spark03--textFile分区算法,常用算子使用,启动,任务提交流程, 基站案例
文章目录
- 一 textFile分区算法
- 二 常用算子使用
- 2.1 map mapPartitions
- 2.2 mapPartitionsWithIndex
- 2.3 aggregate
- 2.4 aggregateByKey
- 2.5 combineByKey
- 2.6 countByKey和countByValue
- 2.7 filterByRange
- 2.8 flatMapValues
- 2.9 foldByKey
- 2.10 foldByKey实现Wordcount
- 2.11 foreachPartition
- 2.12 keyBy
- 2.13 keys values
- 2.14 collectAsMap
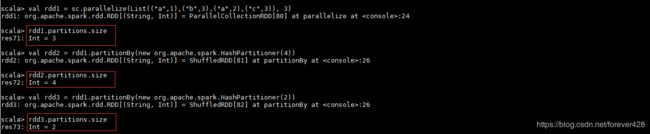
- 2.15 repartition, coalesce, partitionBy
- 2.16 checkpoint
- 三 spark集群启动流程
- 四 spark任务提交流程
- 五 基站案例
- 5.1需求
- 5.2已有的两个文件
- 5.3 求解思路
- 5.4 求解过程
- 5.5 运行结果
一 textFile分区算法
小文件 --> (指定分区数量/文件数量)[向上取整] * 文件数量
源码粗略解析
- 求出文件总totalSize, 获取指定分区数量num
- 获取文件大小size和块大小blockSize的最小值, 这里假设文件大小小于块大小
- bytesRemaining = [totalSize/num] 使用文件总长度除以分区数量取整
- bytesRemaining/splitSize > 1.1 遍历所有文件, 使用文件总长度除以指定分区数量, 如果bytesRemaining除以文件数量大于1.1的冗余, 则分成两个分区, 否则生成一个分区
实例:




- (1078+2081)/2=1579.5 取整 1579
- 遍历第一个文件: 1078/1579<1.1, 直接分成一个区
- 遍历第二个文件: 2081/1579>1.1, 生成一个分区后还剩2081-1579=0.31<1.1, 生成另一个分区
- 总共的分区加在一起是三个分区
二 常用算子使用
2.1 map mapPartitions
和map类似, 遍历每一个分区, 对每一个分区进行操作, 有返回值
mapPartitions f: Iterator[T] => Iterator[U]

2.2 mapPartitionsWithIndex
可以使用分区下标进行操作分区
参数列表:(f: (Int, Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false)

2.3 aggregate
聚合算子, 是一个柯里化, 可以传入两个参数列表, 第一个参数列表可以传入一个默认值, 第二个参数列表传入两个函数, 在聚合时, 先将传入的默认值加入到每一个分区中, 然后每一个分区根据传入的第一个函数进行聚合, 当每个分区聚合完成之后, 在根据传入的第二个函数对分区进行聚合操作, 在这一次聚合时, 默认值也算进来.
需要注意的是, 在第二次聚合时, 由于是多个线程并行执行, 所以当字符串在第二次聚合时不分先后, 结果也是不确定地.
(zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U


![]()
![]()
![]()
2.4 aggregateByKey
和aggregate类似, 只不过aggregateByKey操作的是键值对, 对key相同的进行聚合
(zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)
![]()
2.5 combineByKey
combineByKey: 需要三个参数, 第一个参数是创建一个Combiner的函数, 第二个参数是局部聚合函数, 第三个参数是全局聚合函数
(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C)
![]()

这里是创建两个List集合, 然后进行拉链操作, 将两个集合合并一下. 这里做的是将个数为1的动物放在一起, 将个数为2的动物放在一起

2.6 countByKey和countByValue
countByKey: 对键值对进行操作, 对相同的key进行累加操作
countByValue: 对完全相同的元素进行累加求和[容易忽略]

2.7 filterByRange
根据输入的key的范围进行过滤, 例如输入a,d 那么会根据key的字典顺序进行筛选, 选出属于a到d范围内的元素

2.8 flatMapValues
和flatMap类似, 这里操作的是values, 对values进行扁平化处理以及map操作, 操作完成之后将value 和对应的key组成一个元组
![]()
2.9 foldByKey
将key相同的value通过传入的运算进行操作

