Java集合:HashMap
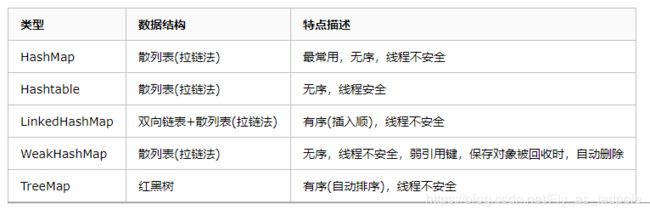
各种Map总结
-
就比如问你 HashMap 是不是有序的?你回答不是有序的。
-
那面试官就会可能继续问你,有没有有序的Map实现类呢?你如果这个时候说不知道的话,那这块问题就到此结束了。如果你说有 TreeMap 和 LinkedHashMap。
-
那么面试官接下来就可能会问你,TreeMap 和 LinkedHashMap 是如何保证它的顺序的?如果你回答不上来,那么到此为止。如果你说
-
TreeMap 是通过实现 SortMap 接口,基于红黑树,能够把它保存的键值对根据 key 排序,从而保证 TreeMap 中所有键值对处于有序状态。TreeMap的所有key都必须实现Comparable接口,所有key必须是同一类型。自定义类型需要重写equals方法,且返回值要和compareTo保持一致。
-
LinkedHashMap 则是通过维护一个双向链表,使用插入排序(就是你 put 的时候的顺序是什么,取出来的时候就是什么样子)和访问排序(改变排序把访问过的放到底部)让键值有序。也由于需要维护元素的插入顺序,所以性能较之HashMap要差一些。
-
那么面试官还会继续问你,你觉得它们两个哪个的有序实现比较好?如果你依然可以回答的话,那么面试官会继续问你,你觉得还有没有比它更好或者更高效的实现方式?
有什么方法可以减少hash碰撞?
1.扰动函数可以减少碰撞
原理是如果两个不相等的对象返回不同的 hashcode 的话,那么碰撞的几率就会小些。这就意味着存链表结构减小,这样取值的话就不会频繁调用 equal 方法,从而提高 HashMap 的性能(扰动即 Hash 方法内部的算法实现,目的是让不同对象返回不同 hashcode)。
2.使用不可变的、声明作 final 对象,并且采用合适的 equals() 和 hashCode() 方法,将会减少碰撞的发生
不可变性使得能够缓存不同键的 hashcode,这将提高整个获取对象的速度,使用 String、Integer 这样的 wrapper 类作为键是非常好的选择。
为什么 String、Integer 这样的 wrapper 类适合作为键?
因为 String 是 final,而且已经重写了 equals() 和 hashCode() 方法了。不可变性是必要的,因为为了要计算 hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的 hashcode 的话,那么就不能从 HashMap 中找到你想要的对象。
3.开放定址法
当冲突发生时,使用某种探查技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定的地址。按照形成探查序列的方法不同,可将开放定址法区分为线性探查法、二次探查法、双重散列法等。
例子:已知一组关键字为 (26,36,41,38,44,15,68,12,06,51),用除余法构造散列函数,用线性探查法解决冲突构造这组关键字的散列表。
解答:为了减少冲突,通常令装填因子 α 由除余法因子是13的散列函数计算出的上述关键字序列的散列地址为 (0,10,2,12,5,2,3,12,6,12)。
前5个关键字插入时,其相应的地址均为开放地址,故将它们直接插入 T[0]、T[10)、T[2]、T[12] 和 T[5] 中。
当插入第6个关键字15时,其散列地址2(即 h(15)=15%13=2)已被关键字 41(15和41互为同义词)占用。故探查 h1=(2+1)%13=3,此地址开放,所以将 15 放入 T[3] 中。
当插入第7个关键字68时,其散列地址3已被非同义词15先占用,故将其插入到T[4]中。
当插入第8个关键字12时,散列地址12已被同义词38占用,故探查 hl=(12+1)%13=0,而 T[0] 亦被26占用,再探查 h2=(12+2)%13=1,此地址开放,可将12插入其中。
类似地,第9个关键字06直接插入 T[6] 中;而最后一个关键字51插人时,因探查的地址 12,0,1,…,6 均非空,故51插入 T[7] 中。
HashMap 中 hash 函数怎么是实现的?
我们可以看到,在 hashmap 中要找到某个元素,需要根据 key 的 hash 值来求得对应数组中的位置。如何计算这个位置就是 hash 算法。
前面说过,hashmap 的数据结构是数组和链表的结合,所以我们当然希望这个 hashmap 里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个。那么当我们用 hash 算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。 所以,我们首先想到的就是把 hashcode 对数组长度取模运算。这样一来,元素的分布相对来说是比较均匀的。
但是“模”运算的消耗还是比较大的,能不能找一种更快速、消耗更小的方式?我们来看看 JDK1.8 源码是怎么做的(被楼主修饰了一下)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
简单来说就是:
-
高16 bit 不变,低16 bit 和高16 bit 做了一个异或(得到的 hashcode 转化为32位二进制,前16位和后16位低16 bit 和高16 bit 做了一个异或)
-
(n-1) & hash 得到hash桶的下标
h%length与h&(length-1)得到的结果其实是一个值,但是为什么hashmap中要用后者呢
1.length(2的整数次幂)的特殊性导致了length-1的特殊性(二进制全为1)
2.位运算快于十进制运算,hashmap扩容也是按位扩容,所以相比较就选择了后者
你能谈谈他的容量问题吗?
