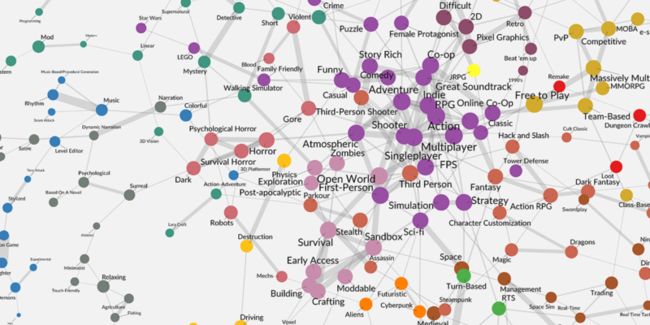
QuanticFoundry的Nick Yee近期在网站博客中发布了这篇文章,描述了他们如何对Steam中游戏标签进行做可视化的关联分析的。文末有原文地址和可视化图谱的下载地址。
Steam标签的简单介绍
玩家可以自行为Steam中任何一款游戏添加自己喜欢的标签。标签词的输入界面会根据输入的词匹配一些常见的标签,但也允许玩家们输入任何词汇。例如真三国无双8的游戏标签就是“动作”“开放世界”等等。不过由于界面空间有限,Steam为每个游戏展示热度(频率)排名前20的标签,其余的标签和其热度可以通过SteamSpy查询。
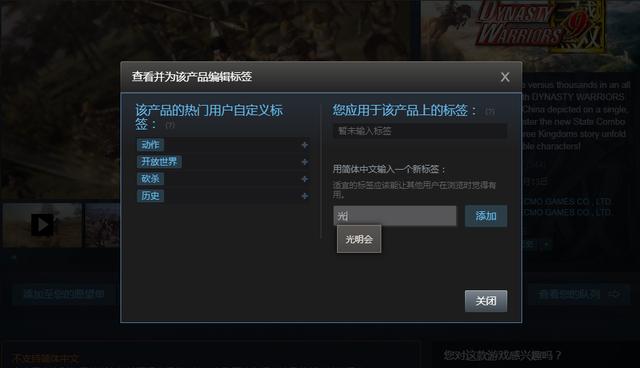
为了建立数据库,我们(Quanticfoundry)从玩家动机问卷(Gamer Motivation Profile, 大概有35万人填写过该问卷)的回答中找出了被玩家提及5次以上的游戏,剔除了Steam中没有的游戏后留下了共2129个游戏。然后我们提取了这些游戏的标签数据建立了用于分析的原始数据库(注:标签提取于2017年12月中旬)。
Steam 标签:优与劣
Steam的标签系统有着很高的分析价值。首先,它是一个由真实玩家们自发建立的大型数据库。其次,它的标签是由分众分类法(即玩家主导)而不是Steam自身推行的分类法所产生的。玩家自发形成的标签体系能够帮助跳出游戏开发商们关于游戏和游戏功能的固性思维和惯用词汇,我们能够获得那些受到玩家认可的新标签,例如:众筹等。
不过Steam标签也有着不太好的一面。首先,这些标签数据局限于Steam平台现有的游戏,而这无疑排除了一些大型开发商(例如EA的使命召唤和FIFA,暴雪的守望先锋和炉石传说等)和游戏平台(手游和3DS)的优秀作品。其次,尽管必要的时候Steam也会主动干预和清洗游戏的标签,但标签系统仍然受到玩家们主观影响。另外,像任何UGC一样,我们很可能会发现“大多数游戏标签来源于一小波的活跃玩家”的情况。
当然,即使有着这些潜在的风险,作为一个独特的大型数据库,Steam标签仍然是值得去探索和挖掘的。
如何定义标签之间的关系
对于两个事物之间的关系是否紧密、相似性如何,并不存在绝对正确的定义。例如,假设我们想要画出某人的社交网络图谱,这个图谱的最终成型很大程度上取决于我们对“亲密”的定义,它可以是每段关系的远近、或者是你对别人的关心程度、双方的交际频率或者直接就是地理距离等等。
这些情况对于Steam的标签数据而言也是一样的。在这里,我们将标签之间的关联定义为标签被应用的游戏之间的重合比例。即,首先看看标签A都被应用在哪些游戏中,然后再计算其它标签在这些游戏中被应用的比例。
数据处理要点
在任何大数据和关联网络分析中都需要做大量的数据处理工作。在这里我们为感兴趣的读者们描述一些数据处理的细节,不感兴趣的可跳过本部分内容。
剔除低频标签:由于标签多为玩家自发产生,我们收集到了许多低频的标签,而这些低频标签很可能会扰乱最终的可视化。标签的频数从324,505(“Action”, 动作)到10(“Cycling”,自行车)都有。在分析过程中我们将占比为底部百分之五的标签剔除(频率<= 85)。
