基于pytorch的FSRCNN的复现
上次的学习笔记——《学习笔记之——基于pytorch的FSRCNN》一直没把PSNR提上来,为此改用代码https://github.com/xinntao/BasicSR通过这套代码的框架来实现FSRCNN,并把实现过程记录在本博文里面。关于这套代码之前也在博文《学习笔记之——SR流程》介绍过。好,下面开始进入正题
目录
代码脉络的梳理
Config
Data
Model
Modules(Network structures)
Utils
Scripts
FSRCNN的实现
先安装一个sublime(http://www.sublimetext.com/)
(http://www.onlinedown.net/soft/68602.htm)
查看GPU状态
nvidia-smi
基本配置

代码脉络的梳理
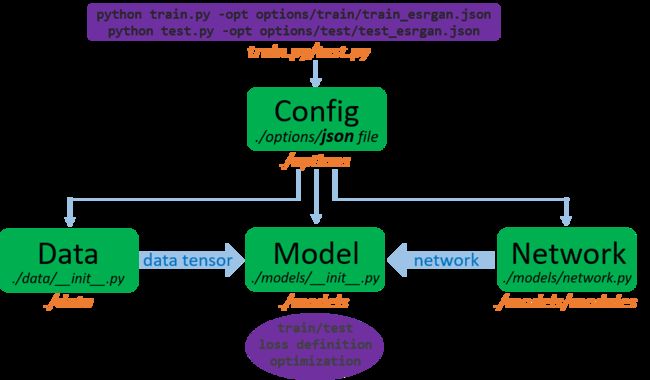
当运行代码“python train.py -opt options/train/train_esrgan.json”一系列的操作会产生
- 首先调用train.py来运行,".json"是设置的条件(seting configuration)。包括了数据读取、网络、损失函数、训练的策略等等。通过“
options/options.py”来处理json文件 - 创建训练集和验证集。数据的加载是通过“
data/__init__.py” - 创建模型。“
models/__init__.py”不同的模型由它来控制构造。每个模型主要包括两个部分:网络“models/network.py”和详细的结构“models/modules”可以通过文档“architecture.py"来设计具体结构 - 开始训练模型。在训练模型过程中(通过设置好路径)。在训练过程中,还进行日志记录、保存中间模型、验证、更新学习率等。

注意下面的批注
![]()
Config
配置数据加载、网络结构、模型、训练策略等选项。
- json文件用于选择配置选项,而”
options/options.py“这个文件会加那个json转为py。 jsonfile usesnullforNone; and supports//comments, i.e., in each line, contents after the//will be ignored.- 在debug模式下,会将模型开头命名为”debug_“
- 配置文件以及相关描述都在”
options“
Data
加载数据,用于训练、验证以及测试
- 这是一个单独的数据装载器模块。可以修改/创建数据加载程序以满足自己的需要。
- 使用CV2来进行图像处理
- 可以采用image文件或lmdb格式的文件读取图像。(为了更快的IO,首先将训练数据转换为.lmdb格式)(打开
codes/scripts/create_lmdb.py.文档来修改) data/util.pyprovides useful tools. For example, theMATLAB bicubicoperation; rgb<-->ycbcr as MATLAB. We also provide MATLAB bicubic imresize wiki and Color conversion in SR wiki.
Model
包含了训练和测试的模型
- 模型主要分为两部分:网络结构(Network structures,在下面Modules描述)。模型的定义(model defination,包括了:loss 和 optimization等)
- 基于”
base_model.py“文件,定义不同的模型如:”SR_model.py,SRGAN_model.py,SRRaGAN_model.pyandSFTGAN_ACD_model.py“
Modules(Network structures)
这里包含了不同网络的结构
- 网络在“
models/network.py”中构建。详细的结构在“models/modules” - 通过“
block.py”中的预定义块来构建网络结构 - 类似于文件“
sft_arch.py”来写自己的网络结构
Utils
“utils”是写logger的,刚开始可以先不看,它能产生tensorboard就可以(注意debug模式下是不会产生tensorboard的logger
的,在文档/home/guanwp/BasicSR-master/tb_logger/)
- “progress_bar.py ”提供可以打印的进度条
- “logger.py ”提供学习和测试过程中的logger
- Support to use tensorboard to visualize and compare training loss, validation PSNR and etc. I
Scripts
“scripts”是怎么生成数据的文档
好,接下来撕开代码,后续会把我注释的代码上传到这个链接(:)
查看“tensorboard --logdir=tb_logger”
通过运行 python train.py -opt options/train/train_sr.json
得出结果如下:



这个PSNR得效果有点差,毕竟在set5上,FSRCNN也能到32dB左右,所以这个应该不止这个水平,接下来好好看看数据处理这块
FSRCNN的实现
工程文件下载链接()
关于反卷积:
https://zhuanlan.zhihu.com/p/39240159

