哈希表(散列表)详解及代码实现
1.定义:
散列表(Hash table,也叫哈希表),是根据关键码值(Key, value)而直接进行访问的数据结构。也就是说,它通过吧关键码值映射到表中的一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
2.原理:
哈希表的原理非常简单:
若关键字为K,则其值存放在f(K)的位置。由此,不需要比较便可直接取得所查记录。称这个对应关系f为散列函数,按这个思想建立的表为散列表。
3.常用方法:
- 直接定址法。
- 除留余数法。
- 平法取中法。
- 数字分析法。
- 折叠法。
- 随机数法。
直接定址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,其中a和b为常数。
除留余数法:取关键值被某个不大于散列表长m的数p除后的所得的余数为散列地址。Hash(Key)= Key%P;
但是,不管是直接定址法还是除留余数法都会产生哈希冲突,即不同的Key值经过处理得到相同的值。
4.解决哈希冲突的方法:
1)闭散列方法(开放定址法):
他的核心思想是,把发生冲突的元素放到哈希表中的另外一个位置。
闭散列方法具体分为:线性探测和二次探测
a.线性探测:
思想:把发生冲突的元素从当前位置向后移,移到第一遇到的空位置。
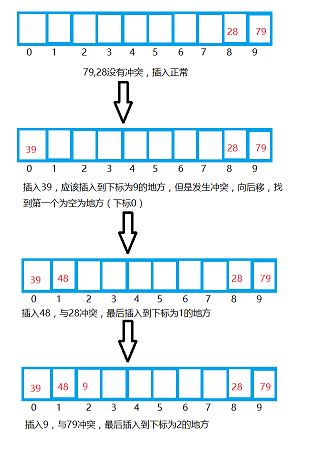
假设哈希表的长度为10,我们有5个数据分别为 79,28,39,48,9。用除留余数法插入到哈希表,具体过程如下:
插入的坐标=Key值 % 表长
79 % 10 = 9;
28 % 10 = 8;
39 % 10 = 9;
48 % 10 = 8;
9 & 10 = 9;
从计算的就结果可知, 79,39,9 ,插入的位置冲突。28,48插入的位置冲突。
b.二次探测
思想:
二次探测和线性探测差不多,只是发生冲突后后移的大小为后移次数的平方。
例如:假设移动次数为i。(还是上面的用例)

注意:
散列表的载荷因子定义为:a=填入表中的元素个数 / 散列表的长度。
由于表长是定值,a与"填入表中的元素个数"成正比,所以a越大,表明填入表中的元素越多,产生冲突的可能性越大。反之,a越小产生的冲突的可能性越小。
对于开放定址法,载荷因子是特别重要的因素,应严格控制在0.7--0.8.
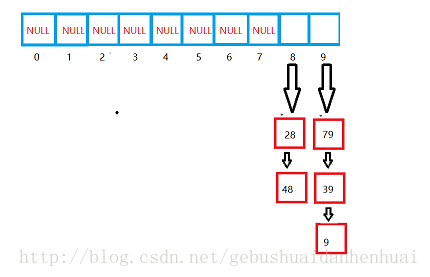
2)开散列法(开链法或拉链发):
思想:
把哈希表定义成指针数组,每次发生冲突,就把元素链到下标对应的下面。
线性探测法代码实现:
#include
#include
#include
#include
using namespace std;
//线性探测法
enum STATE
{
EMPTY,
EXIST,
DELETE,
};
template
struct __HashFunc
{
size_t operator()(const K& k)
{
return k;
}
};
//特化
template<>
struct __HashFunc
{
size_t operator()(const string& k)
{
return BKDHash(k.c_str());
}
static size_t BKDHash(const char* str)
{
unsigned int seed = 131;// 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash*seed + (*str++);
}
return(hash & 0x7FFFFFFF);
}
};
template
struct HashNode
{
pair _kv;
STATE _s;
HashNode()
:_s(EMPTY)
{}
};
template>
class HashTable
{
typedef HashNode Node;
public:
HashTable()
:_size(0)
{}
HashTable(size_t n)
:_size(0)
{
_tables.resize(n);
}
pair Insert(const pair& kv)
{
_CheckCapacity();
size_t index = _GetIndex(kv.first);
while (_tables[index]._s == EXIST)
{
//检查是否存在
if (_tables[index]._kv.first == kv.first)
return make_pair(&_tables[index], false);
++index;
if (index == _tables.size())
index = 0;
}
_tables[index]._kv = kv;
_tables[index]._s = EXIST;
++_size;
return make_pair(&_tables[index], true);
}
Node* Find(const K& key)
{
size_t index = _GetIndex (key);
while (_tables[index]._s != EMPTY)
{
if (_tables[index]._kv.first == key)
{
if (_tables[index]._s == EXIST)
return &_tables[index];
else
return NULL;
}
++index;
if (index == _tables.size())
index = 0;
}
return NULL;
}
bool Remove(const K& key)
{
Node* del = Find(key);
if (del != NULL)
{
del->_s = DELETE;
--_size;
return true;
}
return false;
}
void Print()
{
size_t size = _tables.size();
for (size_t i = 0; i < size; ++i)
{
if (_tables[i]._s == EXIST)
{
cout << _tables[i]._kv.first << "-- "<<_tables[i]._kv.second<<" ";
}
}
cout << endl;
}
V& operator[](const K& key)
{
pair ret = Insert(make_pair(key, V()));
return ((ret.first)->_kv).second;
}
protected:
size_t _GetIndex(const K& key)
{
HashFunc k;
return k(key) % _tables.size();
}
void Swap(HashTable ht)
{
swap(_size, ht._size);
