面试之JDBC
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
JDBC为开发人员提供了一个标准的API,据此可以构建更高级的工具和接口,使数据库开发人员能够使用java API编写数据库应用程序,并且可跨平台运行,并且不受数据库供应商的限制。
JDBC为我们提供了java连接数据库的驱动。而这个驱动也是由Java开发出来的,我们只需要将这个驱动放进项目中,通过这个驱动,我们就可以用Java连接数据库,进行数据库的管理操作。
了解:JDBC与ODBC的区别
二者皆可以实现对数据库的操作(连接、增删改查、建库建表)。
l JDBC是SUN开发的java连接数据库的标准
l ODBC是微软开发的,C语言的
1、准备工作
1.0 数据操作步骤
l 注册驱动(只做一次)
l 建立数据库连接
l 创建执行SQL的语句(Statement)
l 执行SQL语句
----如果是查询,需要处理执行的结果(如:接收查询数据)
l 释放资源(千万不要漏了)
1.1 创建java工程
项目名的命名规范:项目名全部小写。创建一个java工程:jdbcproject。
1.2 导入jar包
使用JDBC操作数据库,需要导入JDBC的驱动包:mysql-connector-java-5.1.39.jar。
在项目下面创建一个文件夹:lib,将驱动包复制到lib下面,并将jar包加载到项目中,如下图所示:
l 新建lib文件夹:
l 将jar包复制到lib文件夹下面:
l 选中jar包,单击右键,在弹出的窗口中选择“Add to Build Path” ,将jar包加载到项目中:
这时,我们可以在项目的引用包中看到我们引用的jar包:
2、JDBC连接数据库
经过上面的准备工作,我们就可以开始使用Java连接数据库了。
2.1 加载JDBC驱动
在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机),这通过java.lang.Class类的静态方法forName(String className)实现。
| try { // 加载MySql的驱动类 Class.forName("com.mysql.jdbc.Driver"); } catch (ClassNotFoundExceptione) { System.out.println("找不到驱动程序类,加载驱动失败!"); e.printStackTrace(); } |
成功加载后,会将Driver类的实例注册到DriverManager类中。
加载驱动时,如果我们项目中没有导入驱动包或者驱动的名字不对,会出现驱动加载失败的异常。异常信息:
2.2 提供JDBC连接的参数
连接数据库时,需要下面几个参数:
| url=jdbc:mysql://localhost:3306/database_name username=root password=1111
//这个可以解决中文乱码,在最后面可以设置编码,这里设的是utf-8 url = "jdbc:mysql://localhost:3306/yunlian??autoReconnect=true&autoReconnectForPools=true&useUnicode=true&characterEncoding=utf-8"; |
其中,username和password是连接数据库的用户名和密码,一般默认的用户名是root,密码是安装MySQL时的密码。url是连接数据库的地址。
当我们访问的是本机的数据库的时候,url的值也可以为“jdbc:mysql:///database_name”
2.3 创建数据库的连接
通过DriverManager类创建数据库连接对象Connection。DriverManager类作用于Java程序和JDBC驱动程序之间,用于检查所加载的驱动程序是否可以建立连接,然后通过它的getConnection方法,根据数据库的URL、用户名和密码,创建一个JDBC Connection 对象。
| try { //试图建立到给定数据库 URL 的连接 Connection con = DriverManager.getConnection(url,username, password); } catch (SQLExceptione) { System.out.println("数据库连接失败!"); e.printStackTrace(); } |
上面需要导入的包都是java.sql的包,如下所示:
| import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; |
在连接数据库时,如果数据库不存在,或者用户名、密码错误,会出现连接数据库失败的异常
用户名或者密码错误:
当我们的url中的数据库不存在的时候:
当URL中的IP或者主机连不上的时候,就会出现连接超时的异常:
当数据库端口号写错的时候,会出现连接被拒绝:
3、数据库操作
数据库操作分为更新和查询两种操作。
我们想要执行SQL语句,就必须要创建一个java.sql.Statement对象,Statement对象可以将SQL语句发送到数据库,并返回一个执行结果(如:添加数据时会返回数据库的影响行数)。
Statement实例分为以下3种类型:
l 执行静态SQL语句。通常通过Statement实例实现
l 执行动态SQL语句。通常通过PreparedStatement实例实现
l 执行数据库存储过程。通常通过CallableStatement实例实现(Oracle会讲)
3.0 Statement与PreparedStatement
Statement与PreparedStatement两者都可以把SQL语句从Java程序发送到指定数据库,并执行SQL语句,但是他们也具有如下区别:
l Statement会使数据库频繁编译SQL,可能造成数据库缓冲区溢出;
l PreparedStatement会形成预编译的过程,对于多次重复执行的语句,PreparedStatement的效率要高一些,而且适合批处理数据(批量添加);
l 最重要的是,PreparedStatement能有效防止危险自负的注入,即SQL注入问题。
根据比较结果可知,我们需要选用PreparedStatement更好、更快速、更安全。因此,在以后的JDBC操作中,建议使用PreparedStatement。
Statement接口提供了两种常用的执行SQL语句的方法:executeQuery 、executeUpdate。executeUpdate一般用于添加、删除、修改数据;executeQuery一般用于查询数据。
PreparedStatement接口继承自Statement。PreparedStatement在sql语句中通过使用占位符?来代替常量字段值,setXXX方法来填充字段值,取代掉占位符,形成完整的可执行的sql语句。
3.1 添加数据
l 静态SQL添加
| // connection.createStatement(): // 创建一个 Statement对象来将 SQL 语句发送到数据库。 statement = connection.createStatement(); // executeUpdate(String sql):执行给定 SQL语句,该语句可能为 INSERT、UPDATE或 // DELETE 语句,或者不返回任何内容的 SQL语句(如 SQL DDL语句)。 // 添加数据 String sql = "insert into test(id,username,birthday) values('15','张三','1999-09-09')"; int rows = statement.executeUpdate(sql);//返回的结果是受影响的行数 System.out.println(rows+"行"); |
l 动态SQL添加
| String sql = "insert into user(username,password) values(?,?)"; ps = connection.prepareStatement(sql); // //给占位符赋值 // //setNString(int parameterIndex, String value) // //将指定参数设置为给定 String对象。 // //位置编号从 1开始,不是从零开始 ps.setString(1, "王五");//setString表示的是该位置的参数需要字符串,对应数据库字段类型 ps.setString(2, "我是密码"); // //执行SQL int rows = ps.executeUpdate(); System.out.println(rows+"行"); |
