深度学习Caffe实战笔记(5)Windows caffe平台跑Siamese mnist数据集
前几篇博客介绍了环境搭建,caffe跑lenet,alexnet,cifar10,基础的一些操作都介绍的很详细了。这篇博客介绍如何使用Siamese网络跑mnist数据集,下一篇介绍如何用Siamese网络跑自己的数据集。说到Siamese网络,这次不哭了,因为几篇博客把该哭的都哭完了。
网上的资料都是基于Ubuntu系统的,介绍Windows平台下Siamese网络几乎没有,所以尽管博主查阅了各种论坛、社区,在各种深度学习相关的群里求助,没有人理我,(当然,也可能是鉴于博主学术水平太低,没人理),没办法,只能自己从头开始研究了,慢慢的也就把这个问题搞定了,我愿意把我学习到的这些东西分享给大家。
有的人觉得自己辛苦得来的东西,害怕别人知道了,不愿意告诉别人怎么做的,其实这样的人格局实在太小,殊不知你告诉别人的只不过是一个结果,在你探索过程中得到的分析能力,思维方式,你的知识结构别人是拿不去的!你在乎的,往往能反映出你的水准,为什么层次越高的人,反而计较的越少呢?不是说他有多么宽容,而是有些事根本入不了他的眼。愿不愿意分享,就能看出一个人的眼界和格局,而眼界和格局往往才是决定一个人盛衰成败的关键!共勉。。。。。。
又来了,又来了,博主真矫情,算了,我们开始train。
mnist数据集和Siamese网络不做介绍了吧,如果不知道的话可以Google一下。。。。。。
1、准备数据
从Yann LeCun老先生的主页上可以下载mnist数据集http://yann.lecun.com/exdb/mnist/解压完如下:

四个文件分别代表测试数据,测试数据标签,训练数据,训练数据标签。
2、转换数据
这次转换数据和Alexnet的转换数据方式可不一样,同样的方法,在caffe-windows-master\build_cpu_only文件夹下有一个convert_mnist_data文件,把这个文件复制,重命名为convert_mnist_siamese_data,把里面的release文件夹删除,把剩下的三个文件也重命名为convert_mnist_siamese_data。这是本博主的高明之处,原因在于这样避免了各种配置环境和找不到各种文件的问题。然后用vs打开caffe-windows-master\build_cpu_only\MainBuilder.sln,通过右键添加工程的方式把刚才复制的工程添加进来,这个时候添加进来的工程还没有改名字,把工程名字改成convert_mnist_siamese_data。
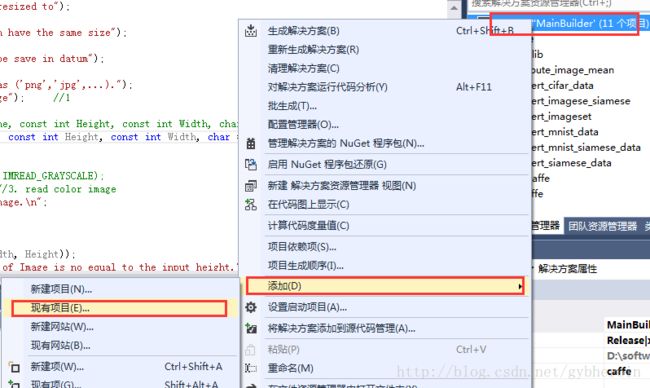
然后打开convert_mnist_siamese_data,把里面原有的cpp文件移除,把caffe-windows-master\examples\siamese\convert_mnist_siamese_data.cpp文件添加进来:

剩下的步骤就是生成了。。。。
成功生成之后,在caffe-windows-master\examples\mnist\下会有convert_mnist_siamese_data.exe文件,这个文件就是我们需要的文件。
在data文件夹下新建一个mnist_new文件夹,把下载好的数据文件和convert_mnist_siamese_data.exe文件都复制过来,写数据转换脚本文件:

请注意:这里只写了test数据的脚本文件,train数据的脚本文件类似,只需要把相应的文件名替换一下即可。然后会生成两个文件夹,分别是Siamese网络需要的train数据和test数据。