剔除标签量过少的游戏:同样出于玩家产生标签的原因,有的游戏可能只被标记了很少量的标签,提供了不可靠的数据。游戏被标记次数分布从190,470次(GTA5)到10次都有。在本次分析剔除了标签数量占比为底部百分之2.5的游戏(被标记次数低于50次)。
剔除跨游戏使用频率低的标签:使用最广泛的标签出现在1463个游戏中,最狭窄的标签则只用于了一个游戏。在本次分析中剔除了应用范围占比为底部百分之五的标签(应用该标签的游戏在5个以下)。
关系距离的测量:在本次分析中我们使用杰卡德距离来表示标间之间的关系。杰卡德距离是在分析频数数据时常用的数据指标,它用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。在原始数据上做这种处理容易混淆标签的频数和关系(因为原始的标签数据和生成的标签关系分属于不同的数据类型),常用的处理方法是将标签距离转换成百分比。因此,对于每个游戏而言,每个标签频数都被转化成其占该游戏中最高频标签频数的百分比(数值分布为0~1)。
为什么不采用欧式距离?需要注意的是对每个游戏而言,Steam最多只展示20个标签。因此我们会得到很分散的数据,并且会存在很多“0”。在欧式距离中,“0”是有意义的,且双重缺失在欧式距离的处理中被认为是一次匹配。而在我们分析中,这样做其实是没有意义的。
游戏权重:距离测量的指标给每个游戏分配了相同的权重,但显然热门大作应该有相较于冷门游戏更高的权重。游戏的玩家数量的影响因素又过于庞杂,直接使用玩家数量做权重配比可能会导致少部分的游戏主导分析结果的产生。因此,我们对游戏玩家的数量进行了log处理来决定最终的游戏权重,最终的权重分布范围为1~15(中位数为4.4)。
可视化图谱的修剪:我们对关联网络进行了修剪以便于突出更加显著的标签关系。图谱中每个节点只保留密切程度在前5的关系。不过由于节点之间关系的交叉,图谱中也会有一些节点拥有不止5个关联节点。
关联网络的可视化:我们应用了Fruchterman-Rheingold算法(一种强制导向的布局算法)来描绘关联网络,然后采用了基于模块化优化(modularity optimization)的算法来找到关系群落。最终我们确认了26个关系群落,而其中有17个群落有着3个以上的节点。我们在图表中用不同的颜色对这17个群落进行了标记,而二元和三元关系都使用灰色进行标识。
最后的统计:我们最初获取了2129款游戏共321个标签,经过清洗后剩下了2070款游戏共279个标签。
可视化分析
关联网络中展示了每个游戏标签之间最紧密的相互联系。以下是一些帮助大家解读关系图的基本规则。
圆点表示标签:圆点和其相应的文字越大就意味着这个标签在Steam中出现的频率越高。
线段表示两个标签之间的关系:线段越粗代表两个标签在同一批游戏中同时出现的可能性越高。对每个标签而言,关联网络中呈现了最为紧密的相互关系。
重合的节点之间没有线段的存在:例如在棕色点“Space”和绿色点” Turn-Based”之间没有隐藏的线段,即二者之间没有在任何游戏中同时出现过。
