train_test_split,GridSearchCV,cross_val_score
一:交叉验证
交叉验证示意图:将数据分为训练数据、验证数据和测试数据。
训练数据和验证数据用于做交叉验证和调节参数。测试数据用于求指标。
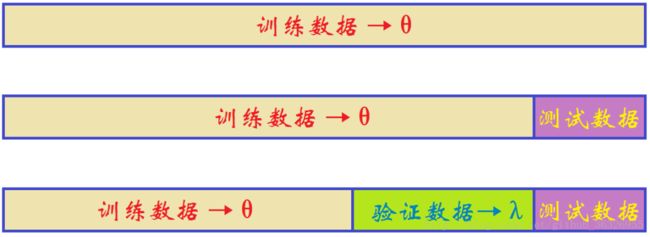
从第一步到第二步,再从第二步到第三步。都可以使用这个函数。
sklearn.model_selection.train_test_split(*arrays, **options)
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数
事实上,这个函数只是用来分割数据的。并不是用来做交叉验证。交叉验证的目的是调参。这里有更直接的办法:
1,网格搜索,即GridSearchCV类。
2,cross_val_score类
我的这个代码首先将10.iris.data数据分成训练集和测试集。然后对训练集使用GridSearchCV进行4折交叉验证。得到较好的参数。数据长这个样子:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@author: XiangguoSun
@contact: [email protected]
@file: train_test_split and GridSearchCV.py
@time: 2017/3/2 8:59
@software: PyCharm
"""
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
'''
有些代码是这样写的:
from sklearn.cross_validation import train_test_split
in fact:
This module was deprecated in version 0.18 in favor of the
model_selection module into which all the refactored classes
and functions are moved. Also note that the interface of the
new CV iterators are different from that of this module.
This module will be removed in 0.20."
'''
if __name__ == '__main__':
path = './10.iris.data' # 数据文件路径
str2num = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
data = np.loadtxt(path, dtype=float, delimiter=',', converters={4: lambda s:str2num[s] })
'''
Load data from a text file.
Each row in the text file must have the same number of values.
Parameters
----------
fname : file or str
File, filename, or generator to read. If the filename extension is
``.gz`` or ``.bz2``, the file is first decompressed. Note that
generators should return byte strings for Python 3k.
dtype : data-type, optional
Data-type of the resulting array; default: float. If this is a
structured data-type, the resulting array will be 1-dimensional, and
each row will be interpreted as an element of the array. In this
case, the number of columns used must match the number of fields in
the data-type.
delimiter : str, optional
The string used to separate values. By default, this is any
whitespace.
converters : dict, optional
A dictionary mapping column number to a function that will convert
that column to a float. E.g., if column 0 is a date string:
``converters = {0: datestr2num}``. Converters can also be used to
provide a default value for missing data (but see also `genfromtxt`):
``converters = {3: lambda s: float(s.strip() or 0)}``. Default: None.
skiprows : int, optional
Skip the first `skiprows` lines; default: 0.
Returns
-------
out : ndarray
Data read from the text file.
'''
x, y = np.split(data, (4,), axis=1)
'''
我们的data是一个shape为(150,5)的ndarray。axis=1,是说以第二坐标轴来分割。
indices_or_sections=(4,)的意思是分割为如下的几个子ndarray:[:4]和[4:]
np.split(data, (4,), axis=1)这段代码相当于将我们的data分割为如下几块:
data[:,0~3],data[:,4~end]
需要注意的是indices_or_sections=4表示分割为大小相等的4部分。
indices_or_sections=[2,3]表示a[:2],a[2:3],a[3:]
也可以用()代替[],但是如果只有一个值,()要用“,”例如(4,)否则会被认为是4
函数的返回是一系列的子数组。在这个例子中,我们分割出两个子数组,分别用x和y来表示
'''
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, train_size=0.6)
'''
现在我们得到了60%的训练数据和40%的测试数据。对于交叉验证的原理而言,你可能还需要
对这60%的训练数据再用若干次train_test_split得到训练数据和验证数据。但是我们接下来可以用网格搜索来
简化这一过程。
'''
print np.shape(x_train),np.shape(y_train),np.shape(y_train[:,0])
'''
(90L, 2L),(90L, 1L),(90L,)
'''
grid= GridSearchCV(svm.SVC(),param_grid={"C":[0.1, 1, 10], "gamma": [1, 0.1, 0.01]},cv=4)
grid.fit(x_train,y_train[:,0])#请注意这里y_train的格式
print ("the best parameters are{0} with a score of {1}".format(grid.best_params_,grid.best_score_))