论文阅读笔记之——《Dynamic Conditional Networks for Few-Shot Learning》
DCCN由双子网组成:DyConvNet包含一个动态卷积层和一组基滤波器;CondiNet预测从条件输入到线性组合基滤波器的一组自适应权值。通过这种方式,可以动态地为每个条件输入获取特定的卷积核。滤波器组在所有条件下都是共享的,因此只需要学习一个低维权向量。当训练数据有限时,这大大促进了跨不同条件的参数学习。我们对DCCN进行了四项任务的评估,这些任务可以表述为条件模型学习,包括特定对象计数、多模态图像分类、短语基础和基于身份的人脸生成。大量的实验证明了该模型在有条件小波学习环境下的优越性。
条件模型是一种重要的机器学习框架,可用于多种任务,如多模态学习和条件生成模型。它通常包含两个输入。一个是任务兴趣,另一个是条件输入,提供特定情况的附加信息。近年来,由于深度神经网络在计算机视觉[13,15]、自然语言处理[37,19]、语音识别[26,1]等许多重要领域取得了前所未有的进展,深度条件模型引起了人们的广泛关注。然而,在具有挑战性的条件性少拍学习场景中,由于条件性空间的高维性,虽然训练样本的总数可以很大,但是每个条件的训练样本都是有限的,因此,他们的学习效果通常会下降。
基于深度学习的方法通常需要大量的标签数据进行训练,同时还需要专门的计算平台和优化策略来实现令人满意的性能。由于过度拟合问题严重,训练样本量较小的学习问题往往导致学习成绩严重下降。相比之下,人类,甚至儿童都能非常快地掌握一个新概念(如长颈鹿),高效地取样,并能从对少数例子(如书中的图片)的短暂接触中合理地归纳出新的案例[4,20]。这一现象激发了对少拍学习问题的研究,即,任务是动态地学习一个新概念,从每个类别的几个甚至一个带注释的示例中学习[3,36]。
Few-shot学习无论在学术上还是在工业上都具有重要意义,因为1)模型在这项任务上的出色表现将有助于减轻昂贵的和劳动密集型的数据收集和标记,因为它们不需要大量的标记训练数据来实现合理的性能;2)实际的目标数据通常有大量不同的类别,但每个类别的例子很少。例如,当机器人在自然环境中工作时,在每个[17]只看到几个例子后,应该能够识别出许多不熟悉的物体。在这些场景中进行泛化的能力将有助于更有效地对实际数据分布进行建模。
在本文中,我们主要关注于改进两种条件少拍学习场景下的模型,即区别的和生成的。判别模型通常采用手工制作的特征,并付出巨大的人力工程努力,然后采用度量学习算法,或从大量标记数据中提取深度学习解决方案。然而,这种数据驱动的方法在计算上过于复杂,无法满足实际应用。此外,覆盖所有潜在变化的大量带标签的训练数据通常是昂贵和不可用的。生成模型通常利用数据生成模型,如生成对抗网络(GANs)[10]、条件生成对抗网络(Conditional-GANs)[24]、边界均衡生成对抗网络(BE-GANs)[2]等来合成辅助训练数据进行数据扩充。然而,在目前的生成方法中,合成数据的质量还远远不能满足实际分析任务的需要。
摘要为了解决具有挑战性和现实意义的条件极值学习问题,我们探索了一种新的方法,即从每个条件的几个标记示例中学习一个深度条件模型,这种方法可以很好地推广到相同条件下的其他情况。这些条件可以基于类别标签、数据的某些部分,甚至来自不同模式的数据。此外,为了实现高效的实时计算,我们将这个有条件的小波学习问题以端到端方式联合化为双子网学习。其中一个子网叫做DyConNet,它包含一个动态卷积层和一组可训练的基滤波器。给定任何条件输入,另一个子网CondiNet预测一组自适应权值来线性组合基过滤器。通过这种方式,可以动态获得每个条件输入的具体卷积核,如图1所示。