3.2 修改数据
语法规则与添加类似
3.3 删除数据
语法规则与添加类似
3.4 批量处理数据
一次性执行多条SQL语句(比如:一次下单购买多个商品)。
执行批量添加数据时,务必要将提交方式设置为手动提交。
con.setAutoCommit(false);//将提交方式设置为手动提交
在获取到连接后,获取PreparedStatement对象之前,需要将提交方式设置为手动提交。
在循环中,可以使用ps.addBatch();//将给定的 SQL命令添加到此Statement对象的当前命令列表中。
循环结束后,使用ps.executeBatch(),可以将一批SQL命令提交给数据库,但是该方法之后必须要使用con.commit(),该命令是命令数据库新更改的数据成为持久化的数据。
| @Test public void testAddBatch(){ Connection con = BaseDao.getConn(); //批量添加数据 PreparedStatement ps = null; try { con.setAutoCommit(false);//将提交方式设置为手动提交 String sql = "insert into test(id,name,password) values(?,?,?)"; ps = con.prepareStatement(sql); long start = System.currentTimeMillis();//获取当前系统时间的毫秒数 for (inti = 0; i < 3000;i++) { ps.setInt(1, (i+1)); ps.setString(2, "用户"+i); ps.setString(3, MD5Util.GetMD5Code("密码"+i)); ps.addBatch();//将给定的 SQL命令添加到此 Statement对象的当前命令列表中。 } System.out.println("数据循环耗时:"+(System.currentTimeMillis()-start)+"ms"); start = System.currentTimeMillis();//获取当前系统时间的毫秒数 //将一批命令提交给数据库来执行,如果全部命令执行成功,则返回更新计数组成的数组 ps.executeBatch(); con.commit();//提交 System.out.println("数据执行SQL耗时:"+(System.currentTimeMillis()-start)+"ms"); // System.out.println(rows); } catch (Exceptione) { e.printStackTrace(); }finally { BaseDao.close(con, ps, null); } } |
采用批量处理数据的优点:
减少访问数据库的次数,大大提高了批量SQL执行的效率。
3.5 动态SQL中LIKE的使用
在使用动态SQL为like赋值的时候,like 直接使用?即可。PreparedStatement对象为占位符赋值的时候,我们需要把百分号 % 拼接进去即可。
案例:
String sql = “select* from user where username like ?”;
ps.setString(1,”%”+参数值+”%”);
4、释放资源
据库连接(Connection)是非常稀有的资源,用完后必须马上释放,如果Connection不能及时正确的关闭将导致系统宕机。Connection的使用原则是尽量晚创建,尽量早的释放。
5、小结
l 连接数据库时用到的三个类
l 静态SQL与动态SQL的区别
l 熟练使用动态SQL实现添加、修改、删除数据的功能
l 熟练使用批量处理数据
mybatis中的#{}和${}区别
1. #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id".
2. $将传入的数据直接显示生成在sql中。如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为order by id.
3. #方式能够很大程度防止sql注入。
4.$方式无法防止Sql注入。
5.$方式一般用于传入数据库对象,例如传入表名.
6.一般能用#的就别用$.
MyBatis排序时使用order by 动态参数时需要注意,用$而不是#
字符串替换
默认情况下,使用#{}格式的语法会导致MyBatis创建预处理语句属性并以它为背景设置安全的值(比如?)。这样做很安全,很迅速也是首选做法,有时你只是想直接在SQL语句中插入一个不改变的字符串。比如,像ORDER BY,你可以这样来使用:
ORDER BY ${columnName}
这里MyBatis不会修改或转义字符串。
重要:接受从用户输出的内容并提供给语句中不变的字符串,这样做是不安全的。这会导致潜在的SQL注入攻击,因此你不应该允许用户输入这些字段,或者通常自行转义并检查。
mybatis本身的说明:
![]()
![]()
String Substitution
By default, using the #{} syntax will cause MyBatis to generate PreparedStatement properties and set the values safely against the PreparedStatement parameters (e.g. ?). While this is safer, faster and almost always preferred, sometimes you just want to directly inject a string unmodified into the SQL Statement. For example, for ORDER BY, you might use something like this:
ORDER BY ${columnName}
Here MyBatis won't modify or escape the string.
NOTE It's not safe to accept input from a user and supply it to a statement unmodified in this way. This leads to potential SQL Injection attacks and therefore you should either disallow user input in these fields, or always perform your own escapes and checks.![]()
![]()
从上文可以看出:
1. 使用#{}格式的语法在mybatis中使用Preparement语句来安全的设置值,执行sql类似下面的:
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1,id);这样做的好处是:更安全,更迅速,通常也是首选做法。
而且#{}格式的sql能够预编译,能再内存中保存sql语法,不用重新组装sql语法。
2. 不过有时你只是想直接在 SQL 语句中插入一个不改变的字符串。比如,像 ORDER BY,你可以这样来使用:
ORDER BY ${columnName}{columnName}此时MyBatis 不会修改或转义字符串。
这种方式类似于:
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery(sql);这种方式的缺点是: 以这种方式接受从用户输出的内容并提供给语句中不变的字符串是不安全的,会导致潜在的 SQL 注入攻击,因此要么不允许用户输入这些字段,要么自行转义并检验。
HTTP协议使用流程
首先是域名解析。
第一步,假设我们用的chrom浏览器。
1.chrom会搜索自身的dns缓存。
2.搜索操作系统自身的dns缓存
这个缓存时间大概是一分钟,如果有缓存,那就看缓存有没有过期,如果过期了,那这个过程就结束了。
如何看chrom有没有缓存呢?
我们打开chrom浏览器,输入chrome://net-internals/#dns