_tables.swap(ht._tables);
}
void _CheckCapacity()
{
if (_tables.size() == 0)
{
_tables.resize(53);
}
else if (_size * 10 / _tables.size() == 7)
{
size_t newSize = _GetNextprime(_tables.size());
HashTable newHT(newSize);
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i]._s == EXIST)
{
newHT.Insert(_tables[i]._kv);
}
}
this->Swap(newHT);
}
}
size_t _GetNextprime(size_t n)
{
const int _PrimeSize = 28;//下面为一个素数表
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul,
786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (size_t i = 0; i< _PrimeSize; ++i)
{
if (n < _PrimeList[i])
return _PrimeList[i];//找到要找的下一个素数
}
assert(false);
}
protected:
vector _tables;
size_t _size;
};
void TestHash()
{
int a[] = { 89, 18, 49, 58, 9 };
HashTable ht;
for (size_t i = 0; i < sizeof(a) / sizeof(a[0]); ++i)
{
ht.Insert(make_pair(a[i], i));
}
ht.Insert(make_pair(10, 1));
ht.Insert(make_pair(11, 1));
ht.Insert(make_pair(12, 1));
ht.Insert(make_pair(13, 1));
ht.Insert(make_pair(14, 1));
ht.Print();
cout<> ht1;
ht1.Insert(make_pair("Left", "左边"));
ht1.Insert(make_pair("Left", "剩余"));
ht1.Print();
ht1["Left"] = "剩余";
ht1.Print();
}
//int main()
//{
// TestHash();
// system("pause");
// return 0;
//} 开链法代码实现:
#include
#include
using namespace std;
template
struct HashNode
{
pair _kv;
HashNode* _next;
HashNode(const pair& kv)
:_kv(kv)
, _next(NULL)
{}
};
template
struct _HashFunc
{
size_t operator()(const K& key)
{
return key;
}
};
//特化
template<>
struct _HashFunc
{
size_t operator()(const string& key)
{
return BKDRHash(key.c_str());
}
protected:
//字符串哈希处理算法
static size_t BKDRHash(const char* str)
{
unsigned int seed = 131;// 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash*seed + (*str++);
}
return(hash & 0x7FFFFFFF);
}
};
//声明
template
class HashTableBucket;
template
struct __HashTableIterator
{
typedef HashNode Node;
typedef __HashTableIterator< K, V, HashFunc, ValueTypePtr, ValueTypeRef> Self;
Node* _node;
HashTableBucket* _ht;
__HashTableIterator(Node* node, HashTableBucket* ht)
:_node(node)
, _ht(ht)
{}
ValueTypeRef operator*()
{
return _node->_kv;
}
ValueTypePtr operator->()
{
return &(operator*());
}
bool operator == (const Self& s)const
{
return _node == s._node;
}
bool operator !=(const Self& s)const
{
return _node != s._node;
}
Self& operator++()
{
_node = _Next(_node);
return *this;
}
protected:
Node* _Next(Node* node)
{
Node* next = node->_next;
if (next)
return next;
else
{
size_t index = _ht->_HashFunc(node->_kv.first) + 1;
for (; index < _ht->_tables.size(); ++index)
{
next = _ht->_tables[index];
if (next)
return next;
}
}
return NULL;
}
};
template>
class HashTableBucket
{
public:
typedef HashNode Node;
typedef __HashTableIterator*, pair&> Iterator;
friend Iterator;
public:
HashTableBucket()
:_size(0)
{}
HashTableBucket(const size_t n)
:_size(0)
{
_tables.resize(n);
}
~HashTableBucket()
{
_Clear();
_size = 0;
}
V& operator[](const K& key)
{
pair ret = Insert(make_pair(key, V()));
return ((ret.first)->_kv).second;
}
pair Insert(const pair& kv)
{
_Check();
size_t index = _HashFunc(kv.first);