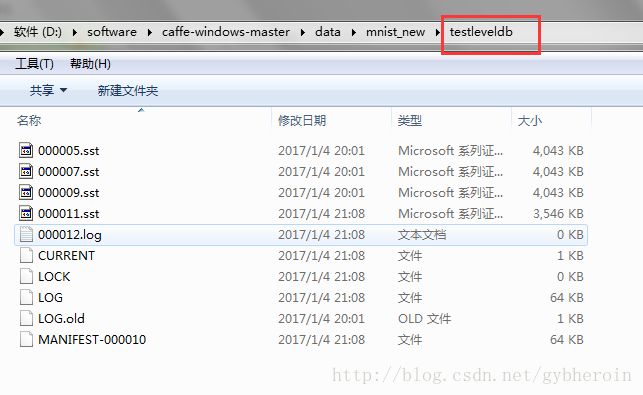
截止目前,数据准备已经完成。。。。。
3、开始训练
在caffe-windows-master\examples\siamese\文件夹下有mnist_siamese_solver.prototxt和mnist_siamese_train_test.prototxt文件,一个是Siamese网络需要的超参文件,具体参数含义在前面的博客中我已经做了大量介绍了,在这里不啰嗦了,一个是Siamese网络结构协议。仔细分析一下Siamese网络,不难发现,其实就是两个LeNet网络。
需要修改网络协议中的哪些地方我也不做介绍了,前面的博客中都做了说明了。
写开始训练的脚本文件:

双击开始训练。。。。以为大工告成了?错!
4、关于损失函数
运行上面的脚本文件,发现:
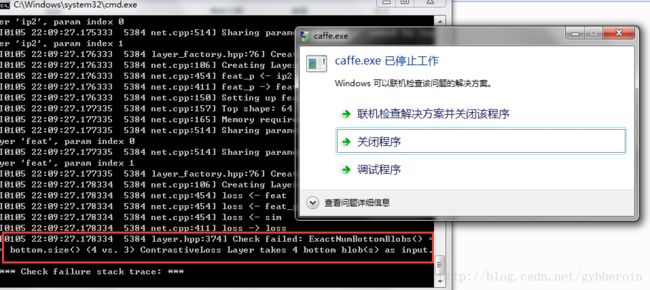
发现ContrastiveLoss损失需要四个输入,但是所有和Siamese网络相关的资料中都是三个输入的,一个输入对,在加上这个输入对是否匹配。难道是协议文件错了?就在这个地方,博主一个人思考人生思考了好长时间,以致于开始怀疑人生,在各种社区、论坛、深度学习群里都问了,可能鉴于博主学术水平太低,没人理,等打开ContrastiveLoss损失函数的代码,研究了半天,终于:
template <typename Dtype>
void ContrastiveLossLayer::LayerSetUp(
const vector::LayerSetUp(bottom, top);
CHECK_EQ(bottom[0]->channels(), bottom[1]->channels());
CHECK_EQ(bottom[0]->height(), 1);
CHECK_EQ(bottom[0]->width(), 1);
CHECK_EQ(bottom[1]->height(), 1);
CHECK_EQ(bottom[1]->width(), 1);
CHECK_EQ(bottom[2]->channels(), 1);
CHECK_EQ(bottom[2]->height(), 1); //第三个参数和第四个参数表示两幅图像的标签
CHECK_EQ(bottom[2]->width(), 1);
CHECK_EQ(bottom[3]->channels(), 1);
CHECK_EQ(bottom[3]->height(), 1);
CHECK_EQ(bottom[3]->width(), 1);
....
for (int i = 0; i < bottom[0]->num(); ++i) {
dist_sq_.mutable_cpu_data()[i] = caffe_cpu_dot(channels,
diff_.cpu_data() + (i*channels), diff_.cpu_data() + (i*channels));
if (static_cast<int>(bottom[2]->cpu_data()[i]) == static_cast<int>(bottom[3]->cpu_data()[i])) { // similar pairs
loss += dist_sq_.cpu_data()[i];
}
else { // dissimilar pairs
loss += std::max(margin - dist_sq_.cpu_data()[i], Dtype(0.0));
}
} 在这个损失函数的源代码中,发现了端倪。改进的ContrastiveLoss就是四个参数,分别是两个输入数据,和两个输入数据对应的标签,通过判断两个标签是否一致,来做损失计算。这下恍然大悟,所以在网络结构的协议损失层,又添加了一个标签。搞定!
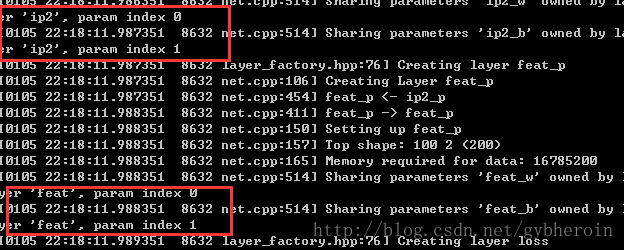
在协议中,会打印出来几个类似于这样的数据,分析了网络协议,发现两个分支层是参数共享的,用了同一个名字,这个地方的含义就是告诉我们,feat_w和feat_b参数共享。
开始训练,有意思吧。。。。。。。