hive sql join
本篇对Hive QL中join、left outer join、left semi join和full outer join等表连结操作作一简要总结。
测试表准备
首先准备三张测试表,内容分别为:
| hql_jointest_a |
|---|
| idname 1 a 2 b 3 c 4 d 5 e 6 f 7 g 8 h |
-
- id bigint,
- name string
- )
- row format delimited
- fields terminated by '\t'
- lines terminated by '10'
- stored as textfile;
| hql_jointest_b |
|---|
| idscore 1 15 2 50 4 80 6 90 9 100 10 101 11 12 13 11 |
-
- id bigint,
- score bigint
- )
- row format delimited
- fields terminated by '\t'
- lines terminated by '10'
- stored as textfile;
| hql_jointest_c |
|---|
| idbook 1 数据结构 2 离散数学 3 经济学 2 C语言基础 3 离散数学 6 宏观经济学 2 逻辑学 |
-
- id bigint,
- book string
- )
- row format delimited
- fields terminated by '\t'
- lines terminated by '10'
- stored as textfile;
为使后面的论述不至于太生硬,我们给上述三张测试表的字段赋予一定的业务含义:id代表学生的学号,name是学生姓名,score是学生成绩,book是学生拥有的书;在三张表中,id都是主键。第一张表表示某个班级(假设该班级为CS-1)的学生名单,第二张表表示参加了某种考试(假设该考试为T)的学生的成绩,第三张表表示部分学生拥有的书。
join的用法
我们的第一个需求是,找出CS-1班中参加了T考试的学生姓名及其成绩。该需求希望做到的是,取表a和表b中均存在的记录,并使用主键id连结起来。代码如下:
-
- select a.id as id_a, a.name, b.id as id_b, b.score
- from hql_jointest_a a
- join hql_jointest_b b
- on a.id = b.id;
输出结果为:
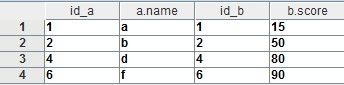
如果关联的结果有重复记录,那么记录会全部保留。为了说明这一点,请先看下面一段代码的输出结果:
-
- select a.id as id_a, a.name, c.id as id_c, c.book
- from hql_jointest_a a
- join hql_jointest_c c
- on a.id = c.id;
这段代码的业务场景可以描述为:找出CS-1班中拥有书的同学姓名及其拥有的书名。输出结果为:
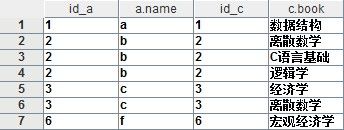
虽然id为2的记录有多条,但这些记录彼此并不重复,表现为最后一个字段book并不相同。
如果我们并不需要书名,只需要找出CS-1班中拥有书的同学姓名,那么代码如下:
-
- select a.id, a.name
- from hql_jointest_a a
- join hql_jointest_c c
- on a.id = c.id;
这时输出结果为:
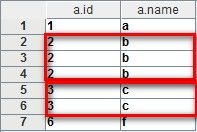
我们注意到,尽管书名book我们并没有提取,但结果集还是保留了id为2的所有三条记录(当然,还有id为3的两条记录)。在我们看来这些记录是重复的、只需要保留1条就足够的,这时可以使用distinct对关联结果进行去重。
-
- select distinct a.id, a.name
- from hql_jointest_a a
- join hql_jointest_c c
- on a.id = c.id;
输出结果为:
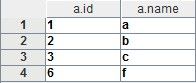
left outer join的用法
现在,需求方告诉我们,对于第一个需求,他们其实还想知道CS-1班中有哪些同学没参加T考试(业务方的真实需求通常很坑爹难以捉摸,理解他们的真实意图十分重要)。这时我们需要把CS-1班的所有学生记录都取出来,同时,如果某学生参加T考试,则列出其分数。这里需要以a为左表,所取结果中应包含a的所有记录。代码如下:
-
- select a.id as id_a, a.name, b.id as id_b, b.score