我:hashmap的初始容量是16,内部有一个负载因子初始为0.75,当数组中元素达到初始值*负载因子时,就会进行扩容。方法是使用一个新的数组,数组大小为原来的两倍。当然负载因子的大小是可调的,当我们有足够的内存而且非常看重时间的时候,可以将负载因子减小一点,反之可以增加负载因子。
那为什么初始容量是16?
· 我:在计算数组索引位置的时候, hash值&(数组长度-1)得到所在数组的index
采用两次hash 第一次是调用hashcode()方法得到h,第二次是用h&(length-1)。
当length为偶数的时候(length-1)得到的二进制的最后一位为1,&运算后即能得到奇数又能得到偶数。而length为奇数仅仅能得到偶数,这样浪费了一半空间。
这里扩容为啥是2倍?
因为2倍的话,更加容易计算他们所在的桶,并且各自不会相互干扰。
如原桶长度是4,现在桶长度是8,那么
· 桶0中的元素会被分到桶0和桶4中
· 桶1中的元素会被分到桶1和桶5中
· 桶2中的元素会被分到桶2和桶6中
· 桶3中的元素会被分到桶3和桶7中
为啥是这样呢?
桶0中的元素的hash值后2位必然是00,这些hash值可以根据后3位000或者100分成2类数据(0,4一类,8,12一类)。他们分别&(8-1)即&111,则后3位为000的在桶0中,后3位为100的必然在桶4中。其他同理,也就是说桶4和桶0重新瓜分了原来桶0中的元素。
如果换成其他倍数,那么瓜分就比较混乱了。
这样在瓜分这些数据的时候,只需要先把这些数据分类,如上述桶0中分成000和100 2类,然后直接构成新的链表,分类完毕后,直接将新的链表挂在对应的桶下即可
当length为合数[二的幂方]时h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率,这样保证了索引能均匀分布。
取16是为了增加桶数组的利用率和减少hash碰撞,还有提升扩容时分配元素的方便性。
HashMap在JDK1.8及以后的版本中引入了红黑树结构,若桶中链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。
为什么是8?为什么是6?
因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
使用链表,平均查找长度?
最好情况是1,最差情况是n,所以平均是(1+n)/2
拉链法导致的链表过深,为什么不用二叉查找树代替而选择红黑树?为什么不一直使用红黑树?
之所以选择红黑树是为了解决二叉查找树的缺陷:二叉查找树在特殊情况下会变成一条线性结构(左斜树,右斜树等,这就跟原来使用链表结构一样了,造成层次很深的问题),遍历查找会非常慢。而红黑树在插入新数据后可能需要通过左旋、右旋、变色这些操作来保持平衡。引入红黑树就是为了查找数据快,解决链表查询深度的问题。我们知道红黑树属于平衡二叉树,为了保持“平衡”是需要付出代价的,但是该代价所损耗的资源要比遍历线性链表要少。所以当长度大于8的时候,会使用红黑树;如果链表长度很短的话,根本不需要引入红黑树,引入反而会慢。
Hashtable
-
数组 + 链表方式存储
-
默认容量:11(质数为宜)
-
put操作:首先进行索引计算 (key.hashCode() & 0x7FFFFFFF)% table.length;若在链表中找到了,则替换旧值,若未找到则继续;当总元素个数超过 容量 * 加载因子 时,扩容为原来 2 倍并重新散列;将新元素加到链表头部
-
对修改 Hashtable 内部共享数据的方法添加了 synchronized,保证线程安全
HashMap 与 Hashtable 区别
-
默认容量不同,HashMap是16,Hashtable是11。扩容不同
-
线程安全性:HashTable 安全,使用了synchronized同步
-
效率不同:HashTable 要慢,因为加锁
Map是用来存储key-value类型数据的,一个对在Map的接口定义中被定义为Entry,HashMap内部实现了Entry接口。HashMap内部维护一个Entry数组。 transient Entry[] table;
当put一个新元素的时候,根据key的hash值计算出对应的数组下标。数组的每个元素是一个链表的头指针,用来存储具有相同下标的Entry。
hashmap放入顺序和输出顺序是不一致的!要想维持插入序,可使用LinkedHashMap
遍历HashMap的四种方法:
public static void main(String[] args) {
Map map=new HashMap();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
map.put("4", "value4");
//第一种:普通使用,二次取值
System.out.println("\n通过Map.keySet遍历key和value:");
for(String key:map.keySet())
{
System.out.println("Key: "+key+" Value: "+map.get(key));
}
//第二种
System.out.println("\n通过Map.entrySet使用iterator遍历key和value: ");
Iterator map1it=map.entrySet().iterator();
while(map1it.hasNext())
{
Map.Entry entry=(Entry) map1it.next();
System.out.println("Key: "+entry.getKey()+" Value: "+entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("\n通过Map.entrySet遍历key和value");
for(Map.Entry entry: map.entrySet())
{
System.out.println("Key: "+ entry.getKey()+ " Value: "+entry.getValue());
}
//第四种
System.out.println("\n通过Map.values()遍历所有的value,但不能遍历key");
for(String v:map.values())
{
System.out.println("The value is "+v);
}
}