这里就可以查看你曾经浏览过的网站的dns记录。
如果浏览器没有找到缓存或缓存已经失效,那么chrom会搜索操作系统自身的一个dns缓存,如果找到,也没有过期,那就会停止搜索,然后解析也到此结束。
3.如果操作系统也没有找到dns缓存,chrom就会尝试读取本地的host文件,

4.如果在host里面也没有找到对应的配置项,浏览器就会发起一个dns的系统调用,就会向本地主控的dns服务器,一般来说是你的宽带运营商提供的, 发起一个域名解析请求。
运营商的域名解析服务器一般会:(以www.imooc.com为例)
1)查找自身的缓存,找到对应的条目,如果说也没有过期,那么就解析成功了。
2)如果没有找到这个条目,运营商的dns服务器会代替我们的浏览器发起一个迭代的dns解析的请求。
它首先会去找根域的dns IP地址,询问imooc.com的域名地址,根域发现这是一个顶级域(com域)的域名,于是就回复运营商的服务器说,我只知道com域的顶级域的IP地址。
然后运营商拿到了com域的顶级域的IP地址,然后就去问它,com域回复说,他只知道imooc.com的dns服务器的地址。
随后运营商的主控dns服务器就找到imooc.com这个域的dns服务器,这个一般是域名的注册商提供的,询问imooc.com的域名地址,imooc.com服务器查找到之后,将此发送给运营商的服务器。
运营商服务器把记过返回给操作系统内核,同时也缓存在了自己的缓存区(这个缓存可能会失效,根据它的时间长短)
操作系统的内核又把这个Ip地址返回给浏览器。
最终浏览器拿到了www.imooc.com对应的IP 地址。
5.浏览器获得域名对应的IP地址后,就要发起TCP“三次握手”
浏览器就会以一个随机端口,向web服务器(比如nginx 80端口)发起一个tcp的的链接请求。
这个TCP连接请求就会经过层层的路由设备到达服务器端以后,进入到网卡,然后进入到内核的TCP/IP协议栈,还有可能要经过防火墙的过滤,最终到了web 服务端,最终建立了tcp/ip的连接。
这三次握手都做了什么呢?
客户端对服务器说“你能听到我说话么?咱俩聊会呗”
服务器对客户端说“我能听到你说话。咱俩聊会”
然后客户端再对服务器说“好的,开始聊天吧!”
6.TCP/IP连接建立起来后,浏览器就可以向服务器发送HTTP请求了,比如说,用HTTP的get方法请求一个根域里的一个域名,协议可以采用HTTP 1.0的一个协议。
7.服务器端接受到了这个请求,根据路径参数,经过后端的一些处理之后,把处理后的一个结果的数据返回给浏览器,如果是慕课网的页面,就会把完整的HTML页面代码返回给浏览器。
8.浏览器拿到了完整的HTML页面代码。在解析和渲染这个页面的时候,里面的JS,CSS ,图片等静态资源,他们同样也是一个个HTTP请求,都需要经过上面主要的七个步骤。
9.浏览器根据拿到的资源对页面进行渲染,最终把页面呈现给用户。
Spring为数据存取提供了一致的框架,不论是使用JDBC或O/R mapping产品(如Hibernate)。
总结:
1.低侵入式设计,代码污染极低
2.独立于各种应用服务器,基于Spring框架的应用,可以真正实现Write Once,Run Anywhere的承诺
3.Spring的DI机制降低了业务对象替换的复杂性,提高了组件之间的解耦
4.Spring的AOP支持允许将一些通用任务如安全、事务、日志等进行集中式管理,从而提供了更好的复用
5.Spring的ORM和DAO提供了与第三方持久层框架的良好整合,并简化了底层的数据库访问
6.Spring并不强制应用完全依赖于Spring,开发者可自由选用Spring框架的部分或全部
Struts2 知识点梳理
一、Struts2简介
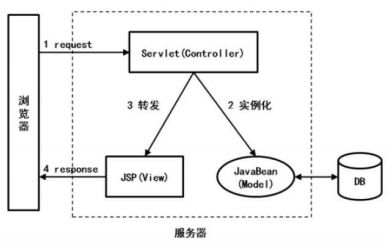
1.概念:轻量级的MVC框架,主要解决了请求分发的问题,重心在控制层和表现层。低侵入性,与业务代码的耦合度很低。Struts2实现了MVC,并提供了一系列API,采用模式化方式简化业务开发过程。
2.与Servlet对比
优点:业务代码解耦,提高开发效率
缺点:执行效率偏低,需要使用反射、解析XML等技术手段,结构复杂
3.不同框架实现MVC的方式
Servlet:
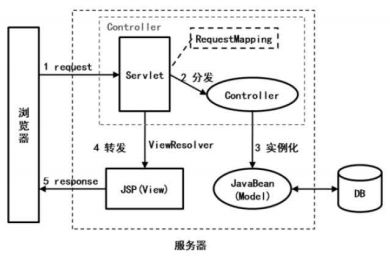
Spring:
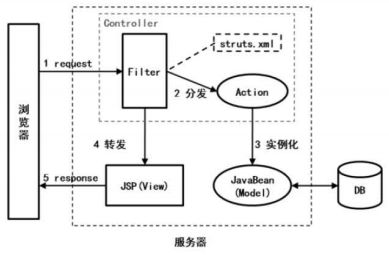
Struts2:
二、Struts2使用
1.使用步骤
导入Struts2核心jar包
在web.xml配置前端控制器filter
![]()
Struts2
org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter
Struts2
/*
![]()
创建struts.xml(格式可以参考核心包根路径下的DTD文件,struts-default.xml)
编写控制器Action
- 方法是public的
- 返回值为String类型(返回值与struts.xml->action->result的name属性匹配,即根据此返回值找到对应result)
- 参数列表为空
创建JSP页面
配置struts.xml
![]()
/hello.jsp
![]()
三、参数传递
1.Action从页面取值
a)基本属性注入(页面,Action)

b)域模型注入(页面,Action)

2.页面从Action取值
a)使用EL表达式

b)OGNL
四、OGNL
1.概念:Object Graph Navigation Language,是一门功能强大的表达式语言,类似于EL。Strut2默认采用OGNL表达式访问Action的数据,实际上是通过ValueStack对象来访问Action。
2.用法:在Struts2中,OGNL表达式要结合Struts2标签来访问数据
EL:${user.userName} <==> OGNL:
*a)访问基本属性
*b)访问实体对象
c)访问数组/集合
d)访问Map
e)运算
f)调用方法
g)创建集合
h)创建Map
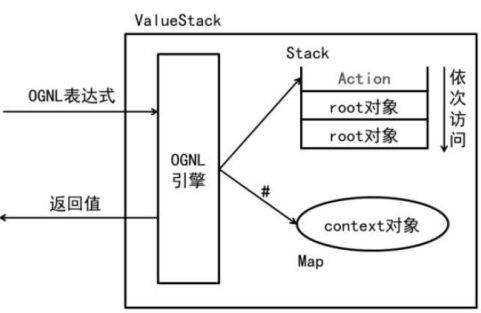
五、ValueStack
1.概念:是Struts2中,Action向页面传递数据的媒介,封装了Action的数据,并允许JSP通过OGNL来对其访问
2.原理
3.访问ValueStack
a)通过
b)输出栈顶:
c)访问Context对象:
- OGNL表达式以"#"开头
- 以key来访问context对象的值,即"#key"得到context中某属性值
d)迭代集合
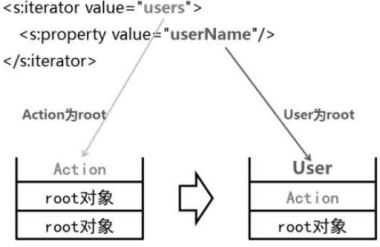

e)按数字迭代
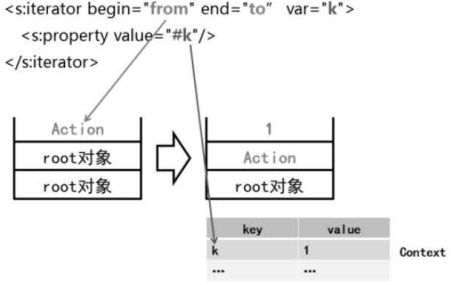

4.ValueStack栈顶的变化
- 默认情况下栈顶为Action
- 循环过程中,栈顶为循环变量(集合迭代时,循环变量是集合中的对象,即栈顶为实体对象,可以以实体对象为root来写OGNL表达式;数字迭代时,循环变量是数字,不能以数字为实体对象,需要通过var声明变量名,以"#变量名"来引用,此情况下,是从context对象中取出值)
- 循环结束后,栈顶变回Action
5.EL表达式访问ValueStack
a)EL也是从ValueStack中取的值
b)EL默认的取值范围是page,request,session,application
c)Struts2重写的request的getAttribute方法,先试图从原始request中取值,如果没取到再从ValueStack中取值
六、Action基本原理
1.6大核心组件