2.10 foldByKey实现Wordcount

2.11 foreachPartition
和foreach类似, foreachPartition是遍历每一个分区, 对每一个分区进行操作, 需要注意的是foreachPartition没有返回值, 所以在shell中看不到效果


2.12 keyBy
根据传入的函数进行操作, 将返回值作为key, 和原来的值拼成一个元组

2.13 keys values
可以获取到一个元组的key或者values

2.14 collectAsMap
collect的返回值是一个Array, 而在调用collectAsMap后, 返回值是一个Map
![]()
2.15 repartition, coalesce, partitionBy
- 在spark中重新分区的算子只有这三个
-
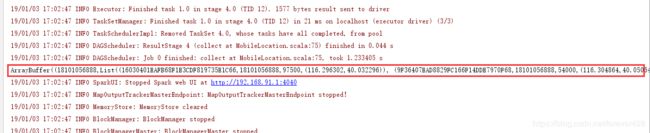
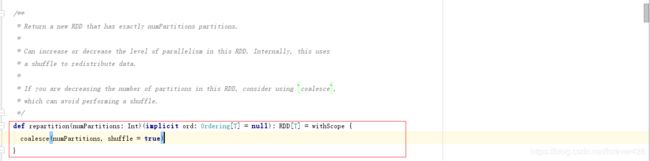
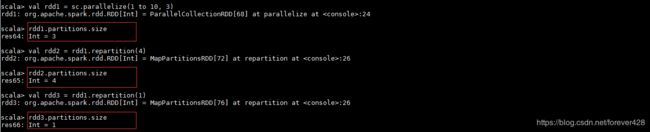
repartition: 一定会发生shuffle过程, 本身不会发生重新分区, 而是会返回一个新的分区
-
coalesce: 默认shuffle=false(不发生shuffle), 分区变多时需要手动指定shuffle为true, 否则分区数量不会改变, 而分区变少时, 不需要刻意指定shuffle, 因为分区变少不需要发生shuffle过程


-
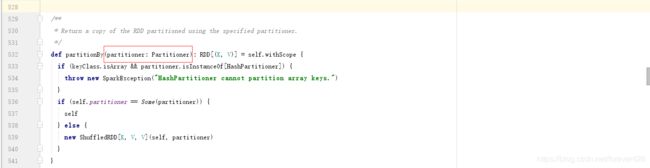
partitionBy: 参数是一个分区器, 需要自己传入一个分区器. 需要注意的是只有 k–>v形式的值 才能调用partitionBy的方法.
当某一个分区数据量比较大的时候会采取将这个分区拆分成多个分区
2.16 checkpoint
checkpoint可以将重要的中间结果集写入到磁盘, 方便下次直接使用, 无需再次运行, 提高效率. 可以将中间结果集放到本地磁盘或者HDFS上, 推荐放到HDFS上, HDFS多个副本, 保证数据的安全性
步骤:
- 指定一个目录
- 调用checkPoint算子(延迟加载)

三 spark集群启动流程
spark不同版本的RPC通信框架
spark 1.3--------->actor
spark 1.3~1.5--->AKKA
spark 1.6--------->AKKA+netty
spark 2.0--------->netty
spark集群启动流程
- Driver发送start-all.sh启动Master服务
- Master启动之后会启动一个定时器, 定时检查超时的Worker
- 通过解析slaves配置文件, 开始在响应的节点启动Worker服务
- Worker启动之后, 开始向Master发送注册信息
- Master收到注册信息后, 保存并响应客户端注册成功信息, 即发送给Worker一个URL
- Worker收到URL, 保存URL并定时向Master发送心跳信息
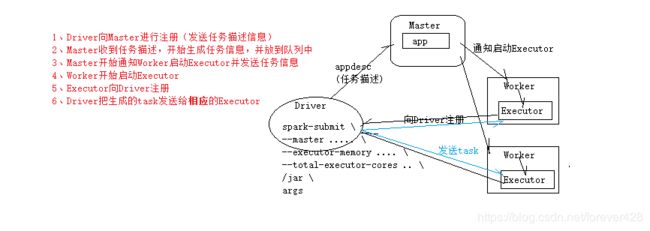
四 spark任务提交流程
任务提交命令
spark-submit \
--master spark//hadoop:7077 \
--executor-memory 1024g \
--total-executor-cores 2 \
.......jar args
任务提交流程
- Driver调用 spark-submit 提交任务, 向Master进行注册(发送任务描述信息)
- Master收到任务描述, 开始生成任务信息, 并将任务描述信息放到队列中
- Master通知Worker启动子进程Executor, 并发送任务信息
- Worker接收任务信息, 启动Executor
- Executor向Driver端进行注册
- Driver将生成的Task发送给相应的Executor
- Executor开始执行具体的任务
五 基站案例
5.1需求
根据用户进出基站的信息以及基站的基本信息求出用户所在时间最长的两个基站id
5.2已有的两个文件
文件1 用户进出基站信息
手机号, 时间戳, 基站id, 时间类型(1:进站, 0:出站)