在优化过程中,各情况间共享滤波器组,每一工况只需要倾斜一个低维权重向量,大大弥补了少拍设置信息的局限性,有利于各情况间高效的参数学习。我们将该模型称为动态条件卷积网络(Dynamic condition tional Network, DCCN)。我们从四个不同的任务来评估DCCN,这些任务都可以被表述为条件模型学习,包括特定的对象计数、多模态图像分类、短语基础和基于身份的人脸生成。所提出的DCCN在所有任务上都优于其他的判别条件模型和生成条件模型。
我们在本文中的贡献总结如下。(1)提出了一种新颖有效的深度架构,其中包含动态卷积子网(DyConvNet)和条件子网(CondiNet),它们以端到端方式共同执行从学习到学习。这种深度架构提供了一个统一的框架,可以有效地进行有条件的少量学习。(2)动态卷积是将DyConvNet中filter bank的基滤波器与CondiNet根据条件输入预测的一组自适应权值线性组合而成,不同于现有的条件学习方法通过直接串联将两个输入组合而成。(3)我们的架构是通用的,适用于多个不同的条件模型学习任务。我们的深层架构的源代码和经过训练的模型将提供给社区。
尽管最近深度神经网络取得了成功,但要使这种模型适用于大量的类别,而每个类别的样本又有限,就像在小概率学习的情况下那样,仍然具有挑战性。到目前为止,许多工作主要集中在学习从输入到输出的一对一映射。然而,许多有趣的问题更自然地被认为是概率一对多映射。例如,在图像标签的情况下,可能有许多不同的标签可以适当地应用于给定的图像,不同的数据注释器可能使用不同的术语来描述相同的图像。解决这个问题的一种方法是利用来自其他模式的额外信息,并使用条件模型,将小样本和条件变量作为输入,并将一对多映射实例化为条件预测分布。
由于我们在条件建模任务中考虑的学习次数很少,所以我们从制定标准条件模型学习开始。它的目的是找到使预测函数h(X|Y;W)的损失L最小的参数W,在N个样本习上的平均值以及相应的条件yi:

模型可以是判别型的学习分类器也可以是生成型的学习X和Y上的条件分布。
在当状态空间的维数过高,每个条件的训练样本仍然稀缺的状态虽然总有大量的训练数据,和我们的目标是学习W感兴趣的小样本条件y,称为条件few-shot学习。条件有限学习的主要挑战是找到一种将特定领域的信息整合到网络中的机制。另一个挑战是如何提高方程(1)的优化效率,这在小波学习的应用中具有实际意义。
我们建议通过使用元学习过程,从具有y条件的小样本中学习预测器的参数W,即、非迭代前馈功能ϕ(元学习者)映射(y,W0)预测的最优W(基础学习者)。我们使用神经网络模型对这个函数进行参数化,我们称之为CondiNet。CondiNet输出依赖于条件y, y是感兴趣的条件的一个代表,它包含自己的参数W0。我们对CondiNet进行如下培训,使其能够针对不同的任务产生合适的W。我们使用以下目标函数优化CondiNet。前馈CondiNet评价比求解Eqn(1)优化问题快得多。
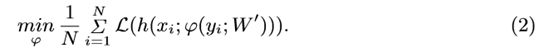
重要的是,Eqn的原始W的参数。(1)现在动态适应每一个条件输入y。注意,该训练方案与siamese networks[5]的训练方案类似,[5]也使用双子网。然而,siamese网络采用具有共享权值的相同网络体系结构,并计算其输出的内积来产生相似度评分:
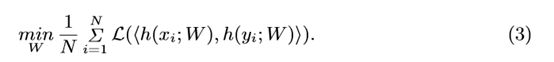


动态卷积
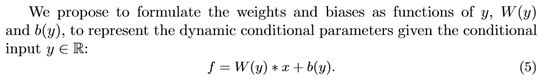

CondiNet的输出空间随着通道数量的增加呈二次增长。过度拟合的问题、记忆和时间成本使学习成为一种遗憾,在少数情况下很难学习。
为了解决上述问题,在学习条件模型时,我们在这里提出了一种简单而有效的方法来减少输出空间,考虑如下分解(为了简化,我们去掉了偏差项b):