注意:在原版的FSRCNN中是没有padding的,所以,输入11*11尺寸的图片,输出会是27*27。而在这套代码中,处理数据是默认有padding的,就是如果输入为11*11,3倍放大,应该是33*33。再加上,本人觉得SR就应该是放大的倍数,应该加上padding。(当然其实就是怕麻烦要改动数据处理部分)如果要完全复现FSRCNN就确实需要改动数据处理模块。
基本只需要改动.json文件。network.py和architecture.py文件。代码修改部分贴出如下:
architecture.py
#######################################################################################################3
#FSRCNN
class FSRCNN(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, upscale=4, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):##play attention the upscales
super(FSRCNN,self).__init__()
#Feature extractionn
self.conv1=nn.Conv2d(in_channels=in_nc,out_channels=nf,kernel_size=5,stride=1,padding=2)#nf=56.add padding ,make the data alignment
self.prelu1=nn.PReLU()
#Shrinking
self.conv2=nn.Conv2d(in_channels=nf,out_channels=12,kernel_size=1,stride=1,padding=0)
self.prelu2 = nn.PReLU()
# Non-linear Mapping
self.conv3=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu3 = nn.PReLU()
self.conv4=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu4 = nn.PReLU()
self.conv5=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu5 = nn.PReLU()
self.conv6=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu6 = nn.PReLU()
# Expanding
self.conv7=nn.Conv2d(in_channels=12,out_channels=nf,kernel_size=1,stride=1,padding=0)
self.prelu7 = nn.PReLU()
# Deconvolution
self.last_part= nn.ConvTranspose2d(in_channels=nf,out_channels=in_nc,kernel_size=9,stride=upscale, padding=4, output_padding=3)
def forward(self, x):#
out = self.prelu1(self.conv1(x))
out = self.prelu2(self.conv2(out))
out = self.prelu3(self.conv3(out))
out = self.prelu4(self.conv4(out))
out = self.prelu5(self.conv5(out))
out = self.prelu6(self.conv6(out))
out = self.prelu7(self.conv7(out))
out = self.last_part(out)
return out
##########################################################################################################network.py
# Generator
def define_G(opt):
gpu_ids = opt['gpu_ids']
opt_net = opt['network_G']
which_model = opt_net['which_model_G']#hear decide which model, and thia para is in .json. if you add a new model, this part must be modified
if which_model == 'sr_resnet': # SRResNet
netG = arch.SRResNet(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
elif which_model=='fsrcnn':#FSRCNN
netG=arch.FSRCNN(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
elif which_model == 'sft_arch': # SFT-GAN
netG = sft_arch.SFT_Net()
elif which_model == 'RRDB_net': # RRDB
netG = arch.RRDBNet(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'],
nb=opt_net['nb'], gc=opt_net['gc'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'],
act_type='leakyrelu', mode=opt_net['mode'], upsample_mode='upconv')
else:
raise NotImplementedError('Generator model [{:s}] not recognized'.format(which_model))
if opt['is_train']:
init_weights(netG, init_type='kaiming', scale=0.1)
if gpu_ids:
assert torch.cuda.is_available()
netG = nn.DataParallel(netG)
return netG
实验
终于出来的曲线比较正常,不像之前一样不变。

最终结果:


结果感觉还是不够理想哎~接下来test一下:

python test.py -opt options/test/test_sr.json
(SET14里面有几张灰度图!!!!)
关于setting:
1个epoch,5000个iteration
总的训练图片数目为32208,每一个iteration训练图片2013(patch size)
一共1,000,000个iteration,479个epoch
测试过程的验证集为test5
训练集为DIV2K800
scale为4
batch_size为16
"HR_size": 128(patch size=128/4=32)
训练过程中的结果
 input
input
 iters 5000
iters 5000
 iters 100000
iters 100000
 iters 1000000
iters 1000000
 target
target
test的结果:


 test
test
 test
test
 target
target
下面测试一下2倍的结果(3倍的尺寸调不对。。。。)



 input
input
 5000
5000
 100000
100000
 1000000
1000000
 target
target
上面可能看得不是特别清晰。下面用baby的图来做对比
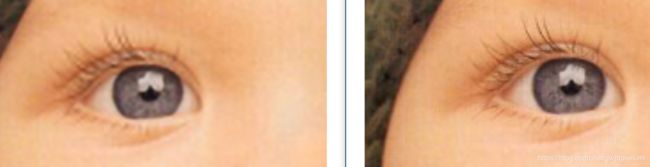
test 结果(上面的PSNR是三通道的,下面的是Y通道的,一般Y通道会高一点。训练过程输出的是三通道的,论文里面的结果是Y通道的):
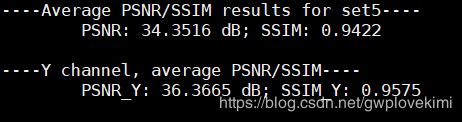