文件2 基站基本信息
基站id, 经纬度,…

5.3 求解思路
根据第一个文件求出用户在每一个基站的停留时间. 然后和第二个文件进行join操作, 然后进行排序, 取出时间戳最大的前两个元素
5.4 求解过程
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object MobileLocation {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MobileLocation").setMaster("local")
val sc = new SparkContext(conf)
//获取用户访问信息
val files: RDD[String] = sc.textFile("G://06-Spark/sparkcoursesinfo/spark/data/lacduration/log")
//切分用户访问信息
val splitedUserInfo: RDD[((String, String), Long)] = files.map(line => {
val fields: Array[String] = line.split(",")
val phone: String = fields(0) //手机号
val time: Long = fields(1).toLong //时间戳
val lac: String = fields(2) //基站id
val eventType: Int = fields(3).toInt
val time_long = if (eventType == 1) -time else time //如果事件类型为1 , 将时间戳变成负的
((phone, lac), time_long)
})
// 计算用户在基站停留的总时长
val aggred: RDD[((String, String), Long)] = splitedUserInfo.reduceByKey(_ + _)
// 为了方便和基站进行join, 将数据进行调整
val lacAndPhoneAndTime: RDD[(String, (String, Long))] = aggred.map(tup => {
val phone: String = tup._1._1 // 手机号
val lac: String = tup._1._2 //基站id
val time: Long = tup._2 // 用户在某个基站停留的总时长
(lac, (phone, time))
})
// 获取基站信息
val lacInfo: RDD[String] = sc.textFile("G://06-Spark/sparkcoursesinfo/spark/data/lacduration/lac_info.txt")
// 切分基站信息
val splitedLacInfo: RDD[(String, (String, String))] = lacInfo.map(line => {
val fields: Array[String] = line.split(",")
val lac: String = fields(0) // 基站id
val x: String = fields(1) // 经度
val y: String = fields(2) // 纬度
(lac, (x, y))
})
// 用户信息和基站信息进行join
val joined: RDD[(String, ((String, Long), (String, String)))] = lacAndPhoneAndTime.join(splitedLacInfo)
val lacAndPhoenAndTimeAndXY: RDD[(String, String, Long, (String, String))] = joined.map(tup => {
val lac: String = tup._1 //基站id
val phone: String = tup._2._1._1 // 手机号
val time: Long = tup._2._1._2 // 停留时长
val xy: (String, String) = tup._2._2 // 经纬度
(lac, phone, time, xy)
})
// 为了便于统计用户在所有基站的信息 生成用户粒度的数据
val grouped: RDD[(String, Iterable[(String, String, Long, (String, String))])] = lacAndPhoenAndTimeAndXY.groupBy(_._2)
// 按照时长进行组内排序
//grouped.map(x=>(x._1,x._2.toList.sortBy(_._3).reverse))
val sorted: RDD[(String, List[(String, String, Long, (String, String))])] = grouped.mapValues(_.toList.sortBy(_._3).reverse)
// 获取top2
val res: RDD[(String, List[(String, String, Long, (String, String))])] = sorted.mapValues(_.take(2))
println(res.collect.toBuffer)
sc.stop()
}
}
5.5 运行结果