滤波器组在所有条件状态之间共享,只有基滤波器的权值特定于每个条件状态。w和w0都包含可训练参数,但与Eqn中讨论的情况相比,它们的大小适中。(5)。重要的是,CondiNetϕ(·)现在只需要预测的自适应权重,所以它的输出空间线性增长的数量基础过滤器过滤器银行(即。ϕ(·):R Rn)。因为在Eqn中产生了卷积核(w0i·wi)。(6)是动态变化的,根据预测CondiNetϕ(·)和滤波器组的主要预测因子h(·),我们构建作为另一个子网DyConvNet h(·)。利用传统的链规则和反向传播算法,双子网协同工作,实现了深度条件模型参数的联合学习。
实验
4.1具体对象计数

具体的对象计数任务来自Amazon Bin Image Dataset (ABID)挑战,该挑战是在给定图像和目标类别的情况下预测一个Bin中的对象数量。当一个bin中的对象的最大数量被设置为一个常量(这里是5)时,我们通过将对象类别视为一个条件输入,将这个任务表述为一个条件分类模型。如图2 (b)所示,一个网络用于提取图像特征,另一个网络用于嵌入对象ID。最后,我们使用动态条件层来组合这两个网络的最后一层,以输出对象的数量。这里我们使用一个普通的条件网络(图2 (a))作为基线,即,直接连接最后一层,并用完全连接的层(FC layer)替换我们的动态条件层。
数据集和评价指标:我们在两个子任务上评估我们的模型,即,实物数量的验证和鉴定。前者是为了验证给定的对象数量对于bin图像是否正确。后者是直接对bin图像中的对象进行计数。数据集包含535234 bin图像,分为两个子集,481711图像用于训练,其余图像用于测试。为了验证对象数量,我们对图像、对象ID和数量三联进行了测试。准确性是用来衡量这两个任务的性能。
体系结构和培训。与数据集网站提供的模型架构设置类似,我们使用ResNet-34网络提取图像特征。普通条件网络中对象ID的嵌入维数为512。动态条件层的维度分别设置为4、8和16,以研究使用不同数量的基滤波器的效果。为了便于训练和比较,所有的图像都被调整为224x224。由于它实际上是一个分类任务,所以采用Softmax损耗来优化整个网络。我们训练了30个时代。初始学习率为0.1,每10个时间下降10倍。
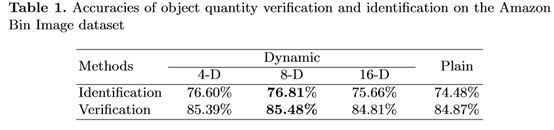
结果和分析。表1给出了我们的方法在动态卷积层和纯条件网络各维度下的准确率。可以看出,我们的网络使用8-D动态层达到了最好的精度。普通条件网络的性能不是很好,因为对象ID集太大,而且每个ID只与少数训练示例相关联(大多数ID只有一个示例)。当嵌入维数过高时,很难学习每个ID的条件网络,而当嵌入维数过低时,网络传统输出的判别能力就不够强。与此相反,DCCN使得不同的id共享一个过滤库。学习将一组滤波器组合成卷积核只需要一个低维向量。将该核函数应用于特征网络的顶层,可以学习图像与目标ID的空间局部相关性,使条件输出对不同的ID具有更好的鉴别性。注意,随着动态层尺寸的不断增大,如16,由于过拟合,性能反而下降。
4.2多模态图像分类
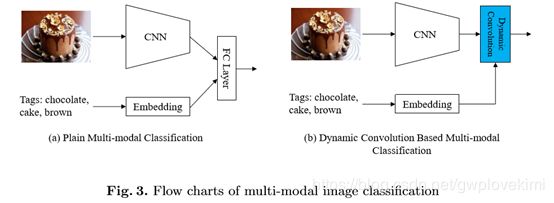
多模态分类是由两个网络组成的典型条件模型。图3 (a)给出了多模态分类的一般框架。两个网络的输入分别是描述图像的图像和文本。文本通常首先转换为词袋向量。然后将网络的输出通过一个完全连通的层组合成一个特征向量。我们使用这个普通的条件网络作为基线。图3 (b)给出了用于多模态分类的动态卷积,我们将完全连通层替换为动态条件层。
数据集和评价指标。我们在MIRFlickr25K数据集[16]上评估我们的模型,该数据集包含从社交网站Flickr下载的25,000张图像。每个图像与大约20,000个标记相关联。38个类标签,包括各种场景和对象,如sunset, car和bird,用于对这些图像进行标注,一个图像可能属于多个类标签。我们随机抽取20000张图片进行训练,其余的进行测试。多标签分类性能是通过多标签设置中对并集的交集(cross over Union, IoU)来衡量的,其定义为正确预测的标签数量除以预测的标签与ground-truth标签的并集。
体系结构和培训。基线和我们的方法的基本网络都是ResNet-34网络。基线中文本的嵌入维度为512。我们将动态条件层的维度分别设置为32、64和128。为了处理一幅图像中的多个标签,我们采用交叉熵损失来学习条件网络。训练期是90。从0.1开始,学习率每30个时间下降10倍。
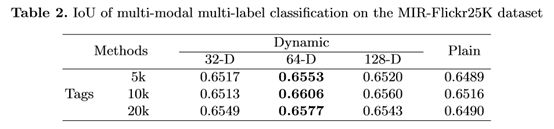
结果和分析。表2报告了不同方法在MIR-Flickr25K数据集上的结果。可以看出,当动态层的维数为64时,我们的动态条件网络在不同标签数量的情况下,其性能优于基线。我们认为,虽然总的训练图像是足够的,但是每个标签只有几个训练图像。也就是说,对于每个标记来说,它仍然是一个小的学习。因此,减少条件网络参数的动态层能够有效地解决这种少镜头条件学习的过拟合问题,并且通过使用所有的训练图像可以方便地学习到标签共享的滤波器组。
4.3短语接地 4.3 Phrase Grounding
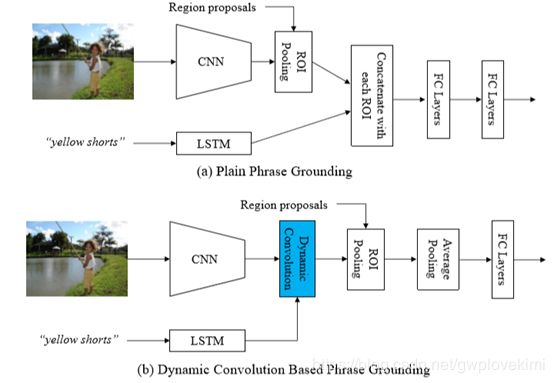
短语接地的任务是对图像中由文本短语描述的对象或场景进行局部化[32,29]。此任务也可以建模为条件模型。一个典型的短语接地框架如图4 (A)所示,使用卷积神经网络生成输入图像的空间特征图,使用长短时记忆网络(Long Short-Term Memory network, LSTM)[11]将输入短语嵌入到一个固定长度的向量中。然后是一组区域建议的特征(即在空间特征图上应用ROI池提取边缘框[43])。最后,将建议特征分别与短语向量连接,计算两个完全连通层的关联得分。图4 (b)为提出的基于动态卷积的短语接地。首先利用动态条件层将短语向量与图像特征映射相结合,得到相关的特征映射。然后利用ROI池获取每个区域方案的相关特征图,并将其依次送入平均池和全连通层中计算相关得分。

