基于pytorch的改进的VDSR的复现(基于FSRCNN的)
本博文为本人对FSRCNN+residual后的实验的分析博文。不完全采用VDSR的代码,只对其中的residual部分做了参考。
之前的博文《学习笔记之——基于深度学习的图像超分辨率重构》也介绍过VDSR,VDSR是基于SRCNN改进的,这里做的是基于FSRCNN的VDSR。

VDSR的网络结构如下:

那么本博文其实就是把这个网络结构中的SR部分由SRCNN改为FSRCNN
基于pytorch的VDSR链接(https://github.com/twtygqyy/pytorch-vdsr)
paper(https://arxiv.org/pdf/1511.04587.pdf)
下面给出修改后的代码:
python train.py -opt options/train/train_sr.json
#######################################################################################################3
#FSRCNN
class FSRCNN(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, upscale=4, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):##play attention the upscales
super(FSRCNN,self).__init__()
#Feature extractionn
self.conv1=nn.Conv2d(in_channels=in_nc,out_channels=nf,kernel_size=5,stride=1,padding=2)#nf=56.add padding ,make the data alignment
self.prelu1=nn.PReLU()
#Shrinking
self.conv2=nn.Conv2d(in_channels=nf,out_channels=12,kernel_size=1,stride=1,padding=0)
self.prelu2 = nn.PReLU()
# Non-linear Mapping
self.conv3=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu3 = nn.PReLU()
self.conv4=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu4 = nn.PReLU()
self.conv5=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu5 = nn.PReLU()
self.conv6=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu6 = nn.PReLU()
# Expanding
self.conv7=nn.Conv2d(in_channels=12,out_channels=nf,kernel_size=1,stride=1,padding=0)
self.prelu7 = nn.PReLU()
# Deconvolution
self.last_part= nn.ConvTranspose2d(in_channels=nf,out_channels=in_nc,kernel_size=9,stride=upscale, padding=4, output_padding=1)
#for the residual
self.DECO_part= nn.ConvTranspose2d(in_channels=in_nc,out_channels=in_nc,kernel_size=9,stride=upscale, padding=4, output_padding=1)
def forward(self, x):#
residual=self.DECO_part(x)###########
out = self.prelu1(self.conv1(x))
out = self.prelu2(self.conv2(out))
out = self.prelu3(self.conv3(out))
out = self.prelu4(self.conv4(out))
out = self.prelu5(self.conv5(out))
out = self.prelu6(self.conv6(out))
out = self.prelu7(self.conv7(out))
out = self.last_part(out)
out = torch.add(out,residual)####################
return out
##########################################################################################################结果如下:

运行得特别得慢。。。。。


结果对比:
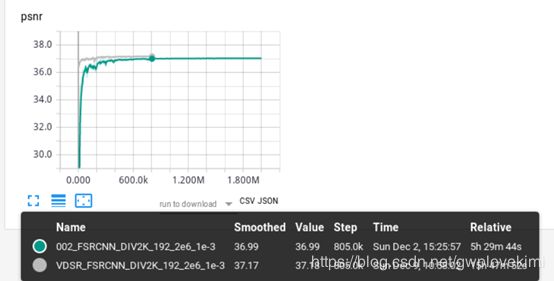
不采用反卷积,改为采用bicubic,代码修改如下:
#######################################################################################################3
#FSRCNN
class FSRCNN(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, upscale=4, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):##play attention the upscales
super(FSRCNN,self).__init__()
#Feature extractionn
self.conv1=nn.Conv2d(in_channels=in_nc,out_channels=nf,kernel_size=5,stride=1,padding=2)#nf=56.add padding ,make the data alignment
self.prelu1=nn.PReLU()
#Shrinking
self.conv2=nn.Conv2d(in_channels=nf,out_channels=12,kernel_size=1,stride=1,padding=0)
self.prelu2 = nn.PReLU()
# Non-linear Mapping
self.conv3=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu3 = nn.PReLU()
self.conv4=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu4 = nn.PReLU()
self.conv5=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu5 = nn.PReLU()
self.conv6=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu6 = nn.PReLU()
# Expanding
self.conv7=nn.Conv2d(in_channels=12,out_channels=nf,kernel_size=1,stride=1,padding=0)
self.prelu7 = nn.PReLU()
# Deconvolution
self.last_part= nn.ConvTranspose2d(in_channels=nf,out_channels=in_nc,kernel_size=9,stride=upscale, padding=4, output_padding=1)
def forward(self, x):#
residual=x
m = nn.Upsample(scale_factor=2)
residual=m(residual)
#print(residual.size())
#exit()
out = self.prelu1(self.conv1(x))
out = self.prelu2(self.conv2(out))
out = self.prelu3(self.conv3(out))
out = self.prelu4(self.conv4(out))
out = self.prelu5(self.conv5(out))
out = self.prelu6(self.conv6(out))
out = self.prelu7(self.conv7(out))
out = self.last_part(out)
out=torch.add(out,residual)###################
return out
##########################################################################################################
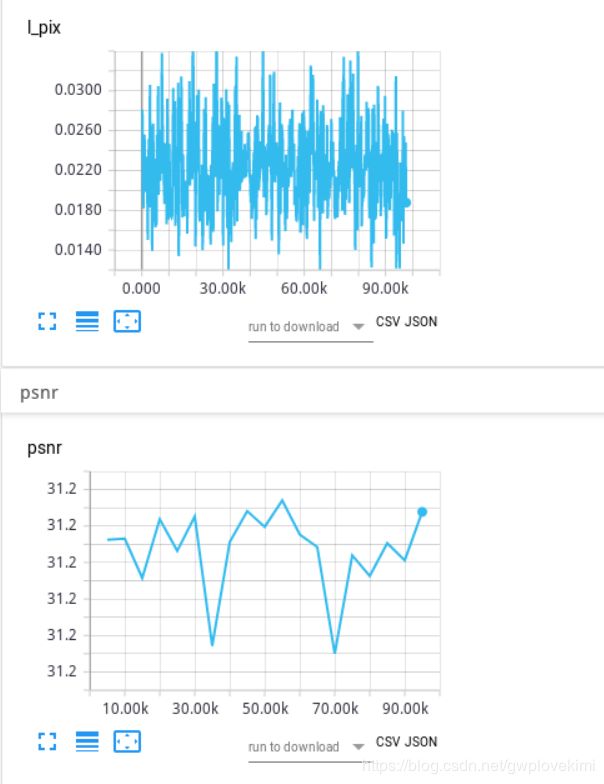
网络没有办法收敛。。。。我也不知道什么原因了。。。。。感觉就是采用了pytorch自带的函数这样插值就会这样。。。。。那还是采用反卷积来实验resudual把
再试试代码如下:
#######################################################################################################3
#FSRCNN
class FSRCNN(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, upscale=4, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):##play attention the upscales
super(FSRCNN,self).__init__()
#Feature extractionn
self.conv1=nn.Conv2d(in_channels=in_nc,out_channels=nf,kernel_size=5,stride=1,padding=2)#nf=56.add padding ,make the data alignment
self.prelu1=nn.PReLU()
#Shrinking
self.conv2=nn.Conv2d(in_channels=nf,out_channels=12,kernel_size=1,stride=1,padding=0)
self.prelu2 = nn.PReLU()
# Non-linear Mapping
self.conv3=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu3 = nn.PReLU()
self.conv4=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu4 = nn.PReLU()
self.conv5=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu5 = nn.PReLU()
self.conv6=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu6 = nn.PReLU()
# Expanding
self.conv7=nn.Conv2d(in_channels=12,out_channels=nf,kernel_size=1,stride=1,padding=0)
self.prelu7 = nn.PReLU()
# Deconvolution
self.last_part= nn.ConvTranspose2d(in_channels=nf,out_channels=in_nc,kernel_size=9,stride=upscale, padding=4, output_padding=1)
#Upsmaple
self.m=nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, x):#
residual_x=x
residual=self.m(residual_x)
#print(residual.size())
#exit()
out = self.prelu1(self.conv1(x))
out = self.prelu2(self.conv2(out))
out = self.prelu3(self.conv3(out))
out = self.prelu4(self.conv4(out))
out = self.prelu5(self.conv5(out))
out = self.prelu6(self.conv6(out))
out = self.prelu7(self.conv7(out))
out = self.last_part(out)
out=torch.add(out,residual)###################
return out
##########################################################################################################结果也是一开始不收敛,但是慢慢得训练就好多了,可惜最终得PSNR还是比较低