FC:前端控制器,负责统一的分发请求
Action:业务控制器,负责处理某一类业务
ValueStack:Action与JSP数据交互的媒介
Interceptor:拦截器,负责扩展Action,处理Action的共通事务
Result:负责输出的组件
Tags:标签,负责显示数据、生成框体
2.获取Session的方式
a)ActionContext
- ActionContext.getContext().getSesion(),返回Map
b)ServletActionContext
- ServletActionContext.getRequest().getSession(),返回HttpSession
c)SessionAware(推荐使用)
- 让Action实现SessionAware接口
- 实现setSession(Map
- 定义成员变量,接收注入进来的Session对象
七、Result原理
1.介绍:用于做输出的组件,用于向页面输出一些内容,转发、重定向可以理解为特殊方式的输出。每一个Result实际上是一个类,这些类都实现了共同的接口Result。Struts2预置了10种类型的Result,定义在strtus-default.xml
2.Result类型
a)dispatcher:用于转发的result,可以将请求转发给JSP,这种类型的Result对应的类为ServletDispacherResult,通过default="true"指定该Result为Struts2默认的Result类型。
b)stream:用于向页面输出二进制数据,此种类型的Result可以将二进制数据输出到请求发起端,对应类为StreamResult
codeStream
c)redirectAction:用于将请求重定向给另外一个Action,对应类为ServletActionRedirectResult
![]()
/命名空间
action名
![]()
d)json:用于向页面输出json格式的数据,可以将json字符串输出到请求发起端。对应类为JSONResult
![]()
属性名
属性名1,属性名2...
![]()
json需要导包,修改package继承关系为json-default
八、UI标签
1.表单
2.文本框
3.布尔框
4.单选框
5.多选框
6.下拉选
九、拦截器
1.用途:拦截器适合封装一些通用处理,便于重复利用。例如请求参数传递给Action属性,日志的记录,权限检查,事务处理等。拦截器是通过配置方式调用,因此使用方法比较灵活,便于维护和扩展。
2.使用步骤
创建拦截器组件(创建一个类,实现Interceptor接口,并实现intercept方法;也可以继承MethodFilterInterceptor,这种方式可以使action中某个方法不进行拦截)
public String intercept(ActionInvocation invocation){
//拦截器--前部分处理
invocation.invoke();
//拦截器--后续处理
}
注册拦截器
引用拦截器(哪个Action希望被拦截器扩展,需要在此action配置下,引用拦截器)
![]()
![]()
3.拦截器栈
4.FileUpload拦截器
a)原理:首先FileUpload拦截器将表单中提交的文件,以临时文件的形式保存到服务器临时路径下。之后FileUpload拦截器将该临时文件对象注入给Action,Action自主处理该临时文件。最后FileUpload拦截器删除临时文件。
b)使用步骤
导包 commons-io.jar
Action:定义File类型属性(如some),接受拦截器注入的临时文件对象。若想要获取原始文件名,要定义String类型属性,属性名为File类型属性+FileName(如someFileName)
表单设置:method="post", enctype="multipart/form-data"
c)设置限制(Struts2文件上传默认最大值为2097152B,即2M)
在struts.xml中重置默认限制值
Hibernate
简介
Hibernate是一个开源的对象关系映射(ORM)框架。对JDBC进行了非常轻量级的对象封装。
将对象和数据库表建立映射关系,Hibernate框架使用在数据持久化层(dao)。
ORM:对象关系映射(英语:Object Relational Mapping)
采用映射元数据(配置文件)来描述对象-关系的映射细节。ORM框架通过配置文件将实体对象和数据库表对应起来。
第一个Hibernate小例子
前提准备:导入jar包
需要的jar包 hibernate路径下下lib/required的所有jar包和jpa目录下的jar包
mysql驱动jar包
第一步:创建实体类
Hibernate要求实体类必须提供一个不带参数的默认构造方法。因为程序运行时,Hibernate会运用java的反射机制,创建实体类的实例。
public class User {
private int id;
private String name;
private String password;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
第二步:创建对应的数据库表 CREATE DATABASE hibernate; USE hibernate; CREATE TABLE USER( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(50), password VARCHAR(50) );
第三步:创建Hibernate的配置文件,放在src目录下,文件名为hibernate.cfg.xml
com.mysql.jdbc.Driver //指定数据库的驱动程序
root //数据库的用户名
123456 //数据库的密码
jdbc:mysql://localhost:3306/hibernate //连接数据库的url
true //为true时会在控制台输出sql语句,有利于跟踪hibernate的状态
true //会格式化输出sql语句
update
true //自动提交事务
第四步:创建对象-关系映射文件
该文件应该和实体类在同一目录下。命名规则为 实体类名.hbm.xml 例如User.hbm.xml
//根元素
//指定实体类和对应的数据表
//元素设定类中的id和表的主键id的映射
元素指定对象标识符生成器,负责生成唯一id。以后会详细讲
第五步:调用HibernateAPI操作数据库
public class Demo {
@Test
public void test() {
//读取配置文件
Configuration conf=new Configuration().configure();
//根据配置创建factory
SessionFactory sessionfactory=conf.buildSessionFactory();
//获得操作数据库的session对象
Session session=sessionfactory.openSession();
//创建对象
User u=new User();
u.setName("张三");
u.setPassword("123456");
//将对象保存到数据库
session.save(u);
//关闭资源
session.close();
sessionfactory.close();
}
}通过上面的小例子,我们大致了解了使用Hibernate的流程,接下来让我们详解Hibernate。
详解Hibernate配置文件
Hibernate从其配置文件中读取和数据库连接有关的信息。Hibernate配置文件有两种形式,XML格式或者java属性文件(properties)格式。
(一)java属性文件的格式创建hibernate的配置文件,默认文件名为hibernate.properties,为键值对的形式,放在src目录下:例如
hibernate.dialect=org.hibernate.dialect.MySQLDialect
hibernate.connection.driver_class=com.mysql.jdbc.Driver
hibernate.connection.url=jdbv:mysql://localhost:3306/hibernate
hibernate.connection.username=root
hibernate.connection.password=123456
hibernate.show_sql=true
hibernate.dialect:指定数据库使用的sql方言。可以根据数据库的不同生成不同的方言,底层是通过调用一个一个类实现的。
hibernate.connection.driver_class:指定数据库的驱动程序
hibernate.connection.url:指定连接数据库的url
hibernate.connection.username:指定连接数据库的用户名
hibernate.connection.password:指定连接数据库的密码
hibernate.show_sql:如果为true,可以在控制台打印sql语句
hbm2ddl.auto:生成表结构的策略配置,配置这个可以通过映射文件和实体类自动生成表结构
有四个值:
update(最常用的取值):如果当前数据库不存在对应的数据表,那么自动创建数据表
如果存在对应的数据表,并且表结构和实体类属性一致,那么不做任何修改
如果存在对应的数据表,但是表结构和实体类属性不一致,那么会新创建与实体类属性对应的列,其他列不变
create(很少使用):无论是否存在对应的数据表,每次启动Hibernate都会重新创建对应的数据表,以前的数据会丢失
create-drop(极少使用):无论是否存在对应的数据表,每次启动Hibernate都会重新创建对应的数据表,每次运行结束删除数据表
validate(很少使用):只校验表结构是否和我们的实体类属性相同,不同就抛异常
(二)使用xml格式的配置文件,默认文件名为hibernate.cfg.xml
com.mysql.jdbc.Driver
root
123456
jdbc:mysql://localhost:3306/hibernate
true
true
update
true
//引入映射文件
