L1 L2 正则化
L1 L2 正则化 是什么
ℓ1 -norm和 ℓ2-norm,中文称作 L1正则化 和 L2正则化,或者 L1范数 和 L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。
所谓的 “惩罚” 是指对损失函数中的某些参数做一些限制。
对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
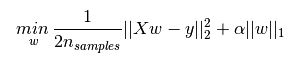
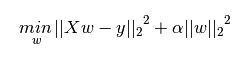
如图,加号后面的分别是 L1正则化项 和 L2正则化项
一般回归分析中回归 w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。
L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量 w w 中各个元素的绝对值之和,通常表示为 ||w||1 | | w | | 1
- L2正则化是指权值向量 w w 中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为 ||w||2 | | w | | 2
一般都会在正则化项之前添加一个系数,Python中用 α α 表示,一些文章也用 λ λ 表示。这个系数需要用户指定。
我在很多资料中也看到这句话: L1正则化产生稀疏的权值, L2正则化产生平滑的权值。
有什么用呢
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
针对上面的说到的作用 L1: 产生一个稀疏模型,可以用于特征选择,下面来解释一下:
- 为什么要生成一个稀疏矩阵?
- 为什么L1正则化可以产生稀疏矩阵(L1是怎么让系数等于0的)
1、稀疏模型与特征选择
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0。
通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
从另一个角度来讲,为防止过拟合,我们考虑 W=(w0,w1,w2,w3,...wN) W = ( w 0 , w 1 , w 2 , w 3 , . . . w N ) 中的项的个数最小化。
一句话,向量中0元素,对应的x样本中的项我们是不需要考虑的,可以砍掉。因为 0∗xi 0 ∗ x i 没有啥意义,说明 xi x i 项没有任何权重。这也是正则项防止过拟合的一个原因。这里顺便解释一个L2比较好的原因:
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的正则项 ||W||2 | | W | | 2 最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦;所以大家比起1范数,更钟爱2范数。
2、L1正则化可以产生稀疏模型
L1 产生稀疏权值,L2 产生平滑的权值
假设有如下带L1正则化的损失函数:
J=J0+α∑w|w| J = J 0 + α ∑ w | w |
其中 J0 J 0 是原始的损失函数,加号后面的一项是L1正则化项, α α 是正则化系数。注意到L1正则化是权值的绝对值之和, J J 是带有绝对值符号的函数,因此 J J 是不完全可微的。