再换setting
#######################################################################################################3
#FSRCNN
class FSRCNN(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, upscale=4, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):##play attention the upscales
super(FSRCNN,self).__init__()
#Feature extractionn
self.conv1=nn.Conv2d(in_channels=in_nc,out_channels=nf,kernel_size=5,stride=1,padding=2)#nf=56.add padding ,make the data alignment
self.prelu1=nn.PReLU()
#Shrinking
self.conv2=nn.Conv2d(in_channels=nf,out_channels=12,kernel_size=1,stride=1,padding=0)
self.prelu2 = nn.PReLU()
# Non-linear Mapping
self.conv3=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu3 = nn.PReLU()
self.conv4=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu4 = nn.PReLU()
self.conv5=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu5 = nn.PReLU()
self.conv6=nn.Conv2d(in_channels=12,out_channels=12,kernel_size=3,stride=1,padding=1)
self.prelu6 = nn.PReLU()
# Expanding
self.conv7=nn.Conv2d(in_channels=12,out_channels=nf,kernel_size=1,stride=1,padding=0)
self.prelu7 = nn.PReLU()
# Deconvolution
self.last_part= nn.ConvTranspose2d(in_channels=nf,out_channels=in_nc,kernel_size=9,stride=upscale, padding=4, output_padding=1)
#Upsmaple
self.m=nn.UpsamplingNearest2d(scale_factor=2)
def forward(self, x):#
residual_x=x
residual=self.m(residual_x)
#print(residual.size())
#exit()
out = self.prelu1(self.conv1(x))
out = self.prelu2(self.conv2(out))
out = self.prelu3(self.conv3(out))
out = self.prelu4(self.conv4(out))
out = self.prelu5(self.conv5(out))
out = self.prelu6(self.conv6(out))
out = self.prelu7(self.conv7(out))
out = self.last_part(out)
out=torch.add(out,residual)###################
return out
##########################################################################################################
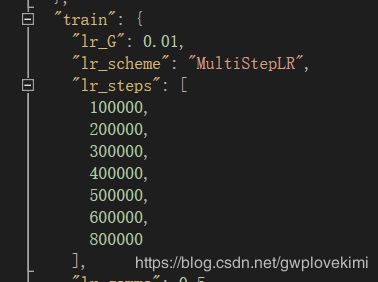
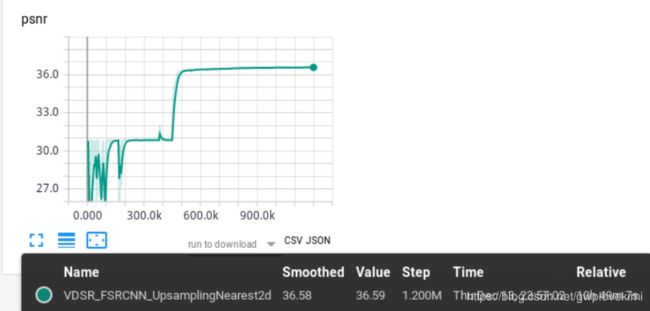
这样得结果看似学习率一开始设置太大了~~~那试试把学习率设置低一点看看
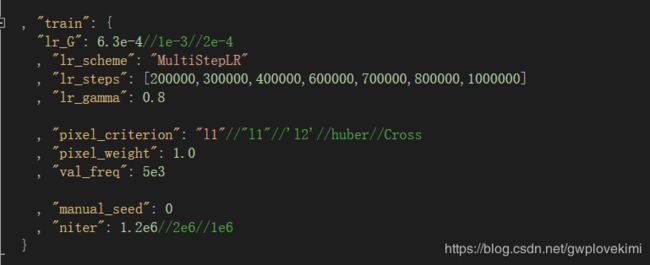


补充
can't convert CUDA tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.

关于pytorch中的上采样https://blog.csdn.net/g11d111/article/details/82855946

class torch.nn.UpsamplingBilinear2d(size=None, scale_factor=None)[source]
https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn/#class-torchnnupsamplingbilinear2dsizenone-scale_factornonesource