两种方式的区别
如果Hibernate的配置文件为java属性文件,那么必须通过代码来声明需要加载的映射文件
通过Configuration的addClass(实体类名.class)来加载。
配置文件为xml文件时,可以通过元素来指定需要加载的映射文件。
当通过Configuration的默认构造方法创建实例时,会默认查找hibernate.properties文件,如果找到就将配置信息加载到内存中。
默认情况下,hibernate不会加载hibernate.cfg.xml文件,必须通过Configuration的configure()方法来显式加载hibernate.cfg.xml文件
Hibernate中持久化类编写规范
-必须提供无参数的默认构造方法。因为程序运行时,Hibernate会运用java的反射机制,创建实体类的实例。
-所有属性必须提供public访问控制符的set get方法
-属性应尽量使用基本数据类型的包装类型(如Integer)
基本数据类型无法表达null值,所有基本数据类型的默认值都不是null,这样就有很大的缺陷。
例如有一个score属性,表示学生分数,如果为0,那么是表示该学生未参加考试还是说该学生成绩为0呢?
这时候如果用包装类型,就可以使用null来表示空值,学生未参加考试等等。
-不要用final修饰实体(将无法生成代理对象进行优化)
对象标识符
在关系数据库中,通过主键来识别记录并保证记录的唯一性。
主键的要求:不允许为null,不能重复,不能改变
自然主键:在业务中,某个属性符合主键的三个要求,那么该属性可以作为主键。比如人的身份证就可以当作主键
代理主键:增加一个不具备任何意义的字段,通常为ID,来作为主键
在java中,按照内存地址不同区分不同的对象。
在Hibernate中通过对象标识符(OID)来维持java对象和数据库表中对应的记录。
与表的代理主键对应,OID也是整数类型,为了保证OID的唯一性和不可变性,通常由Hibernate或者底层数据库库给OID赋值。
详解对象-关系映射文件
Hiernate采用XML格式的文件来指定对象和关系数据之间的映射。Hibernate通过这个文件来生成各种sql语句。
命名规则为 实体类名.hbm.xml 应该和实体类放在同一目录下。
Hibernate API详解
Configuration类
Configuration类:用来加载默认文件路径下的配置文件(hibernate.properties)。
调用configure()方法会加载默认文件路径下的xml格式的配置文件(hibernate.cfg.xml)推荐使用。
如果配置文件在不默认文件路径下或者配置文件名不符合默认规则
可以使用
new Configuration().configure(file) 加载指定文件
new Configuration().configure(path) 加载指定路径下的文件
如果使用properties格式的配置文件,可以使用addClass(实体类名.class)方法可以加载映射文件。
SessionFactory对象
SessionFactory对象:
SessionFactory代表数据库存储源。根据Hibernate配置文件创建对应的数据库存储源。
SessionFactory对象创建后,和Configuration对象再无关联。修改Configuration包含的配置文件信息,不会对SessionFactory有任何影响。
获取SessionFactory对象:new Configuration().configure().buildSessionFactory();
对象的缓存很大,就称为重量级对象。SessionFactory存放了Hibernate配置信息,映射元数据信息等。是重量级对象。
Session对象
Session对象:
代表程序和数据库的会话。Session提供了操作数据库的各种方法。是轻量级对象。
获取Session对象
factory.openSession(): 获取新的Session实例。
factory.getCurrentSession():采用该方法创建的Session会取出当前线程中的Session,底层使用ThreadLocal进行存取
save()方法:把Java对象保存到数据库中。
Transaction ts=session.beginTransaction();
User u=new User();
u.setName("赵六");
u.setPassword("123456");
//将对象保存到数据库
session.save(u);
ts.commit();
update()方法:更新数据库的方法
Transaction ts=session.beginTransaction();
//先查出要修改的对象,根据主键值
User user=session.get(User.class, 1);
user.setName("jery");
//将对象更新到数据库,根据OID
session.update(user);
ts.commit();
delete()方法:删除方法
底层根据OID进行删除。有两种方式
(1)
Transaction ts=session.beginTransaction();
User user=session.get(User.class, 1);
//删除指定对象
session.delete(user);
ts.commit();
(2)
Transaction ts=session.beginTransaction();
User user=new User();
user.setId(2);
session.delete(user);
ts.commit();
load()或get()方法:从数据库查找指定对象
session.get(实体类名.class,OID);或session.load(实体类名.class,OID);
load()和get()的区别
我们使用get查询时发现控制台会立马打出查询语句。
使用load查询时控制台不会打印查询语句。
get方法被调用时立刻发送sql语句到数据库进行查询。
load方法被调用时并没有查询数据库,当我们需要使用查询的对象时,才去查询,所以当我们打印对象时,才会在控制台打印sql语句。
get()的原理
程序调用get方法,Hibernate发送sql语句到数据库
数据库返回结果,Hibernate将结果封装成对象,返回对象到程序。
load()的原理
程序调用load方法,Hibernate使用代理技术,创建一个代理对象,属性只有ID值。
然后返回代理对象给程序,我们使用对象时,代理对象调用Hibernate查询数据库,初始化其他属性。
load方法,返回一个代理对象,获取其属性时,会查询数据库,每次访问属性都会查询数据库么?
答:不是。代理对象中有一个标识是否被初始化的boolean类型变量,记录是否被初始化。
查询所有对象的方法
使用HQL语言(后面会详细介绍),HQL语言是面向对象的
Query query=session.createQuery("from User");
第二种方式
Criteria c=session.createCriteria(User.class);
List l=c.list();
第三种方式,使用原生sql语句进行查询
SQLQuery query=session.createSQLQuery("select * from user");
List l=query.list();
Transaction对象
封装了事务的操作。我们做增删改查等操作时,必须开启事务.
因为session是线程不安全的,这样主要是为了线程安全。保证数据的正确性。
开启事务: Transaction ts=session.beginTransaction();
提交事务:ts.commit();
回滚事务:ts.rollback();
当通过getCurrentSession获取当前线程绑定的Session时,事务关闭时,会自动把Session关闭并删除。
Query对象
封装HQL语句的对象。
返回一个对象的方法 query.uniqueResult();
分页相关
query.setFirstResult(index):从第几个取
query.setMaxResults(count):指定取几行记录MySQL基础
一、MySQL概述
1、什么是数据库 ?
答:数据的仓库,如:在ATM的示例中我们创建了一个 db 目录,称其为数据库
2、什么是 MySQL、Oracle、SQLite、Access、MS SQL Server等 ?
答:他们均是一个软件,都有两个主要的功能:
-
- a. 将数据保存到文件或内存
- b. 接收特定的命令,然后对文件进行相应的操作
3、什么是SQL ?
答:MySQL等软件可以接受命令,并做出相应的操作,由于命令中可以包含删除文件、获取文件内容等众多操作,对于编写的命令就是是SQL语句。
二、MySQL安装
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
想要使用MySQL来存储并操作数据,则需要做几件事情:
a. 安装MySQL服务端
b. 安装MySQL客户端
b. 【客户端】连接【服务端】
c. 【客户端】发送命令给【服务端MySQL】服务的接受命令并执行相应操作(增删改查等)
![]()
下载
http://dev.mysql.com/downloads/mysql/
安装
windows:
http://jingyan.baidu.com/article/f3ad7d0ffc061a09c3345bf0.html
linux:
yum install mysql-server
mac:
一直点下一步![]()
客户端连接
![]()
连接:
1、mysql管理人默认为root,没有设置密码则直接登录
mysql -h host -u root -p 不用输入密码按回车自动进入
2、如果想设置mysql密码
mysqladmin -u root password 123456
3、如果你的root现在有密码了(123456),那么修改密码为abcdef的命令是:
mysqladmin -u root -p password abcdef
退出:
QUIT 或者 Control+D![]()
三、数据库基础
分为两大部分:
1、数据库和表的创建;
2、数据库和表内容的操作
数据库操作-思路图