颜色用于区别各个标签群落:标签群落指的是由共享线段所链接构建的凝聚子群,他们相互之间有着较为密切的关系。我们最终确定了17个标签群落,每个群落中包含有3个以上的标签。在关系图中我们用不同的颜色来区分这些群落。
节点之间的空间距离与相互关系无关。就像地铁上的路线图以站点顺序为优先而无视地理距离一样,我们的关联网络图中是以关系网络的呈现为优先。例如,在图右边缘上的“Hunting”距离“Top-Down Shooter”较近,但是由于它们之间没有表示关系的线段,所以它们之间相对接近的空间距离并不表示它们就是有关系的。

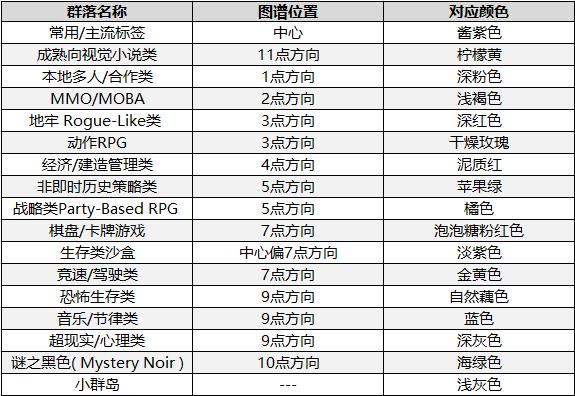
我们找到哪17个不同的群落?
下表中是我们最终确定的17个标签群落。表中对其相应的颜色和方位做了简要的说明。
关系图中隐藏着诸多有趣的信息,给你们几个示例,剩下的自行体会。
主流标签在图谱中心,而独特的标签则处于边缘位置。由于常用的标签很容易和其它常见标签共同应用于同一个游戏,这些标签就会相互吸引然后构成一个紧密的、朝中的核心。随着算法拆解节点,图谱就迅速形成了从通用、主流标签到独特、细微标签的层级结构。最常见的标签就位于关联网络的中间(例如RPG,Action等等),而那些独特和细微的标签则被分配到图谱的边缘位置(例如顶部的Romance)。
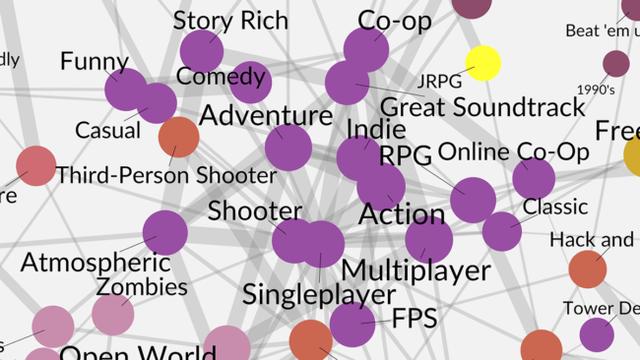
群岛。在图谱的边缘部分独立的标签们构成了群岛体系。这些通常是那些没能和主要的关联网络相互关联的独特标签。图谱中有9个小岛,这里和大家一起聊聊其中两个:首先是“Superhero”,尽管都没能和主体网络有所联系,但它也与多个相对频繁的标签相连。其次则是“Board/Card Game(棋牌/卡牌游戏)”,是唯一有着三个以上节点的小岛群落。一个群落拥有的节点越多,那么它越有可能和主体网络相互关联。因此,这样两个拥有丰富节点的独立小岛还是很罕见的。这意味着玩家对这两类游戏Steam标签 (和其相应的游戏)的认知与其它大多数游戏都有明显的差异。

粗壮的线段(紧密的联系)是群落的主要支柱。对于每个群落而言,那些最紧密的联系(最宽的线段)最能够代表该群落的特征,就像建筑物的承重梁一样支持着群落。例如,在“Visual Novel(视觉小说)”群落中最明显的联系就是“Anime-Romance(动漫-浪漫)”, “Nudity-Mature (裸露-成熟)”, “Choices Matter-Multiple Endings (选择导向-多结局)”。整个图谱可以视为对游戏类型关键元素的提取。

隔壁的标签是市场开拓的方向。尽管同属于策略类游戏,非即时历史战略类 (苹果绿)就和经济/建造管理类 (泥质红)就是两个完全不同的群落。而尽管他们两个有不少在空间距离很紧凑的节点,他们之间其实只有很少的标签之间存在不算紧密的联系。如果仔细看一下,这对邻居之间有三对节点存在相互的联系:Medieval-Historical, RTS-Base-Building, 和RTS-Economy。这将可能为“如何触达其它类型的游戏玩家”提供相应的运营/设计思路。