数据集和评价指标。Flickr30k Entities数据集[30]用于评估我们的短语接地模型,它是Flickr30k数据集[38]的扩展。它由31,000幅图像及其标题组成,这些标题与276,000个手动标注的边框相关联。我们使用2000张图片进行测试,剩下的图片用于培训。在[30]之后,如果一个短语(例如彩虹旗)有多个ground truth边界框,则使用这些框的并集来表示短语。如果短语预测的图像区域的欠条和ground truth boundary box大于0.5,则认为短语预测的区域是正确的。
体系结构和培训。与[32]相同,我们采用VGG-16网络提取图像特征映射,在PascalVOC数据集上进行预处理进行目标检测,在对整个条件模型进行训练时进行固定。LSTM的隐藏单元数和输入单元数都是512。动态层的维度分别设置为8、16和32。边缘框生成的100个区域建议被用作候选边界框。我们利用Softmax损失来学习该模型,使输入短语与正确的区域建议的相关性得分最大化。我们训练了90个时代。初始学习率为0.01,每30次下降10倍。
结果和分析。表3报告了Flickr30k Entities数据集上IoU > 0.5条件下不同方法短语接地的准确性。可以看出,当动态层的维数为16时,我们的动态条件网络达到了与最先进的方法相比的最佳精度。非线性sp[34]和GroundR[32]的框架如图4 (a)所示,即,利用全连通层将图像区域的特征与短语相结合。SMPL[35]使用二分匹配来计算它们的相关分数。然而,所有这些方法都没有考虑到,虽然在这个数据集中有大量的训练图像,但是每个阶段只有少数训练图像可用。从这个意义上说,这个任务可以看作是一个有条件的少拍学习问题,我们的动态条件层可以更好地解决这个问题。表4报告了不同类型短语的短语基础的准确性。对于大多数短语类型,我们的方法比其他方法有更好的性能。
虽然有一些基于短语的方法比我们的方法有更好的性能,例如RtP[28]和SPC+PPC[29],但是我们认为这些方法使用额外的线索来提高图像区域和短语的相关性学习,例如区域短语的兼容性、候选位置和大小。实际上,我们的模型更像是一个概念证明,我们将其应用于短语基础的任务中,验证其在条件小波学习中的有效性。它与短语接地文献中发现的许多技术改进正交。
4.4 Identity Based Face Generation