1、数据库和表的创建
(一)数据库的创建
1.1、显示数据库
1 SHOW DATABASES; 默认数据库:
mysql - 用户权限相关数据
test - 用于用户测试数据
information_schema - MySQL本身架构相关数据
1.2、创建数据库
# utf-8
CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
# gbk
CREATE DATABASE 数据库名称 DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;1.3、打开数据库
USE db_name;
注:每次使用数据库必须打开相应数据库显示当前使用的数据库中所有表:SHOW TABLES;
1.4、用户管理
用户设置:
![]()
创建用户
create user '用户名'@'IP地址' identified by '密码';
删除用户
drop user '用户名'@'IP地址';
修改用户
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';;
修改密码
set password for '用户名'@'IP地址' = Password('新密码')
PS:用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)![]()
用户权限设置:
show grants for '用户'@'IP地址' -- 查看权限
grant 权限 on 数据库.表 to '用户'@'IP地址' -- 授权
revoke 权限 on 数据库.表 from '用户'@'IP地址' -- 取消权限![]() 对于权限设置
对于权限设置
![]() 对于数据库名的解释
对于数据库名的解释
![]() 对于ip地址的访问
对于ip地址的访问
![]() 实际例子
实际例子
1.4、备份库和恢复库
备份库:
MySQL备份和还原,都是利用mysqldump、mysql和source命令来完成。
1.在Windows下MySQL的备份与还原
![]()
备份
1、开始菜单 | 运行 | cmd |利用“cd /Program Files/MySQL/MySQL Server 5.0/bin”命令进入bin文件夹
2、利用“mysqldump -u 用户名 -p databasename >exportfilename”导出数据库到文件,如mysqldump -u root -p voice>voice.sql,然后输入密码即可开始导出。
还原
1、进入MySQL Command Line Client,输入密码,进入到“mysql>”。
2、输入命令"show databases;",回车,看看有些什么数据库;建立你要还原的数据库,输入"create database voice;",回车。
3、切换到刚建立的数据库,输入"use voice;",回车;导入数据,输入"source voice.sql;",回车,开始导入,再次出现"mysql>"并且没有提示错误即还原成功。 ![]()
2、在linux下MySQL的备份与还原
![]()
2.1 备份(利用命令mysqldump进行备份)
[root@localhost mysql]# mysqldump -u root -p voice>voice.sql,输入密码即可。
2.2 还原
方法一:
[root@localhost ~]# mysql -u root -p 回车,输入密码,进入MySQL的控制台"mysql>",同1.2还原。
方法二:
[root@localhost mysql]# mysql -u root -p voice![]()
3、更多备份及还原命令
![]() 更多备份
更多备份
更多备份知识:
http://www.jb51.net/article/41570.htm
(二)数据表的创建
1.1、显示数据表
show tables;1.2、创建数据表
create table 表名(
列名 类型 是否可以为空,
列名 类型 是否可以为空
)ENGINE=InnoDB DEFAULT CHARSET=utf8
![]() 设置是否为空
设置是否为空
![]() 设置默认值
设置默认值
![]() 设置自增
设置自增
![]() 设置主键
设置主键
![]() 设置外键
设置外键
主键与外键关系(非常重要)
http://www.cnblogs.com/programmer-tlh/p/5782451.html
1.3删除表
drop table 表名1.4、清空表
delete from 表名
truncate table 表名1.5、基本数据类型
MySQL的数据类型大致分为:数值、时间和字符串
![]()
bit[(M)]
二进制位(101001),m表示二进制位的长度(1-64),默认m=1
tinyint[(m)] [unsigned] [zerofill]
小整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-128 ~ 127.
无符号:
0 ~ 255
特别的: MySQL中无布尔值,使用tinyint(1)构造。
int[(m)][unsigned][zerofill]
整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-2147483648 ~ 2147483647
无符号:
0 ~ 4294967295
特别的:整数类型中的m仅用于显示,对存储范围无限制。例如: int(5),当插入数据2时,select 时数据显示为: 00002
bigint[(m)][unsigned][zerofill]
大整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-9223372036854775808 ~ 9223372036854775807
无符号:
0 ~ 18446744073709551615
decimal[(m[,d])] [unsigned] [zerofill]
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
特别的:对于精确数值计算时需要用此类型
decaimal能够存储精确值的原因在于其内部按照字符串存储。
FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
无符号:
-3.402823466E+38 to -1.175494351E-38,
0
1.175494351E-38 to 3.402823466E+38
有符号:
0
1.175494351E-38 to 3.402823466E+38
**** 数值越大,越不准确 ****
DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
无符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
0
2.2250738585072014E-308 to 1.7976931348623157E+308
有符号:
0
2.2250738585072014E-308 to 1.7976931348623157E+308
**** 数值越大,越不准确 ****
char (m)
char数据类型用于表示固定长度的字符串,可以包含最多达255个字符。其中m代表字符串的长度。
PS: 即使数据小于m长度,也会占用m长度
varchar(m)
varchars数据类型用于变长的字符串,可以包含最多达255个字符。其中m代表该数据类型所允许保存的字符串的最大长度,只要长度小于该最大值的字符串都可以被保存在该数据类型中。
注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡
text
text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
mediumtext
A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters.
longtext
A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters.
enum
枚举类型,
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small');
set
集合类型
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
DATE
YYYY-MM-DD(1000-01-01/9999-12-31)
TIME
HH:MM:SS('-838:59:59'/'838:59:59')
YEAR
YYYY(1901/2155)
DATETIME
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y)
TIMESTAMP
YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)![]()
1.6、修改表(alter)
![]() 修改表
修改表
更多参考:
- http://www.runoob.com/mysql/mysql-data-types.html
1.7、数据表关系
关联映射:一对多/多对一
存在最普遍的映射关系,简单来讲就如球员与球队的关系; 一对多:从球队角度来说一个球队拥有多个球员 即为一对多
多对一:从球员角度来说多个球员属于一个球队 即为多对一
数据表间一对多关系如下图:

关联映射:一对一 一对一关系就如球队与球队所在地址之间的关系,一支球队仅有一个地址,而一个地址区也仅有一支球队。 数据表间一对一关系的表现有两种,一种是外键关联,一种是主键关联。图示如下:
一对一外键关联:

一对一主键关联:要求两个表的主键必须完全一致,通过两个表的主键建立关联关系

关联映射:多对多 多对多关系也很常见,例如学生与选修课之间的关系,一个学生可以选择多门选修课,而每个选修课又可以被多名学生选择。
数据库中的多对多关联关系一般需采用中间表的方式处理,将多对多转化为两个一对多

1.8、数据表之间的约束
约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。
MYSQL中,常用的几种约束:

===================================================
主键(PRIMARY KEY)是用于约束表中的一行,作为这一行的标识符,在一张表中通过主键就能准确定位到一行,因此主键十分重要。主键要求这一行的数据不能有重复且不能为空。
还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识
===================================================
默认值约束(DEFAULT)规定,当有DEFAULT约束的列,插入数据为空时该怎么办。
DEFAULT约束只会在使用INSERT语句(上一实验介绍过)时体现出来,INSERT语句中,如果被DEFAULT约束的位置没有值,那么这个位置将会被DEFAULT的值填充
===================================================
唯一约束(UNIQUE)比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
当INSERT语句新插入的数据和已有数据重复的时候,如果有UNIQUE约束,则INSERT失败.
===================================================
外键(FOREIGN KEY)既能确保数据完整性,也能表现表之间的关系。
一个表可以有多个外键,每个外键必须REFERENCES(参考)另一个表的主键,被外键约束的列,取值必须在它参考的列中有对应值。
在INSERT时,如果被外键约束的值没有在参考列中有对应,比如以下命令,参考列(department表的dpt_name)中没有dpt3,则INSERT失败
===================================================
非空约束(NOT NULL),听名字就能理解,被非空约束的列,在插入值时必须非空。
在MySQL中违反非空约束,不会报错,只会有警告.
![]() 例子
例子
2、数据库和表内容的操作(增、删、改、查)
1、增
insert into 表 (列名,列名...) values (值,值,值...)
insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...)
insert into 表 (列名,列名...) select (列名,列名...) from 表2、删
delete from 表
delete from 表 where id=1 and name='alex'3、改
update 表 set name = 'alex' where id>14、查
4.1、普通查询
select * from 表
select * from 表 where id > 1
select nid,name,gender as gg from 表 where id > 1![]() 更多选项查询
更多选项查询
4.2、数据排序(查询)
排序
select * from 表 order by 列 asc - 根据 “列” 从小到大排列
select * from 表 order by 列 desc - 根据 “列” 从大到小排列
select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序4.3、模糊查询
通配符(模糊查询)
select * from 表 where name like 'ale%' - ale开头的所有(多个字符串)
select * from 表 where name like 'ale_' - ale开头的所有(一个字符)4.4、聚集函数查询
![]() 聚集函数
聚集函数
4.5、分组查询
![]()
分组
select num from 表 group by num
select num,nid from 表 group by num,nid
select num,nid from 表 where nid > 10 group by num,nid order nid desc
select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid
select num from 表 group by num having max(id) > 10
特别的:group by 必须在where之后,order by之前![]()
4.6多表查询
![]()
a、连表
无对应关系则不显示
select A.num, A.name, B.name
from A,B
Where A.nid = B.nid
无对应关系则不显示
select A.num, A.name, B.name
from A inner join B
on A.nid = B.nid
A表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name
from A left join B
on A.nid = B.nid
B表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name
from A right join B
on A.nid = B.nid
b、组合
组合,自动处理重合
select nickname
from A
union
select name
from B
组合,不处理重合
select nickname
from A
union all
select name
from B![]()
Redis 总结精讲 看一篇成高手系统-4
本文围绕以下几点进行阐述
1、为什么使用redis
2、使用redis有什么缺点
3、单线程的redis为什么这么快
4、redis的数据类型,以及每种数据类型的使用场景
5、redis的过期策略以及内存淘汰机制
6、redis和数据库双写一致性问题
7、如何应对缓存穿透和缓存雪崩问题
8、如何解决redis的并发竞争问题
正文
1、为什么使用redis
分析:博主觉得在项目中使用redis,主要是从两个角度去考虑:性能和并发。当然,redis还具备可以做分布式锁等其他功能,但是如果只是为了分布式锁这些其他功能,完全还有其他中间件(如zookpeer等)代替,并不是非要使用redis。因此,这个问题主要从性能和并发两个角度去答。
回答:如下所示,分为两点
(一)性能
如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。
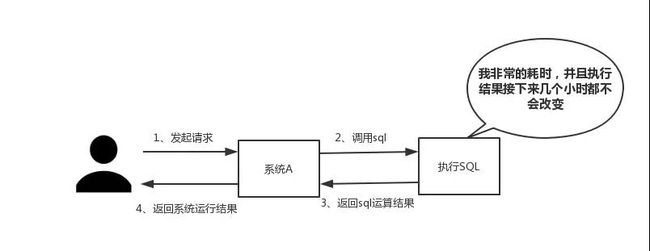
题外话:忽然想聊一下这个迅速响应的标准。其实根据交互效果的不同,这个响应时间没有固定标准。不过曾经有人这么告诉我:”在理想状态下,我们的页面跳转需要在瞬间解决,对于页内操作则需要在刹那间解决。另外,超过一弹指的耗时操作要有进度提示,并且可以随时中止或取消,这样才能给用户最好的体验。”
那么瞬间、刹那、一弹指具体是多少时间呢?
根据《摩诃僧祗律》记载
一刹那者为一念,二十念为一瞬,二十瞬为一弹指,二十弹指为一罗预,二十罗预为一须臾,一日一夜有三十须臾。
那么,经过周密的计算,一瞬间为0.36 秒,一刹那有 0.018 秒.一弹指长达 7.2 秒。
(二)并发
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问数据库。