机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。
当我们在原始损失函数 J0 J 0 后添加L1正则化项时,相当于对 J0 J 0 做了一个约束。
令: L=α∑w|w| L = α ∑ w | w |
则: J=J0+L J = J 0 + L
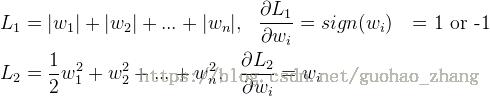
图片中 L2 中 应该每个 w2i w i 2 前面都是乘以 1/2 1 / 2
假设学习率为 η η , L1的权值更新公式为
$w_i = w_i - η * 1,也就是说权值每次更新都固定减少一个特定的值(比如0.5),那么经过若干次迭代之后,权值就有可能减少到0。
L2的权值更新公式为
$w_i = w_i - η * w_i = w_i - 0.5 * w_i,也就是说权值每次都等于上一次的1/2,那么,虽然权值不断变小,但是因为每次都等于上一次的一半,所以很快会收敛到较小的值但不为0。
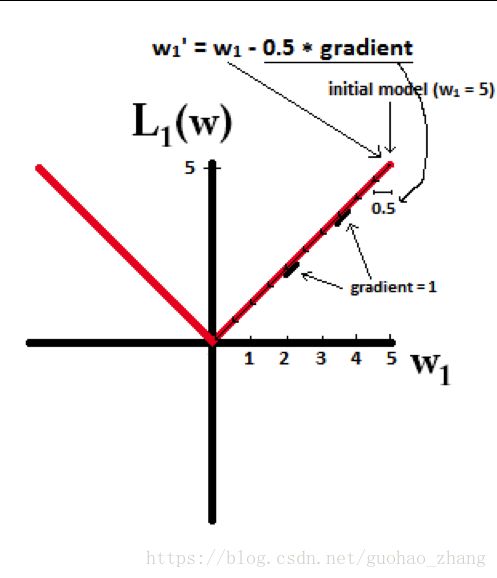
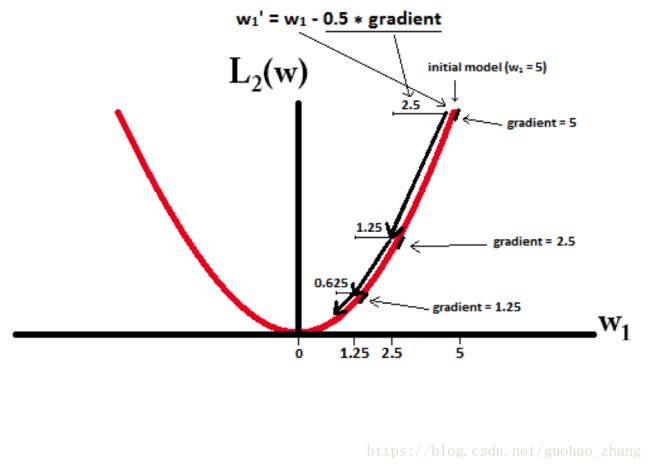
L1能产生等于0的权值,即能够剔除某些特征在模型中的作用(特征选择),即产生稀疏的效果。
L2可以得迅速得到比较小的权值,但是难以收敛到0,所以产生的不是稀疏而是平滑的效果。
还有一种解释是从几何空间解释,不过我还没去搜索资料去理解,还看不懂。。。
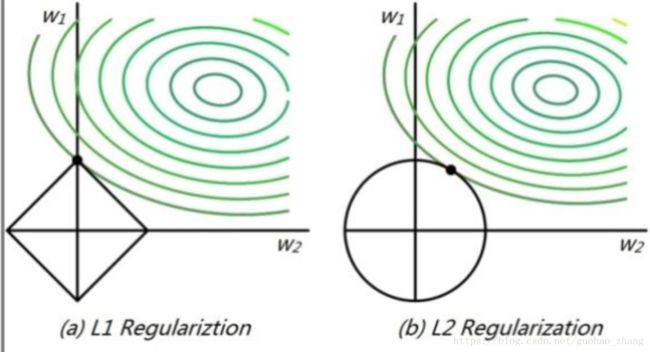
如上图。
L2正则化可以防止模型过拟合(overfitting)
其实按照上面所说已经差不多可以理解为什么可以防止过拟合了,就是在拟合过程中通常都倾向于让权值尽可能小,最后构建一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,一定程度上避免了过拟合现象
可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
设 λ λ 就是正则化参数,学习率Learning rate为 α α ,对于参数 :
J(θ)= J ( θ ) = 12m∗ 1 2 m ∗ ∑mi=1 ∑ i = 1 m (hθ(x(i))−y(i)) ( h θ ( x ( i ) ) − y ( i ) )
在梯度下降中,用于迭代计算参数 θ θ 的迭代式为:
θj:=θj−α1m∑mi=1(hθ(x(i))−y(i))x(i)j θ j := θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i )
而添加正则化后,
θj:=θj∗(1−α1m)−α1m∑mi=1(hθ(x(i))−y(i))x(i)j θ j := θ j ∗ ( 1 − α 1 m ) − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i )
从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代, θj θ j 都要先乘以一个小于1的因子,从而使得θjθj不断减小,因此总得来看, θ θ 是不断减小的。
参考资料:
为什么L1稀疏,L2平滑?
https://www.zhihu.com/question/20924039
https://blog.csdn.net/jinping_shi/article/details/52433975