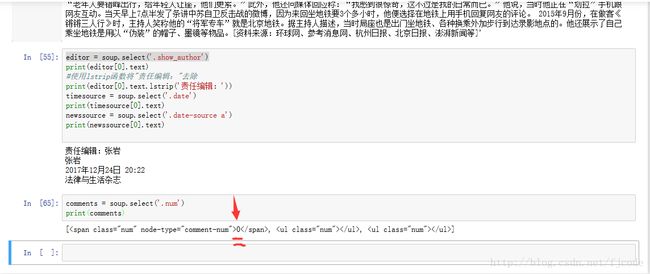
editor = soup.select('.show_author')
print(editor[0].text)
#使用lstrip函数将"责任编辑:"去除
print(editor[0].text.lstrip('责任编辑:'))
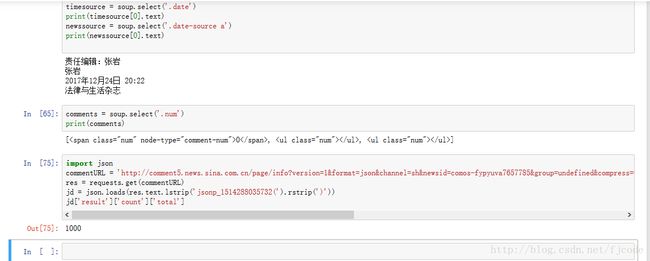
timesource = soup.select('.date')
print(timesource[0].text)
newssource = soup.select('.date-source a')
print(newssource[0].text)结果:

最后,解决获取评论数的问题:
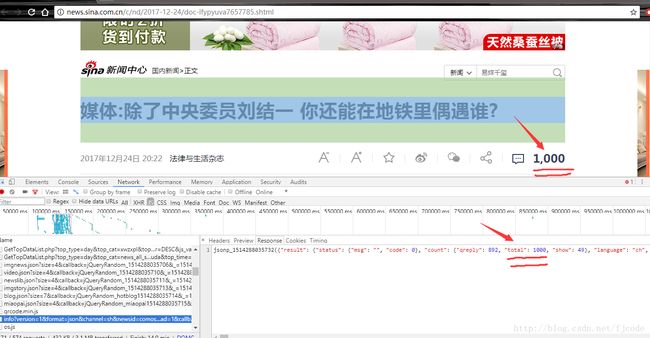
我们先来看看评论数所在的位置:
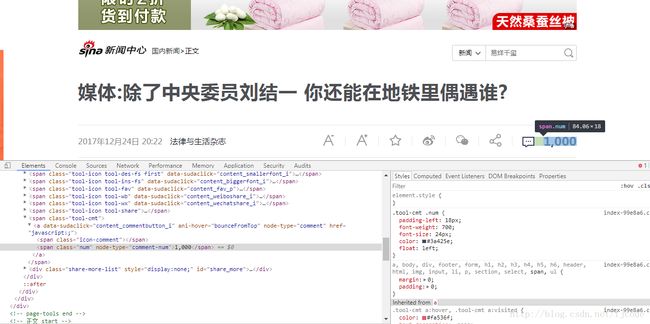
我们发现这里面也有个1000,然后我们可能会想到直接使用之前的方法就行了。不过当然是不行了,不然我就不会单独说了,为什么不行了呢?
我们来看看如果使用之前的方法会怎么样:
我们发现里面的内容显示的是0,原因是评论数是通过json的方法粘贴上去的,因此我们就要去找这个js
然后我们使用开发者工具,打开Network,在js里面找到了这个,对比发现这就是我们要找的
因此我们就打开文件头,找到链接
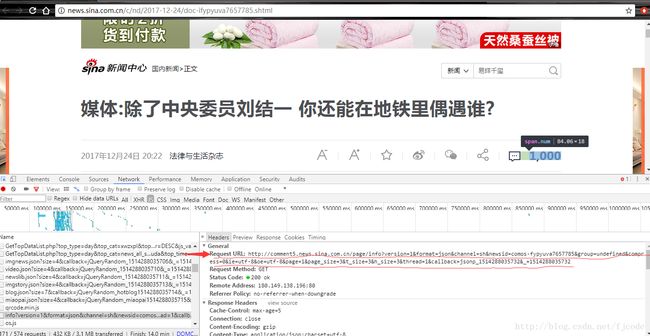
接下来我们就可以通过该链接来获取评论数了,这里得用到一个新的套件json,通过使用json套件中的loads方法将已编码的 JSON 字符串解码为 Python 对象
从图片中我们可以发现返回的对象包裹着一层json标签
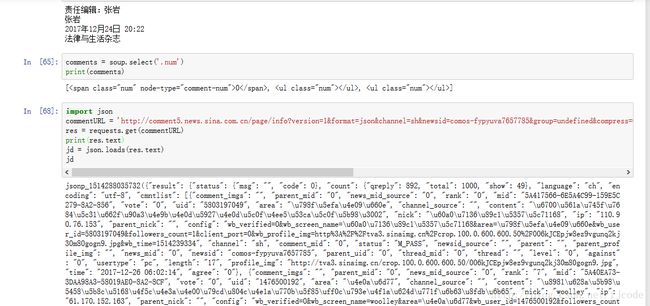
因此,我们可以使用strip方法将包裹的json标签去除,然后我们得到一个字典
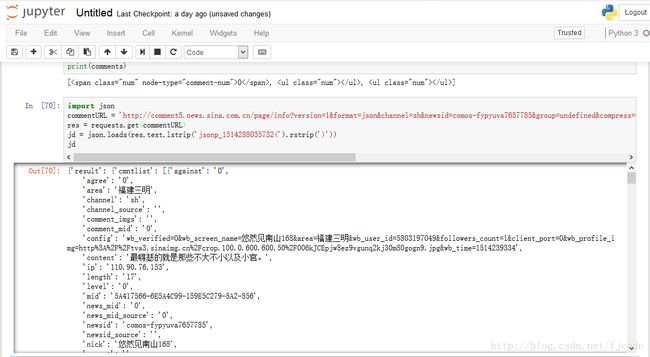
通过之前这张图片
我们知道了评论数在字典里面的位置,所以我们就这样写
import json
commentURL = 'http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=sh&newsid=comos-fypyuva7657785&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1&callback=jsonp_1514288035732&_=1514288035732'
res = requests.get(commentURL)
jd = json.loads(res.text.lstrip('jsonp_1514288035732(').rstrip(')'))
jd['result']['count']['total']看看结果吧:
大功告成,哈哈!!
先写这么多吧