按这样的结果,应该跟论文的差大概0.6dB左右。
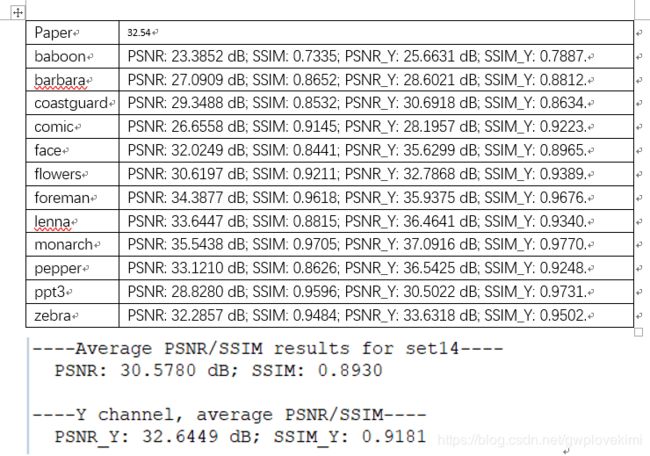
set14中的结果:

更改patch size 为11*11来测试("HR_size": 22 ):


test的结果如下:


这个结果比上面的结果稍差了一点,应该主要是由于patch size小了,这样学到的特征变小的缘故?
好,接下来在DIV2K上,用192的HR patch size跑看看
"batch_size": 8

跑到一半停止了。。。那改为2e7个iters。
"batch_size": 16

训练了13个小时,终于训练完。。。。。。
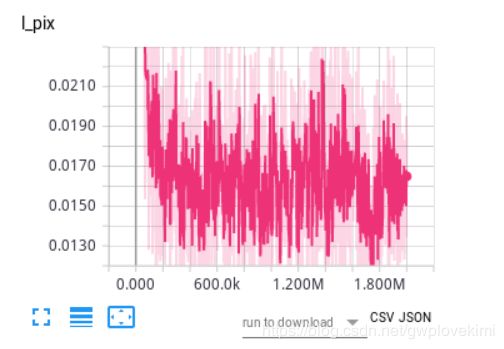

从这里的PSNR(three channels)比前面的好~


在set5上,Ychannel是36.51(论文是36.94)
set14上,Ychannel是32.70(论文是32.54)
woman结果 PSNR: 34.0163 dB; SSIM: 0.9702; PSNR_Y: 35.3620 dB; SSIM_Y: 0.9728.
head结果PSNR: 32.0688 dB; SSIM: 0.8446; PSNR_Y: 35.6635 dB; SSIM_Y: 0.8966.
butterfly结果PSNR: 30.8322 dB; SSIM: 0.9566; PSNR_Y: 32.3198 dB; SSIM_Y: 0.9653.
bird结果PSNR: 38.5543 dB; SSIM: 0.9812; PSNR_Y: 40.7277 dB; SSIM_Y: 0.9870.
baby结果 PSNR: 37.0234 dB; SSIM: 0.9641; PSNR_Y: 38.4817 dB; SSIM_Y: 0.9700.
通过肉眼对比,确实butterfly要模糊一点





再做一组学习率为1e-3的结果(修改了原程序,使得训练时产生的PSRN是Ychannel的)并且将set14补全了。


换掉学习率后,训练了49分钟就跟原文结果相差0.3dB了
训练了一个多小时的结果(相差基本在0.2dB以内了,结果应该是差不多了哎~)如此看来,学习率的设置很重要!!!



结果如下:



结果终于比原文好了哎~(好一点点)结果粘贴在下面。







set5上结果比原文好0.03个dB,set14上比原文好接近0.2dB,感觉就是在set5上,fsrcnn的能力就到37左右了,提升不会很大,在set14上其实变化也不算多,一般0.2dB其实是波动范围哈~
与原文结果进行对比

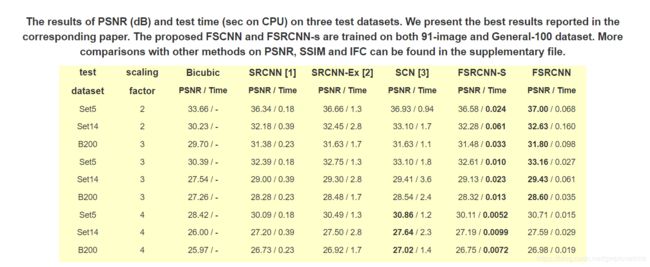
分析文档








最终几个实验下来的对比

绿色那条是由于把PNSR改为计算Y_channel的,其他的都是三通道的。但是也可以看出粉色的setting是比较好的,就是在DIV2K上,用192的patch(HR)来训练,更多的特征~
一些知识点的补充
iteration:1个iteration等于使用batchsize个样本训练一次;
epoch:1个epoch等于使用训练集中的全部样本训练一次;

关于nn.Module
https://blog.csdn.net/u012609509/article/details/81203436
关于super() 函数
http://www.runoob.com/python/python-func-super.html