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == kv.first)
{
return make_pair(cur, false);
}
cur = cur->_next;
}
//头插
Node* newNode = new Node(kv);
newNode->_next = _tables[index];
_tables[index] = newNode;
++_size;
return make_pair(_tables[index], true);
}
Node* Find(const K& key)
{
size_t index = _HashFunc(key);
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == key)
return cur;
cur = cur->_next;
}
return false;
}
bool Remove(const K& key)
{
size_t index = _HashFunc(key);
Node* cur = _tables[index];
Node* parent = NULL;
if (cur == NULL)
return false;
while (cur)
{
if (cur->_kv.first == key)
{
if (cur == _tables[index])
{
_tables[index] = cur->_next;
}
else
{
parent->_next = cur->_next;
}
delete cur;
cur = NULL;
--_size;
break;
}
parent = cur;
cur = cur->_next;
}
return false;
}
void Print()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
cout << cur->_kv.first << " ";
cur = cur->_next;
}
}
cout << endl;
}
Iterator Begin()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
if (cur)
return Iterator(cur, this);
}
return Iterator(NULL, this);
}
Iterator End()
{
return Iterator(NULL, this);
}
protected:
void _Check()
{
if (_tables.size() == 0 || _size / _tables.size() >= 1)
{
size_t newSize = _GetPrimenum(_tables.size());
HashTableBucket newTable(newSize);
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
newTable.Insert(make_pair(((cur->_kv).first), ((cur->_kv).second)));
cur = cur->_next;
}
}
_Swap(newTable);
}
}
void _Swap(HashTableBucket& ht)
{
swap(_size, ht._size);
_tables.swap(ht._tables);
}
size_t _HashFunc(const K& key)
{
HashFunc hf;
return hf(key) % _tables.size();
}
size_t _GetPrimenum(const size_t& sz)
{
const int Primesize = 28;
static const unsigned long Primenum[Primesize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul,
786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (int i = 0; i < Primesize; ++i)
{
if (Primenum[i] > sz)
{
return Primenum[i];
}
}
return sz;
}
void _Clear()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* del = cur;
cur = cur->_next;
delete del;
}
_tables[i] = NULL;
}
}
protected:
vector _tables;
size_t _size;
};
void TestHashTableBucket()
{
int a[] = { 89, 18, 49, 58, 9 };
HashTableBucket ht;
for (size_t i = 0; i < sizeof(a) / sizeof(a[0]); ++i)
{
ht.Insert(make_pair(a[i], 1));
}
ht.Insert(make_pair(10, 1));
ht.Insert(make_pair(53, 1));
ht.Insert(make_pair(54, 1));
ht.Insert(make_pair(55, 1));
ht.Insert(make_pair(56, 1));
ht.Insert(make_pair(106, 1));
ht.Insert(make_pair(212, 1));
ht.Print();
HashTableBucket>::Iterator it = ht.Begin();
while (it != ht.End())
{
cout << it->first << " ";
++it;
}
cout << endl;
ht.Remove(53);
ht.Remove(212);
ht.Remove(106);
ht.Remove(49);
ht.Print();
HashTableBucket> ht1;
ht1.Insert(make_pair("Left", "左边"));
ht1.Insert(make_pair("Left", "剩余"));
ht1["Left"] = "剩余";
HashTableBucket>::Iterator it1 = ht1.Begin();
while (it1 != ht1.End())
{
cout << (it1->first).c_str() << " ";
++it1;
}
cout << endl;
}
int main()
{
TestHashTableBucket();
system("pause");
return 0;
}