- from hql_jointest_a a
- left outer join hql_jointest_b b
- on a.id = b.id;
输出结果为:
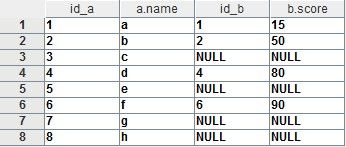
在结果集中,如果某学生没有参加T考试,即其在b表中无相应记录,那么结果集的相应字段会被赋予NULL值。由此我们引出第一个需求中join的另外一种实现方式:
-
- select a.id as id_a, a.name, b.id as id_b, b.score
- from hql_jointest_a a
- left outer join hql_jointest_b b
- on a.id = b.id
- where b.id is not null;
上述代码中加上where b.id is not null,把在b表中值为空的记录剔除,实现的其实是传统sql中的exists in操作。输出结果为:
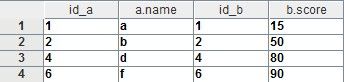
现在,需求方又来麻烦你,把CS-1班中未参加T考试的学生取出来(——怎么,你想做什么?想处罚他们吗?——不不,别误会,只是想通知他们,这个考试必须参加。——哦,这样。题外话:不能只是机械地被动地响应业务方需求,应该问清楚数据的应用场景,了解其想法后必要时予以指导。)。这个需求是,取a中存在但b中不存在的记录。有了上面的阐述,我们很容易搞定代码:
-
- select a.id as id_a, a.name, b.id as id_b, b.score
- from hql_jointest_a a
- left outer join hql_jointest_b b
- on a.id = b.id
- where b.id is null;
以上代码实现的其实就是传统sql中的exists not in操作。输出结果为:
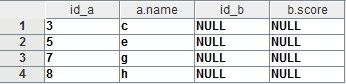
同样的,在left outer join操作中,如果结果集出现重复记录,可以使用distinct去重。
left semi join的用法
上一节我们其实已经变通地实现了exists in和exists not in操作。这里我们使用Hive QL提供的另一种解决方案——left semi join来实现传统sql的exists in操作。使用left semi join,有一个限制条件,即右表的字段只能出现在on子句中,而不能在select和where子句中引用。
回到第一个需求,找出CS-1班中参加T考试的学生。即取a中这样的记录,其id存在于b表中。
-
- select a.id, a.name
- from hql_jointest_a a
- left semi join hql_jointest_b b
- on a.id = b.id;
输出结果为:
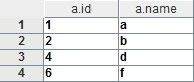
以下两段代码都是错误的:
-
- select a.id, a.name, b.id, b.score --b表出现在了select中
- from hql_jointest_a a
- left semi join hql_jointest_b b
- on a.id = b.id;
-
- select a.id, a.name
- from hql_jointest_a a
- left semi join hql_jointest_b b
- on a.id = b.id
- where b.id >= 3; --b表出现在了where子句中
full outer join的用法
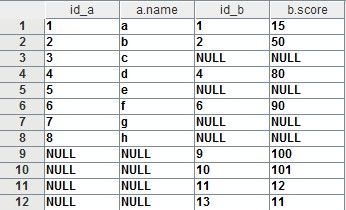
full outer join可以实现全连结。现在,我们需要取出CS-1班的全体学生,或者参加T考试的学生及其成绩。即取a中存在或b中存在的记录。代码如下:
-
- select a.id as id_a, a.name, b.id as id_b, b.score
- from hql_jointest_a a
- full outer join hql_jointest_b b
- on a.id = b.id;
输出结果为:
补充说明
left outer join where is not null与left semi join的联系与区别:两者均可实现exists in操作,不同的是,前者允许右表的字段在select或where子句中引用,而后者不允许。
除了left outer join,Hive QL中还有right outer join,其功能与前者相当,只不过左表和右表的角色刚好相反。
另外,Hive QL中没有left join、right join、full join以及right semi join等操作。