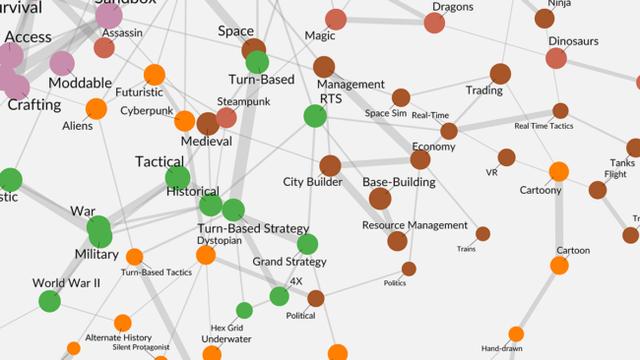
关系图谱反映了成功作品的特质。作为整合了2000多款Steam中最受欢迎游戏的标签图谱,它在一定程度上展示了这些成功作品的游戏功能和游戏主题。对每一个节点而言,与其关联最紧密的第一层标签代表了最受市场认可和接受的属性和特性组合。而第二层、第三层的标签(尤其是在跨群落的情况下)则可能存在一定的风险,但又有可能组合创造出新颖而有吸引力的游戏(尤其是当中介节点能够完美衔接这些标签的时候)。
数据可视化的另一个思路
如果你还有兴趣的话,这里还有我们换个思路对标签之间关系做的定义和可视化分析。

假设我们想要了解各细分人群的超市购物的差异。从原始数据中我们很可能会发现每个细分人群都倾向购买牛奶和面包,那是因为这些产品的基本占比太高了。所以,我们可以计算每个商品的消费人群中各细分群体人群所占的比例。例如,很少有人会在超市买褪黑激素丸,但是25~40岁的商务旅行者购买它的比例就相对于平均水平高出了20倍。
我们可以将这样的逻辑应用在Steam的标签上。与上文中计算标签在同一批游戏中应用的比例不同,我们这次通过计算两个标签同时出现的比例来表示距离(即找到某标签同时出现的所有标签然后用这些标签的频率除以基线频率)。
下图是按照这种方法描绘出来的关系图谱。可以看到与之前图谱中高频标签们(例如“Action”)都集中在中心位置不同,这个图谱中它们被打散排布在各个位置。同时,在各个节点之间也有了更多的关系线段,导致这个关联网络看起来更加密集。
当然,这两个关联网络并没有谁比谁好之分。以常用标签“Singleplayer(单机游戏)”为例:它是应该和“Adventure(冒险)”这样的常用标签紧密相连好呢?还是说因为它被的用法实在太宽泛了所以应该对其关系链进行精简呢?前一种做法能够反映更加真实的现状,而后者则便于探索一些微妙和隐晦的关联。
所以,目的决定手段。如果我们想要通过头脑风暴游戏的市场机会(在解释群落之间关联的时候有提到过),那么后一种关联网络更有可能引发有趣的想法,因为它提供了更加丰富的相互关系。前一种关联网络则更多的展现了Steam目前的游戏生态。
如果你在这两个关联网络中有了什么有趣的发现,欢迎分享到评论中,或者分享到作者原文。
原文地址:https://quanticfoundry.com/2018/01/24/visualizing-steam-tags-related/
你可以通过从原文中找到高清图谱的下载链接,或者直接按以下网址下载。
第一个关联网络:https://quanticfoundry.com/wp-content/uploads/2018/01/steam_tags_hi_res.png
第二个关联网络:https://quanticfoundry.com/wp-content/uploads/2018/01/steam_tags_odds_ratio_hi_res.png
PS. 新春第一篇!沉迷于偶像的我,齋藤飛鳥一生推!