该方法还可用于改进条件生成模型。在这里,我们测试基于身份的人脸生成任务的DCCN。图5 (a)给出了一种基于条件生成对抗网(GAN)[24]的通用框架,该框架由生成模型G和判别模型d两部分组成。然后将该表示形式输入反卷积神经网络生成输入ID的人脸图像。在D中,利用卷积神经网络提取G生成的人脸特征和真实人脸特征。然后脸的特性和嵌入向量ID连接,输入分类器时,法官是否面临是否真正为这个ID。提出基于动态卷积条件GAN见图5(b)。我们使用动态条件层集成面对ID与G D和图像的噪声特性,分别。
数据集和评价指标。我们在MS-Celeb1M数据集[12]上评估我们的模型,该数据集包含100K受试者的大约10M张人脸图像。在训练集中,我们随机抽取100名受试者和10张人脸图像作为样本,对每个受试者进行有条件的少拍设置模拟。在测试中,给定生成的人脸图像,使用预先训练的人脸识别模型来预测它属于100个受试者中的哪一个。每个主题生成50张图像。采用精度覆盖曲线和累积匹配特征曲线来衡量人脸识别的性能。
体系结构和培训。我们分别在生成模型和判别模型中使用五层全卷积网络和反卷积网络。为了学习条件GAN,我们对生成模型G和判别模型D进行了交替优化。训练D使输入ID条件下的分类损失最小化,训练G使输入ID条件下的分类损失最大化,即,试图生成可以混淆的人脸图像。
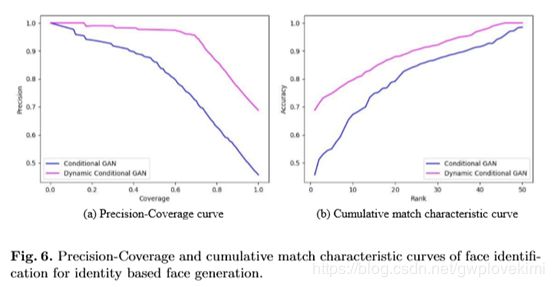
结果和分析。图6为生成的人脸图像的人脸识别PR和CMC曲线。表5给出了当覆盖率=0.99和0.95时的精度以及第1和第5级的精度。可以看出,动态条件GAN在所有指标上都优于普通条件GAN。在每个条件下训练数据有限的情况下,动态层可以跨条件共享滤波器组,有效地整合条件输入的信息。生成的一些面示例如图7所示。每行面对应一个主题。动态条件GAN生成的人脸与实验对象的真实人脸有明显的相似性。

结论
本文研究了条件小波学习问题。提出了一种动态条件卷积网络,该网络在每个条件只有少量训练样本的情况下,将条件输入合并到深度模型中。在该模型中,预测一组来自条件输入的自适应权值,线性组合所有条件共享的滤波器组的基滤波器。然后根据不同的条件输入得到动态卷积核。最后将动态内核应用于另一个网络的顶层,以提供条件输出。四项任务的定性和定量实验表明,与其他条件学习模型相比,该模型具有更好的学习效果。