KinectFusion 解析
泡泡机器人KinectFusion讲解PPT:
http://pan.baidu.com/s/1eSDuhZs
地位和特点
1、基于RGB-D相机三维重建的开山之作,首次实现实时稠密的三维重建。
2、通过融合序列图像重建三维重建,如果显卡满足要求重建的帧率可以跟得上深度相机的帧率(30Hz)。
4、使用 TSDF 模型不断融合深度图像重建三维模型。
3、通过配准当前帧和模型投影获取的图像计算位姿,比通过配准当前帧和上一帧计算位姿要更加准确。
重建流程图

重建流程如上图所示:
a) 读入的深度图像转换为三维点云并且计算每一点的法向量;
b) 计算得到的带有法向量的点云,和通过光线投影算法根据上一帧位姿从模型投影出来的点云,利用 ICP 算法配准计算位姿;
c) 根据计算得到的位姿,将当前帧的点云融合到网格模型中去;
d) 根据当前帧相机位姿利用光线投影算法从模型投影得到当前帧视角下的点云,并且计算其法向量,用来对下一帧的输入图像配准。
如此是个循环的过程,通过移动相机获取场景不同视角下的点云,重建完整的场景表面。
Depth Map Conversion
在已知相机内参情况下,将深度相机获取到的深度图像转换成点云。
根据相邻像素点求得每个点的法向量,转换之后的带有法向量的点云如 a) 图所示
Camera Tracking
采用 ICP 算法计算两帧之间位姿,因为这里是实时的三维重建,相邻两帧之间位姿变化很小,R 矩阵可以做线性化,从而最小二乘有闭式解。
ICP 算法理论介绍:
http://blog.csdn.net/fuxingyin/article/details/51425721
ICP 算法 GPU 实现介绍:
http://blog.csdn.net/fuxingyin/article/details/51505854
KinectFusion 算法采用 frame-to-model (通过当前帧深度图像转换得到的点云,和根据上一帧相机位姿从模型投影获取的深度图像转换得到的点云进行配准)的方式,而不是采用 frame-to-frame (通过当前帧深度图像转换得到的点云,和上一帧深度图像转换得到的点云进行配准)的形式计算两帧位姿,作者论文里也验证了采用 frame-to-model 的形式重建要更加准确。
Volumetric Representation
深度相机获取的数据通常有噪声,而且一些场景(比如物体边缘)扫描出来的会有孔洞(没有深度的值的区域),三维模型重建需要消除噪声和孔洞的影响。
KinectFusion 中采用 TSDF 模型进行深度数据的融合,示意图如下:

TSDF 模型将整个待重建的三维空间划分成网格,每个网格中存储了数值,如下:

网格模型中值的大小代表网格离重建好的表面的距离,如上图表示的是重建的一个人的脸(网格模型中值为 0 的部分,红线表示重建的表面,示意图给出的二维信息,实际是三维的),重建好的表面到相机一侧都是正值,另一侧都是负值,网格点离重建好的表面距离越远绝对值越大,在网格模型中从正到负的穿越点表示重建好的场景的表面。
TSDF 模型隐含表示了重建好的表面。
KinectFusion 采用 ICP 算法计算相机的位姿,在计算得到相机位姿之后,将当前帧点云融合到三维模型中。
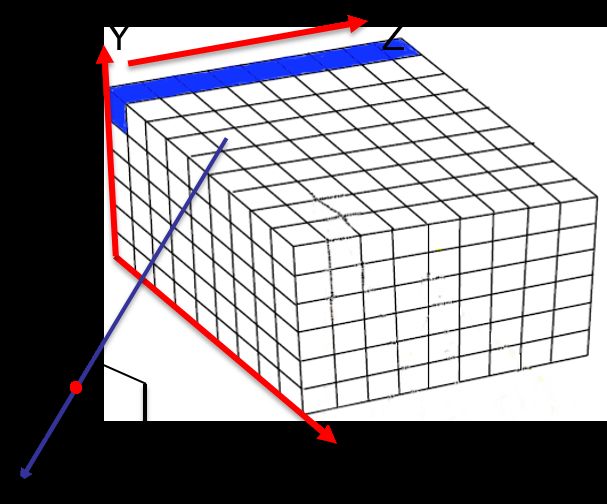
KinectFusion 采用 GPU 更新网格中的值,GPU 的每个线程处理如上图所示的一个蓝条,相当于每个线程处理一个 (x,y) 坐标上的一串网格,对于每个网格点,从网格模型坐标系(全局坐标系)转到相机坐标系,再根据相机的内参投影到相平面上。
将网格单元从全局坐标系转到相机坐标系: v=T−1ivg ,再从相机坐标系投影到相平面上: (u,v)=Av
按照如下进行更新:
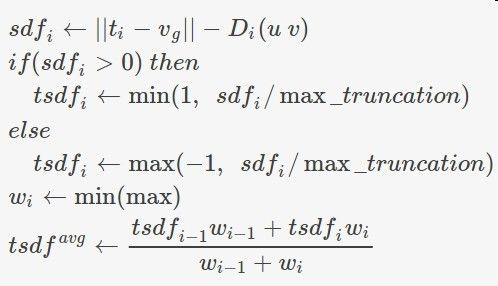
ti :表示相机光心在全局坐标系下的坐标。
vg :表示待更新的网格点在全局坐标系下的坐标
||ti−vg| :表示网格点到光心的 Z 向距离(深度)
Di(u,v) :表示像素位置 (u,v) 下相机测量到的深度值
tsdfavg :表示网格中通过不断加权融合更新的值
直观上理解:当相机测量到的深度值和网格到光心的距离近似相等时,更新网格加权融合时,加权的值小,也说明网格离待重建的场景表面近。
Raycasting
根据当前帧位姿,将当前帧的点云融合到网格模型中之后,再用光线投影算法计算在当前视角下可以看到的场景的表面,用来对下一帧的输入图像进行配准,计算下一帧相机的位姿。

如图:从光心出发,穿过像素点在网格模型中从正到负的穿越点,就表示在当前像素点处可以看到的重建好的场景的表面。对于每个像素点,分别做类似的投影,就可以计算得到的在每个像素点处的点云。
光线投影算法在实际计算的时候,也是用 GPU 并行计算,GPU 的单个线程处理单个的像素点。
采用光线投影算法计算得到的点云,再计算其法向量,用带法向量的点云和下一帧的输入图像配准,计算下一帧输入图像的位姿。如此是个循环的过程。
参考文献
1、”KinectFusion: Real-Time 3D Reconstruction and Interaction Using a MovingDepth Camera”
2、”KinectFusion: Real-Time Dense Surface Mapping and Tracking”