2、使用redis有什么缺点
分析:大家用redis这么久,这个问题是必须要了解的,基本上使用redis都会碰到一些问题,常见的也就几个。
回答:主要是四个问题
(一)缓存和数据库双写一致性问题
(二)缓存雪崩问题
(三)缓存击穿问题
(四)缓存的并发竞争问题
这四个问题,我个人是觉得在项目中,比较常遇见的,具体解决方案,后文给出。
3、单线程的redis为什么这么快
分析:这个问题其实是对redis内部机制的一个考察。其实根据博主的面试经验,很多人其实都不知道redis是单线程工作模型。所以,这个问题还是应该要复习一下的。
回答:主要是以下三点
(一)纯内存操作
(二)单线程操作,避免了频繁的上下文切换
(三)采用了非阻塞I/O多路复用机制
题外话:我们现在要仔细的说一说I/O多路复用机制,因为这个说法实在是太通俗了,通俗到一般人都不懂是什么意思。博主打一个比方:小曲在S城开了一家快递店,负责同城快送服务。小曲因为资金限制,雇佣了一批快递员,然后小曲发现资金不够了,只够买一辆车送快递。
经营方式一
客户每送来一份快递,小曲就让一个快递员盯着,然后快递员开车去送快递。慢慢的小曲就发现了这种经营方式存在下述问题
-
几十个快递员基本上时间都花在了抢车上了,大部分快递员都处在闲置状态,谁抢到了车,谁就能去送快递
-
随着快递的增多,快递员也越来越多,小曲发现快递店里越来越挤,没办法雇佣新的快递员了
-
快递员之间的协调很花时间
综合上述缺点,小曲痛定思痛,提出了下面的经营方式
经营方式二
小曲只雇佣一个快递员。然后呢,客户送来的快递,小曲按送达地点标注好,然后依次放在一个地方。最后,那个快递员依次的去取快递,一次拿一个,然后开着车去送快递,送好了就回来拿下一个快递。
对比
上述两种经营方式对比,是不是明显觉得第二种,效率更高,更好呢。在上述比喻中:
-
每个快递员——————>每个线程
-
每个快递——————–>每个socket(I/O流)
-
快递的送达地点————–>socket的不同状态
-
客户送快递请求————–>来自客户端的请求
-
小曲的经营方式————–>服务端运行的代码
-
一辆车———————->CPU的核数
于是我们有如下结论
1、经营方式一就是传统的并发模型,每个I/O流(快递)都有一个新的线程(快递员)管理。
2、经营方式二就是I/O多路复用。只有单个线程(一个快递员),通过跟踪每个I/O流的状态(每个快递的送达地点),来管理多个I/O流。
下面类比到真实的redis线程模型,如图所示
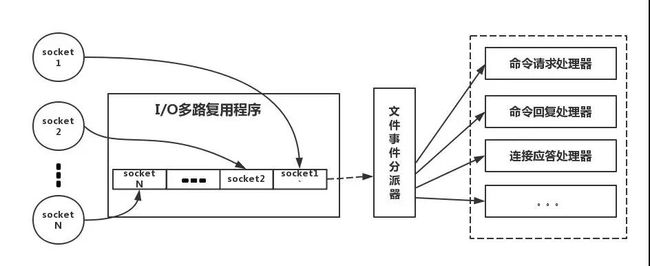
参照上图,简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
需要说明的是,这个I/O多路复用机制,redis还提供了select、epoll、evport、kqueue等多路复用函数库,大家可以自行去了解。
4、redis的数据类型,以及每种数据类型的使用场景
分析:是不是觉得这个问题很基础,其实我也这么觉得。然而根据面试经验发现,至少百分八十的人答不上这个问题。建议,在项目中用到后,再类比记忆,体会更深,不要硬记。基本上,一个合格的程序员,五种类型都会用到。
回答:一共五种
(一)String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。
(二)hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
(三)list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适---取行情信息。就也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
(四)set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
(五)sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。
5、redis的过期策略以及内存淘汰机制
分析:这个问题其实相当重要,到底redis有没用到家,这个问题就可以看出来。比如你redis只能存5G数据,可是你写了10G,那会删5G的数据。怎么删的,这个问题思考过么?还有,你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,有思考过原因么?
回答:
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置
# maxmemory-policy volatile-lru
该配置就是配内存淘汰策略的(什么,你没配过?好好反省一下自己)
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
6、redis和数据库双写一致性问题
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
7、如何应对缓存穿透和缓存雪崩问题
分析:这两个问题,说句实在话,一般中小型传统软件企业,很难碰到这个问题。如果有大并发的项目,流量有几百万左右。这两个问题一定要深刻考虑。
回答:如下所示
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
(一)利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
(二)采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
(三)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
(一)给缓存的失效时间,加上一个随机值,避免集体失效。
(二)使用互斥锁,但是该方案吞吐量明显下降了。
(三)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
-
I 从缓存A读数据库,有则直接返回
-
II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
-
III 更新线程同时更新缓存A和缓存B。
8、如何解决redis的并发竞争key问题
分析:这个问题大致就是,同时有多个子系统去set一个key。这个时候要注意什么呢?大家思考过么。需要说明一下,博主提前百度了一下,发现答案基本都是推荐用redis事务机制。博主不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
回答:如下所示
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA–>valueB–>valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通
三、基于Redis的Session共享实现(核心代码)
1)原理:写一个Session过滤器拦截每一次请求,在这里检查由Cookie生成的SessionID,进行创建或获取。核心是实现使用装饰类,实现Session在Redis中的存取操作。
2)此处存取方式为 sessionID+sessionKey作为Redis的key ==== sessionValue作为Redis的value,这样保存了每次存取都从Redis中操作,效率更高。
3)注意:序列化方式推荐使用Apache下Commons组件——SerializationUtils 或 org.springframework.util.SerializationUtils